 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupercharging Federated Intelligence Retrieval
Mar 26, 2026RAG typically assumes centralized access to documents, which breaks down when knowledge is distributed across private data silos. We propose a secure Federated RAG system built using Flower that performs local silo retrieval, while server-side aggregation and text generation run inside an attested, confidential compute environment, enabling confidential remote LLM inference even in the presence of honest-but-curious or compromised servers. We also propose a cascading inference approach that incorporates a non-confidential third-party model (e.g., Amazon Nova) as auxiliary context without weakening confidentiality.
Starlit: Privacy-Preserving Federated Learning to Enhance Financial Fraud Detection
Jan 22, 2024Federated Learning (FL) is a data-minimization approach enabling collaborative model training across diverse clients with local data, avoiding direct data exchange. However, state-of-the-art FL solutions to identify fraudulent financial transactions exhibit a subset of the following limitations. They (1) lack a formal security definition and proof, (2) assume prior freezing of suspicious customers' accounts by financial institutions (limiting the solutions' adoption), (3) scale poorly, involving either $O(n^2)$ computationally expensive modular exponentiation (where $n$ is the total number of financial institutions) or highly inefficient fully homomorphic encryption, (4) assume the parties have already completed the identity alignment phase, hence excluding it from the implementation, performance evaluation, and security analysis, and (5) struggle to resist clients' dropouts. This work introduces Starlit, a novel scalable privacy-preserving FL mechanism that overcomes these limitations. It has various applications, such as enhancing financial fraud detection, mitigating terrorism, and enhancing digital health. We implemented Starlit and conducted a thorough performance analysis using synthetic data from a key player in global financial transactions. The evaluation indicates Starlit's scalability, efficiency, and accuracy.
BadVFL: Backdoor Attacks in Vertical Federated Learning
Apr 18, 2023



Federated learning (FL) enables multiple parties to collaboratively train a machine learning model without sharing their data; rather, they train their own model locally and send updates to a central server for aggregation. Depending on how the data is distributed among the participants, FL can be classified into Horizontal (HFL) and Vertical (VFL). In VFL, the participants share the same set of training instances but only host a different and non-overlapping subset of the whole feature space. Whereas in HFL, each participant shares the same set of features while the training set is split into locally owned training data subsets. VFL is increasingly used in applications like financial fraud detection; nonetheless, very little work has analyzed its security. In this paper, we focus on robustness in VFL, in particular, on backdoor attacks, whereby an adversary attempts to manipulate the aggregate model during the training process to trigger misclassifications. Performing backdoor attacks in VFL is more challenging than in HFL, as the adversary i) does not have access to the labels during training and ii) cannot change the labels as she only has access to the feature embeddings. We present a first-of-its-kind clean-label backdoor attack in VFL, which consists of two phases: a label inference and a backdoor phase. We demonstrate the effectiveness of the attack on three different datasets, investigate the factors involved in its success, and discuss countermeasures to mitigate its impact.
