 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarlit: Privacy-Preserving Federated Learning to Enhance Financial Fraud Detection
Jan 22, 2024Federated Learning (FL) is a data-minimization approach enabling collaborative model training across diverse clients with local data, avoiding direct data exchange. However, state-of-the-art FL solutions to identify fraudulent financial transactions exhibit a subset of the following limitations. They (1) lack a formal security definition and proof, (2) assume prior freezing of suspicious customers' accounts by financial institutions (limiting the solutions' adoption), (3) scale poorly, involving either $O(n^2)$ computationally expensive modular exponentiation (where $n$ is the total number of financial institutions) or highly inefficient fully homomorphic encryption, (4) assume the parties have already completed the identity alignment phase, hence excluding it from the implementation, performance evaluation, and security analysis, and (5) struggle to resist clients' dropouts. This work introduces Starlit, a novel scalable privacy-preserving FL mechanism that overcomes these limitations. It has various applications, such as enhancing financial fraud detection, mitigating terrorism, and enhancing digital health. We implemented Starlit and conducted a thorough performance analysis using synthetic data from a key player in global financial transactions. The evaluation indicates Starlit's scalability, efficiency, and accuracy.
Enhanced Membership Inference Attacks against Machine Learning Models
Nov 18, 2021
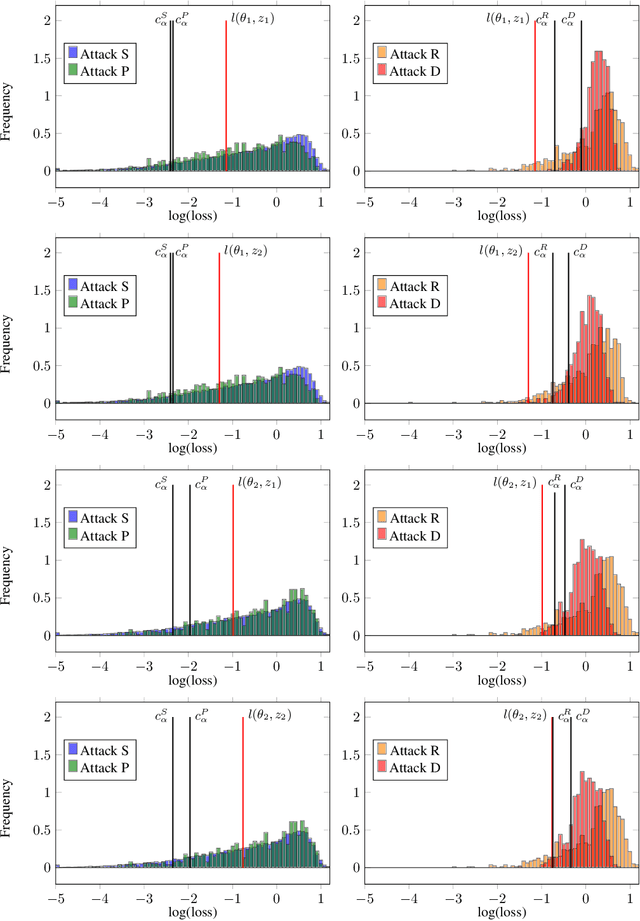
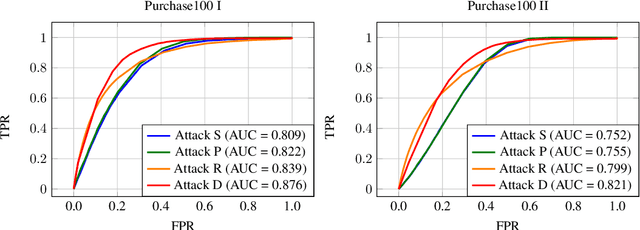

How much does a given trained model leak about each individual data record in its training set? Membership inference attacks are used as an auditing tool to quantify the private information that a model leaks about the individual data points in its training set. Membership inference attacks are influenced by different uncertainties that an attacker has to resolve about training data, the training algorithm, and the underlying data distribution. Thus attack success rates, of many attacks in the literature, do not precisely capture the information leakage of models about their data, as they also reflect other uncertainties that the attack algorithm has. In this paper, we explain the implicit assumptions and also the simplifications made in prior work using the framework of hypothesis testing. We also derive new attack algorithms from the framework that can achieve a high AUC score while also highlighting the different factors that affect their performance. Our algorithms capture a very precise approximation of privacy loss in models, and can be used as a tool to perform an accurate and informed estimation of privacy risk in machine learning models. We provide a thorough empirical evaluation of our attack strategies on various machine learning tasks and benchmark datasets.
