 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Anonymity Claims in Synthetic Data Generation: A Model-Centric Privacy Attack Perspective
Jan 30, 2026Training generative machine learning models to produce synthetic tabular data has become a popular approach for enhancing privacy in data sharing. As this typically involves processing sensitive personal information, releasing either the trained model or generated synthetic datasets can still pose privacy risks. Yet, recent research, commercial deployments, and privacy regulations like the General Data Protection Regulation (GDPR) largely assess anonymity at the level of an individual dataset. In this paper, we rethink anonymity claims about synthetic data from a model-centric perspective and argue that meaningful assessments must account for the capabilities and properties of the underlying generative model and be grounded in state-of-the-art privacy attacks. This perspective better reflects real-world products and deployments, where trained models are often readily accessible for interaction or querying. We interpret the GDPR's definitions of personal data and anonymization under such access assumptions to identify the types of identifiability risks that must be mitigated and map them to privacy attacks across different threat settings. We then argue that synthetic data techniques alone do not ensure sufficient anonymization. Finally, we compare the two mechanisms most commonly used alongside synthetic data -- Differential Privacy (DP) and Similarity-based Privacy Metrics (SBPMs) -- and argue that while DP can offer robust protections against identifiability risks, SBPMs lack adequate safeguards. Overall, our work connects regulatory notions of identifiability with model-centric privacy attacks, enabling more responsible and trustworthy regulatory assessment of synthetic data systems by researchers, practitioners, and policymakers.
Understanding the Impact of Data Domain Extraction on Synthetic Data Privacy
Apr 14, 2025Privacy attacks, particularly membership inference attacks (MIAs), are widely used to assess the privacy of generative models for tabular synthetic data, including those with Differential Privacy (DP) guarantees. These attacks often exploit outliers, which are especially vulnerable due to their position at the boundaries of the data domain (e.g., at the minimum and maximum values). However, the role of data domain extraction in generative models and its impact on privacy attacks have been overlooked. In this paper, we examine three strategies for defining the data domain: assuming it is externally provided (ideally from public data), extracting it directly from the input data, and extracting it with DP mechanisms. While common in popular implementations and libraries, we show that the second approach breaks end-to-end DP guarantees and leaves models vulnerable. While using a provided domain (if representative) is preferable, extracting it with DP can also defend against popular MIAs, even at high privacy budgets.
The Importance of Being Discrete: Measuring the Impact of Discretization in End-to-End Differentially Private Synthetic Data
Apr 09, 2025Differentially Private (DP) generative marginal models are often used in the wild to release synthetic tabular datasets in lieu of sensitive data while providing formal privacy guarantees. These models approximate low-dimensional marginals or query workloads; crucially, they require the training data to be pre-discretized, i.e., continuous values need to first be partitioned into bins. However, as the range of values (or their domain) is often inferred directly from the training data, with the number of bins and bin edges typically defined arbitrarily, this approach can ultimately break end-to-end DP guarantees and may not always yield optimal utility. In this paper, we present an extensive measurement study of four discretization strategies in the context of DP marginal generative models. More precisely, we design DP versions of three discretizers (uniform, quantile, and k-means) and reimplement the PrivTree algorithm. We find that optimizing both the choice of discretizer and bin count can improve utility, on average, by almost 30% across six DP marginal models, compared to the default strategy and number of bins, with PrivTree being the best-performing discretizer in the majority of cases. We demonstrate that, while DP generative models with non-private discretization remain vulnerable to membership inference attacks, applying DP during discretization effectively mitigates this risk. Finally, we propose an optimized approach for automatically selecting the optimal number of bins, achieving high utility while reducing both privacy budget consumption and computational overhead.
To Shuffle or not to Shuffle: Auditing DP-SGD with Shuffling
Nov 15, 2024Differentially Private Stochastic Gradient Descent (DP-SGD) is a popular method for training machine learning models with formal Differential Privacy (DP) guarantees. As DP-SGD processes the training data in batches, it uses Poisson sub-sampling to select batches at each step. However, due to computational and compatibility benefits, replacing sub-sampling with shuffling has become common practice. Yet, since tight theoretical guarantees for shuffling are currently unknown, prior work using shuffling reports DP guarantees as though Poisson sub-sampling was used. This prompts the need to verify whether this discrepancy is reflected in a gap between the theoretical guarantees from state-of-the-art models and the actual privacy leakage. To do so, we introduce a novel DP auditing procedure to analyze DP-SGD with shuffling. We show that state-of-the-art DP models trained with shuffling appreciably overestimated privacy guarantees (up to 4x). In the process, we assess the impact of several parameters, such as batch size, privacy budget, and threat model, on privacy leakage. Finally, we study two variations of the shuffling procedure found in the wild, which result in further privacy leakage. Overall, our work empirically attests to the risk of using shuffling instead of Poisson sub-sampling vis-\`a-vis the actual privacy leakage of DP-SGD.
The Elusive Pursuit of Replicating PATE-GAN: Benchmarking, Auditing, Debugging
Jun 20, 2024