Cerberus: Exploring Federated Prediction of Security Events
Sep 07, 2022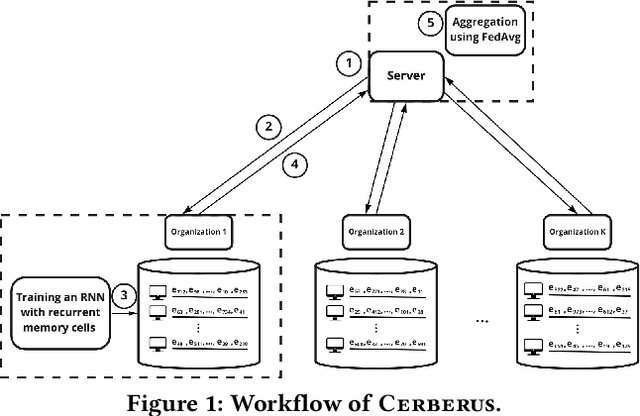
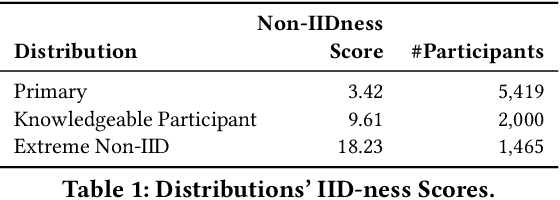
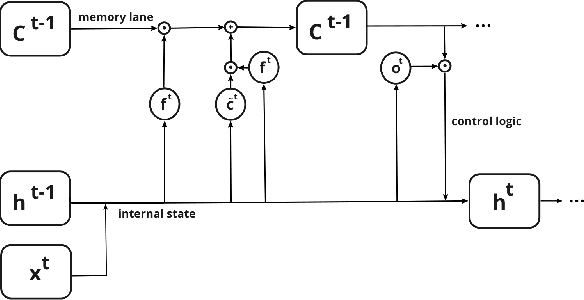
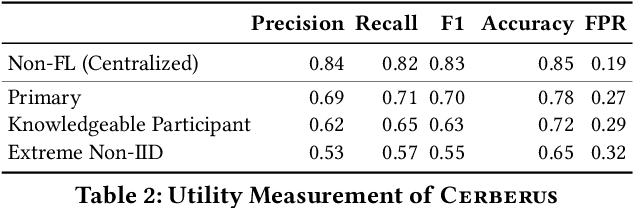
Modern defenses against cyberattacks increasingly rely on proactive approaches, e.g., to predict the adversary's next actions based on past events. Building accurate prediction models requires knowledge from many organizations; alas, this entails disclosing sensitive information, such as network structures, security postures, and policies, which might often be undesirable or outright impossible. In this paper, we explore the feasibility of using Federated Learning (FL) to predict future security events. To this end, we introduce Cerberus, a system enabling collaborative training of Recurrent Neural Network (RNN) models for participating organizations. The intuition is that FL could potentially offer a middle-ground between the non-private approach where the training data is pooled at a central server and the low-utility alternative of only training local models. We instantiate Cerberus on a dataset obtained from a major security company's intrusion prevention product and evaluate it vis-a-vis utility, robustness, and privacy, as well as how participants contribute to and benefit from the system. Overall, our work sheds light on both the positive aspects and the challenges of using FL for this task and paves the way for deploying federated approaches to predictive security.
Bayesian Estimation of Differential Privacy
Jun 15, 2022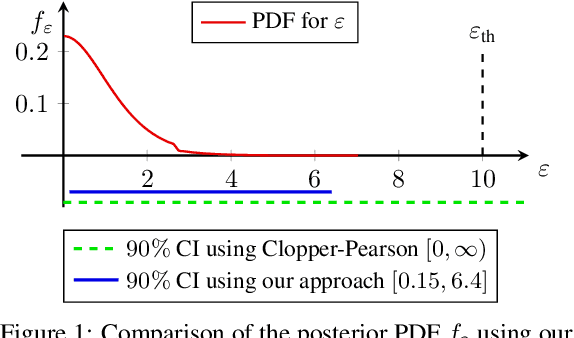

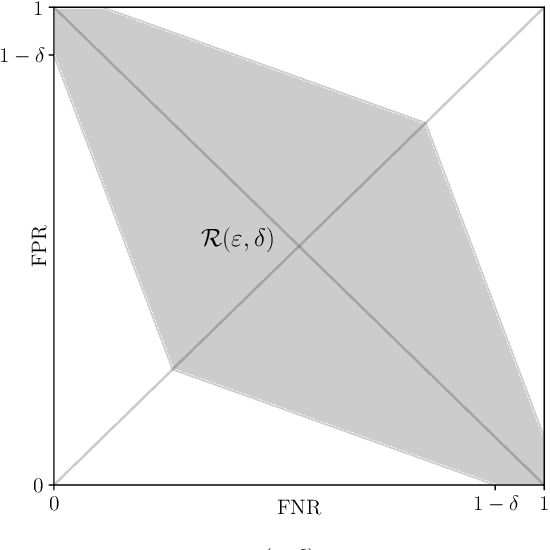
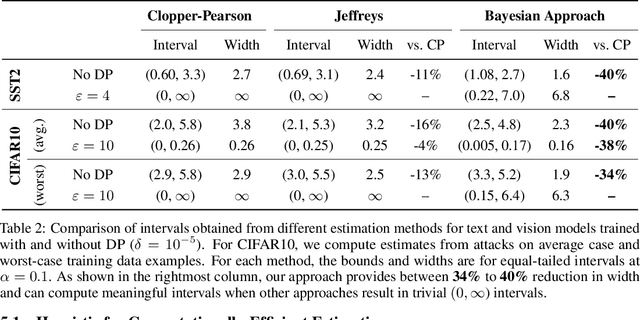
Algorithms such as Differentially Private SGD enable training machine learning models with formal privacy guarantees. However, there is a discrepancy between the protection that such algorithms guarantee in theory and the protection they afford in practice. An emerging strand of work empirically estimates the protection afforded by differentially private training as a confidence interval for the privacy budget $\varepsilon$ spent on training a model. Existing approaches derive confidence intervals for $\varepsilon$ from confidence intervals for the false positive