 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Data Domain Extraction on Synthetic Data Privacy
Apr 14, 2025Privacy attacks, particularly membership inference attacks (MIAs), are widely used to assess the privacy of generative models for tabular synthetic data, including those with Differential Privacy (DP) guarantees. These attacks often exploit outliers, which are especially vulnerable due to their position at the boundaries of the data domain (e.g., at the minimum and maximum values). However, the role of data domain extraction in generative models and its impact on privacy attacks have been overlooked. In this paper, we examine three strategies for defining the data domain: assuming it is externally provided (ideally from public data), extracting it directly from the input data, and extracting it with DP mechanisms. While common in popular implementations and libraries, we show that the second approach breaks end-to-end DP guarantees and leaves models vulnerable. While using a provided domain (if representative) is preferable, extracting it with DP can also defend against popular MIAs, even at high privacy budgets.
The Importance of Being Discrete: Measuring the Impact of Discretization in End-to-End Differentially Private Synthetic Data
Apr 09, 2025Differentially Private (DP) generative marginal models are often used in the wild to release synthetic tabular datasets in lieu of sensitive data while providing formal privacy guarantees. These models approximate low-dimensional marginals or query workloads; crucially, they require the training data to be pre-discretized, i.e., continuous values need to first be partitioned into bins. However, as the range of values (or their domain) is often inferred directly from the training data, with the number of bins and bin edges typically defined arbitrarily, this approach can ultimately break end-to-end DP guarantees and may not always yield optimal utility. In this paper, we present an extensive measurement study of four discretization strategies in the context of DP marginal generative models. More precisely, we design DP versions of three discretizers (uniform, quantile, and k-means) and reimplement the PrivTree algorithm. We find that optimizing both the choice of discretizer and bin count can improve utility, on average, by almost 30% across six DP marginal models, compared to the default strategy and number of bins, with PrivTree being the best-performing discretizer in the majority of cases. We demonstrate that, while DP generative models with non-private discretization remain vulnerable to membership inference attacks, applying DP during discretization effectively mitigates this risk. Finally, we propose an optimized approach for automatically selecting the optimal number of bins, achieving high utility while reducing both privacy budget consumption and computational overhead.
dpart: Differentially Private Autoregressive Tabular, a General Framework for Synthetic Data Generation
Jul 12, 2022
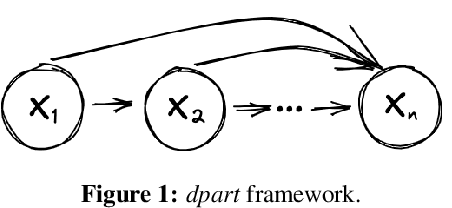


We propose a general, flexible, and scalable framework dpart, an open source Python library for differentially private synthetic data generation. Central to the approach is autoregressive modelling -- breaking the joint data distribution to a sequence of lower-dimensional conditional distributions, captured by various methods such as machine learning models (logistic/linear regression, decision trees, etc.), simple histogram counts, or custom techniques. The library has been created with a view to serve as a quick and accessible baseline as well as to accommodate a wide audience of users, from those making their first steps in synthetic data generation, to more experienced ones with domain expertise who can configure different aspects of the modelling and contribute new methods/mechanisms. Specific instances of dpart include Independent, an optimized version of PrivBayes, and a newly proposed model, dp-synthpop. Code: https://github.com/hazy/dpart