 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Auditing of Differential Privacy in MST and AIM
Apr 20, 2026State-of-the-art Differentially Private (DP) synthetic data generators such as MST and AIM are widely used, yet tightly auditing their privacy guarantees remains challenging. We introduce a Gaussian Differential Privacy (GDP)-based auditing framework that measures privacy via the full false-positive/false-negative tradeoff. Applied to MST and AIM under worst-case settings, our method provides the first tight audits in the strong-privacy regime. For $(ε,δ)=(1,10^{-2})$, we obtain $μ_{emp}\approx0.43$ vs. implied $μ=0.45$, showing a small theory-practice gap. Our code is publicly available: https://github.com/sassoftware/dpmm.
Rethinking Anonymity Claims in Synthetic Data Generation: A Model-Centric Privacy Attack Perspective
Jan 30, 2026Training generative machine learning models to produce synthetic tabular data has become a popular approach for enhancing privacy in data sharing. As this typically involves processing sensitive personal information, releasing either the trained model or generated synthetic datasets can still pose privacy risks. Yet, recent research, commercial deployments, and privacy regulations like the General Data Protection Regulation (GDPR) largely assess anonymity at the level of an individual dataset. In this paper, we rethink anonymity claims about synthetic data from a model-centric perspective and argue that meaningful assessments must account for the capabilities and properties of the underlying generative model and be grounded in state-of-the-art privacy attacks. This perspective better reflects real-world products and deployments, where trained models are often readily accessible for interaction or querying. We interpret the GDPR's definitions of personal data and anonymization under such access assumptions to identify the types of identifiability risks that must be mitigated and map them to privacy attacks across different threat settings. We then argue that synthetic data techniques alone do not ensure sufficient anonymization. Finally, we compare the two mechanisms most commonly used alongside synthetic data -- Differential Privacy (DP) and Similarity-based Privacy Metrics (SBPMs) -- and argue that while DP can offer robust protections against identifiability risks, SBPMs lack adequate safeguards. Overall, our work connects regulatory notions of identifiability with model-centric privacy attacks, enabling more responsible and trustworthy regulatory assessment of synthetic data systems by researchers, practitioners, and policymakers.
The DCR Delusion: Measuring the Privacy Risk of Synthetic Data
May 02, 2025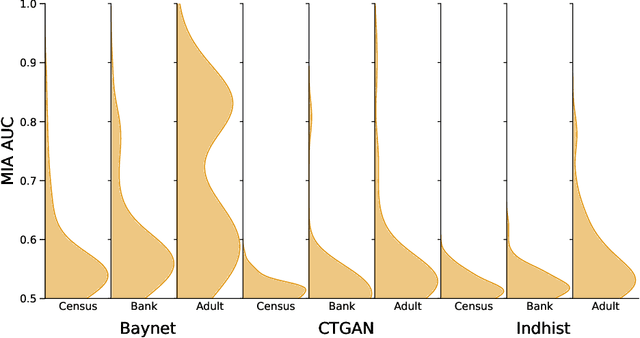

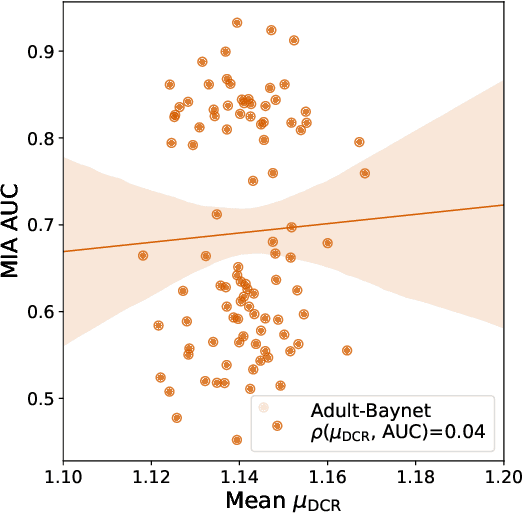
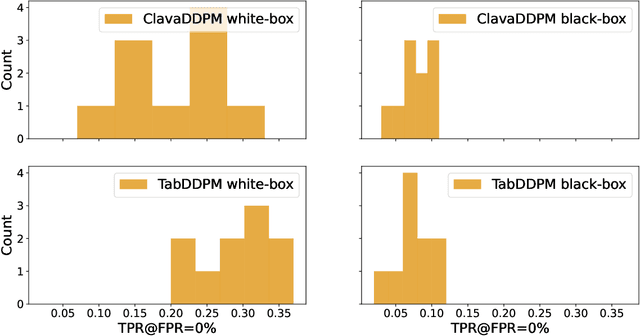
Synthetic data has become an increasingly popular way to share data without revealing sensitive information. Though Membership Inference Attacks (MIAs) are widely considered the gold standard for empirically assessing the privacy of a synthetic dataset, practitioners and researchers often rely on simpler proxy metrics such as Distance to Closest Record (DCR). These metrics estimate privacy by measuring the similarity between the training data and generated synthetic data. This similarity is also compared against that between the training data and a disjoint holdout set of real records to construct a binary privacy test. If the synthetic data is not more similar to the training data than the holdout set is, it passes the test and is considered private. In this work we show that, while computationally inexpensive, DCR and other distance-based metrics fail to identify privacy leakage. Across multiple datasets and both classical models such as Baynet and CTGAN and more recent diffusion models, we show that datasets deemed private by proxy metrics are highly vulnerable to MIAs. We similarly find both the binary privacy test and the continuous measure based on these metrics to be uninformative of actual membership inference risk. We further show that these failures are consistent across different metric hyperparameter settings and record selection methods. Finally, we argue DCR and other distance-based metrics to be flawed by design and show a example of a simple leakage they miss in practice. With this work, we hope to motivate practitioners to move away from proxy metrics to MIAs as the rigorous, comprehensive standard of evaluating privacy of synthetic data, in particular to make claims of datasets being legally anonymous.
Understanding the Impact of Data Domain Extraction on Synthetic Data Privacy
Apr 14, 2025Privacy attacks, particularly membership inference attacks (MIAs), are widely used to assess the privacy of generative models for tabular synthetic data, including those with Differential Privacy (DP) guarantees. These attacks often exploit outliers, which are especially vulnerable due to their position at the boundaries of the data domain (e.g., at the minimum and maximum values). However, the role of data domain extraction in generative models and its impact on privacy attacks have been overlooked. In this paper, we examine three strategies for defining the data domain: assuming it is externally provided (ideally from public data), extracting it directly from the input data, and extracting it with DP mechanisms. While common in popular implementations and libraries, we show that the second approach breaks end-to-end DP guarantees and leaves models vulnerable. While using a provided domain (if representative) is preferable, extracting it with DP can also defend against popular MIAs, even at high privacy budgets.
The Importance of Being Discrete: Measuring the Impact of Discretization in End-to-End Differentially Private Synthetic Data
Apr 09, 2025Differentially Private (DP) generative marginal models are often used in the wild to release synthetic tabular datasets in lieu of sensitive data while providing formal privacy guarantees. These models approximate low-dimensional marginals or query workloads; crucially, they require the training data to be pre-discretized, i.e., continuous values need to first be partitioned into bins. However, as the range of values (or their domain) is often inferred directly from the training data, with the number of bins and bin edges typically defined arbitrarily, this approach can ultimately break end-to-end DP guarantees and may not always yield optimal utility. In this paper, we present an extensive measurement study of four discretization strategies in the context of DP marginal generative models. More precisely, we design DP versions of three discretizers (uniform, quantile, and k-means) and reimplement the PrivTree algorithm. We find that optimizing both the choice of discretizer and bin count can improve utility, on average, by almost 30% across six DP marginal models, compared to the default strategy and number of bins, with PrivTree being the best-performing discretizer in the majority of cases. We demonstrate that, while DP generative models with non-private discretization remain vulnerable to membership inference attacks, applying DP during discretization effectively mitigates this risk. Finally, we propose an optimized approach for automatically selecting the optimal number of bins, achieving high utility while reducing both privacy budget consumption and computational overhead.
Synthetic Data, Similarity-based Privacy Metrics, and Regulatory (Non-)Compliance
Jul 26, 2024