and false negative rates of membership inference attacks. Unfortunately, obtaining narrow high-confidence intervals for $\epsilon$ using this method requires an impractically large sample size and training as many models as samples. We propose a novel Bayesian method that greatly reduces sample size, and adapt and validate a heuristic to draw more than one sample per trained model. Our Bayesian method exploits the hypothesis testing interpretation of differential privacy to obtain a posterior for $\varepsilon$ (not just a confidence interval) from the joint posterior of the false positive and false negative rates of membership inference attacks. For the same sample size and confidence, we derive confidence intervals for $\varepsilon$ around 40% narrower than prior work. The heuristic, which we adapt from label-only DP, can be used to further reduce the number of trained models needed to get enough samples by up to 2 orders of magnitude.
Toward Robustness and Privacy in Federated Learning: Experimenting with Local and Central Differential Privacy
Sep 08, 2020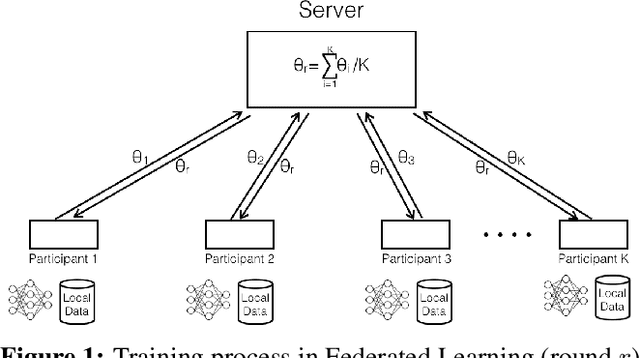


Federated Learning (FL) allows multiple participants to collaboratively train machine learning models by keeping their datasets local and exchanging model updates. Recent work has highlighted weaknesses related to robustness and privacy in FL, including backdoor, membership and property inference attacks. In this paper, we investigate whether and how Differential Privacy (DP) can be used to defend against attacks targeting both robustness and privacy in FL. To this end, we present a first-of-its-kind experimental evaluation of Local and Central Differential Privacy (LDP/CDP), assessing their feasibility and effectiveness. We show that both LDP and CDP do defend against backdoor attacks, with varying levels of protection and utility, and overall more effectively than non-DP defenses. They also mitigate white-box membership inference attacks, which our work is the first to show. Neither, however, defend against property inference attacks, prompting the need for further research in this space. Overall, our work also provides a re-usable measurement framework to quantify the trade-offs between robustness/privacy and utility in differentially private FL.