Synthetic data created by differentially private (DP) generative models is increasingly used in real-world settings. In this context, PATE-GAN has emerged as a popular algorithm, combining Generative Adversarial Networks (GANs) with the private training approach of PATE (Private Aggregation of Teacher Ensembles). In this paper, we analyze and benchmark six open-source PATE-GAN implementations, including three by (a subset of) the original authors. First, we shed light on architecture deviations and empirically demonstrate that none replicate the utility performance reported in the original paper. Then, we present an in-depth privacy evaluation, including DP auditing, showing that all implementations leak more privacy than intended and uncovering 17 privacy violations and 5 other bugs. Our codebase is available from https://github.com/spalabucr/pategan-audit.
A Systematic Review of Federated Generative Models
May 26, 2024



Federated Learning (FL) has emerged as a solution for distributed systems that allow clients to train models on their data and only share models instead of local data. Generative Models are designed to learn the distribution of a dataset and generate new data samples that are similar to the original data. Many prior works have tried proposing Federated Generative Models. Using Federated Learning and Generative Models together can be susceptible to attacks, and designing the optimal architecture remains challenging. This survey covers the growing interest in the intersection of FL and Generative Models by comprehensively reviewing research conducted from 2019 to 2024. We systematically compare nearly 100 papers, focusing on their FL and Generative Model methods and privacy considerations. To make this field more accessible to newcomers, we highlight the state-of-the-art advancements and identify unresolved challenges, offering insights for future research in this evolving field.
Nearly Tight Black-Box Auditing of Differentially Private Machine Learning
May 23, 2024



This paper presents a nearly tight audit of the Differentially Private Stochastic Gradient Descent (DP-SGD) algorithm in the black-box model. Our auditing procedure empirically estimates the privacy leakage from DP-SGD using membership inference attacks; unlike prior work, the estimates are appreciably close to the theoretical DP bounds. The main intuition is to craft worst-case initial model parameters, as DP-SGD's privacy analysis is agnostic to the choice of the initial model parameters. For models trained with theoretical $\varepsilon=10.0$ on MNIST and CIFAR-10, our auditing procedure yields empirical estimates of $7.21$ and $6.95$, respectively, on 1,000-record samples and $6.48$ and $4.96$ on the full datasets. By contrast, previous work achieved tight audits only in stronger (i.e., less realistic) white-box models that allow the adversary to access the model's inner parameters and insert arbitrary gradients. Our auditing procedure can be used to detect bugs and DP violations more easily and offers valuable insight into how the privacy analysis of DP-SGD can be further improved.
iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
May 16, 2024
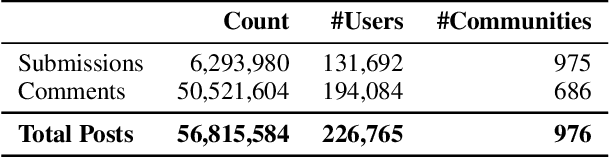
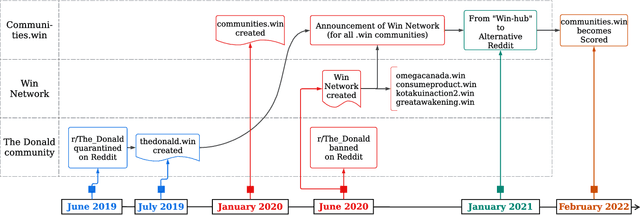

Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.
On the Inadequacy of Similarity-based Privacy Metrics: Reconstruction Attacks against "Truly Anonymous Synthetic Data''
Dec 08, 2023



Training generative models to produce synthetic data is meant to provide a privacy-friendly approach to data release. However, we get robust guarantees only when models are trained to satisfy Differential Privacy (DP). Alas, this is not the standard in industry as many companies use ad-hoc strategies to empirically evaluate privacy based on the statistical similarity between synthetic and real data. In this paper, we review the privacy metrics offered by leading companies in this space and shed light on a few critical flaws in reasoning about privacy entirely via empirical evaluations. We analyze the undesirable properties of the most popular metrics and filters and demonstrate their unreliability and inconsistency through counter-examples. We then present a reconstruction attack, ReconSyn, which successfully recovers (i.e., leaks all attributes of) at least 78% of the low-density train records (or outliers) with only black-box access to a single fitted generative model and the privacy metrics. Finally, we show that applying DP only to the model or using low-utility generators does not mitigate ReconSyn as the privacy leakage predominantly comes from the metrics. Overall, our work serves as a warning to practitioners not to deviate from established privacy-preserving mechanisms.
Understanding how Differentially Private Generative Models Spend their Privacy Budget
May 18, 2023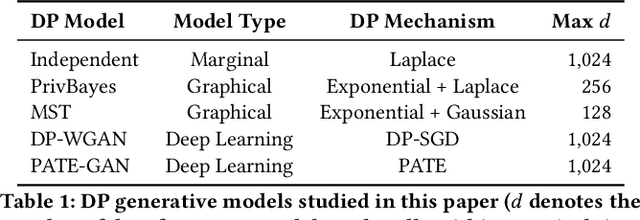
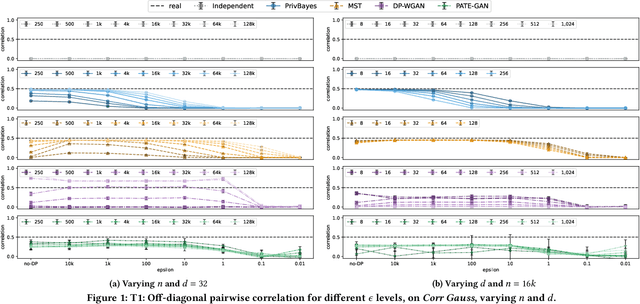
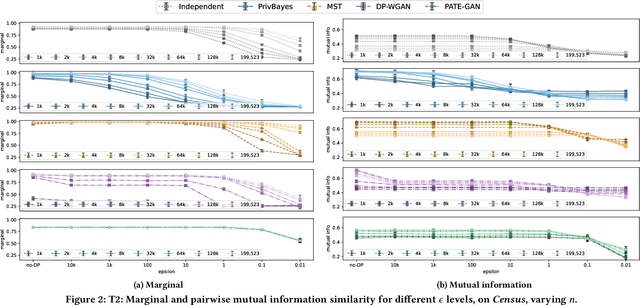
Generative models trained with Differential Privacy (DP) are increasingly used to produce synthetic data while reducing privacy risks. Navigating their specific privacy-utility tradeoffs makes it challenging to determine which models would work best for specific settings/tasks. In this paper, we fill this gap in the context of tabular data by analyzing how DP generative models distribute privacy budgets across rows and columns, arguably the main source of utility degradation. We examine the main factors contributing to how privacy budgets are spent, including underlying modeling techniques, DP mechanisms, and data dimensionality. Our extensive evaluation of both graphical and deep generative models sheds light on the distinctive features that render them suitable for different settings and tasks. We show that graphical models distribute the privacy budget horizontally and thus cannot handle relatively wide datasets while the performance on the task they were optimized for monotonically increases with more data. Deep generative models spend their budget per iteration, so their behavior is less predictable with varying dataset dimensions but could perform better if trained on more features. Also, low levels of privacy ($\epsilon\geq100$) could help some models generalize, achieving better results than without applying DP.