In this paper, we argue that similarity-based privacy metrics cannot ensure regulatory compliance of synthetic data. Our analysis and counter-examples show that they do not protect against singling out and linkability and, among other fundamental issues, completely ignore the motivated intruder test.
The Elusive Pursuit of Replicating PATE-GAN: Benchmarking, Auditing, Debugging
Jun 20, 2024



Synthetic data created by differentially private (DP) generative models is increasingly used in real-world settings. In this context, PATE-GAN has emerged as a popular algorithm, combining Generative Adversarial Networks (GANs) with the private training approach of PATE (Private Aggregation of Teacher Ensembles). In this paper, we analyze and benchmark six open-source PATE-GAN implementations, including three by (a subset of) the original authors. First, we shed light on architecture deviations and empirically demonstrate that none replicate the utility performance reported in the original paper. Then, we present an in-depth privacy evaluation, including DP auditing, showing that all implementations leak more privacy than intended and uncovering 17 privacy violations and 5 other bugs. Our codebase is available from https://github.com/spalabucr/pategan-audit.
On the Inadequacy of Similarity-based Privacy Metrics: Reconstruction Attacks against "Truly Anonymous Synthetic Data''
Dec 08, 2023



Training generative models to produce synthetic data is meant to provide a privacy-friendly approach to data release. However, we get robust guarantees only when models are trained to satisfy Differential Privacy (DP). Alas, this is not the standard in industry as many companies use ad-hoc strategies to empirically evaluate privacy based on the statistical similarity between synthetic and real data. In this paper, we review the privacy metrics offered by leading companies in this space and shed light on a few critical flaws in reasoning about privacy entirely via empirical evaluations. We analyze the undesirable properties of the most popular metrics and filters and demonstrate their unreliability and inconsistency through counter-examples. We then present a reconstruction attack, ReconSyn, which successfully recovers (i.e., leaks all attributes of) at least 78% of the low-density train records (or outliers) with only black-box access to a single fitted generative model and the privacy metrics. Finally, we show that applying DP only to the model or using low-utility generators does not mitigate ReconSyn as the privacy leakage predominantly comes from the metrics. Overall, our work serves as a warning to practitioners not to deviate from established privacy-preserving mechanisms.
On the Challenges of Deploying Privacy-Preserving Synthetic Data in the Enterprise
Jul 09, 2023
Generative AI technologies are gaining unprecedented popularity, causing a mix of excitement and apprehension through their remarkable capabilities. In this paper, we study the challenges associated with deploying synthetic data, a subfield of Generative AI. Our focus centers on enterprise deployment, with an emphasis on privacy concerns caused by the vast amount of personal and highly sensitive data. We identify 40+ challenges and systematize them into five main groups -- i) generation, ii) infrastructure & architecture, iii) governance, iv) compliance & regulation, and v) adoption. Additionally, we discuss a strategic and systematic approach that enterprises can employ to effectively address the challenges and achieve their goals by establishing trust in the implemented solutions.
When Synthetic Data Met Regulation
Jul 01, 2023In this paper, we argue that synthetic data produced by Differentially Private generative models can be sufficiently anonymized and, therefore, anonymous data and regulatory compliant.