ML Privacy Meter: Aiding Regulatory Compliance by Quantifying the Privacy Risks of Machine Learning
Jul 18, 2020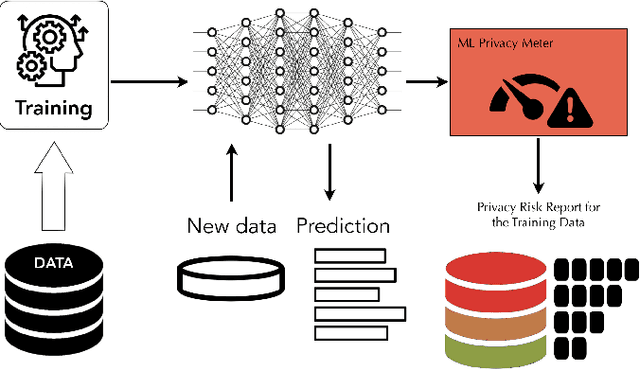
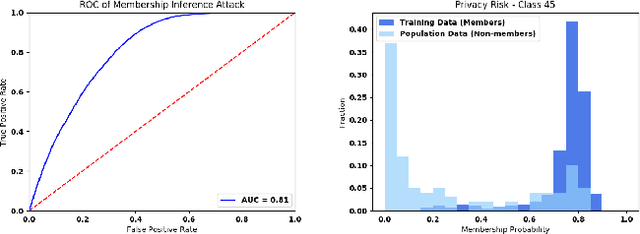
When building machine learning models using sensitive data, organizations should ensure that the data processed in such systems is adequately protected. For projects involving machine learning on personal data, Article 35 of the GDPR mandates it to perform a Data Protection Impact Assessment (DPIA). In addition to the threats of illegitimate access to data through security breaches, machine learning models pose an additional privacy risk to the data by indirectly revealing about it through the model predictions and parameters. Guidances released by the Information Commissioner's Office (UK) and the National Institute of Standards and Technology (US) emphasize on the threat to data from models and recommend organizations to account for and estimate these risks to comply with data protection regulations. Hence, there is an immediate need for a tool that can quantify the privacy risk to data from models. In this paper, we focus on this indirect leakage about training data from machine learning models. We present ML Privacy Meter, a tool that can quantify the privacy risk to data from models through state of the art membership inference attack techniques. We discuss how this tool can help practitioners in compliance with data protection regulations, when deploying machine learning models.
On Adversarial Bias and the Robustness of Fair Machine Learning
Jun 15, 2020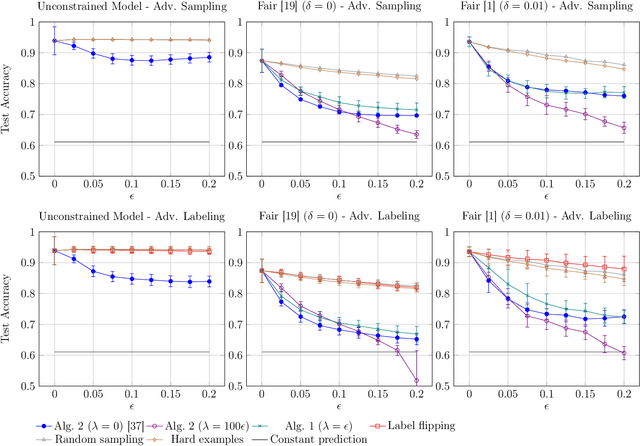
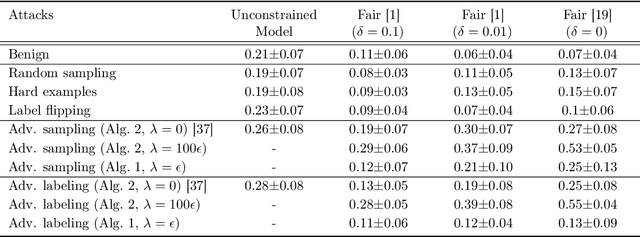
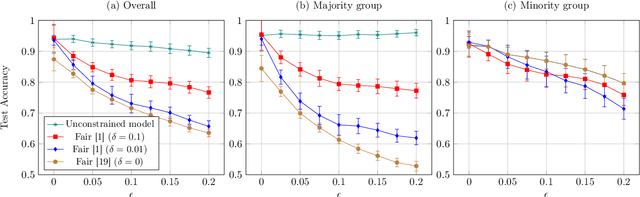
Optimizing prediction accuracy can come at the expense of fairness. Towards minimizing discrimination against a group, fair machine learning algorithms strive to equalize the behavior of a model across different groups, by imposing a fairness constraint on models. However, we show that giving the same importance to groups of different sizes and distributions, to counteract the effect of bias in training data, can be in conflict with robustness. We analyze data poisoning attacks against group-based fair machine learning, with the focus on equalized odds. An adversary who can control sampling or labeling for a fraction of training data, can reduce the test accuracy significantly beyond what he can achieve on unconstrained models. Adversarial sampling and adversarial labeling attacks can also worsen the model's fairness gap on test data, even though the model satisfies the fairness constraint on training data. We analyze the robustness of fair machine learning through an empirical evaluation of attacks on multiple algorithms and benchmark datasets.
Ultimate Power of Inference Attacks: Privacy Risks of High-Dimensional Models
May 29, 2019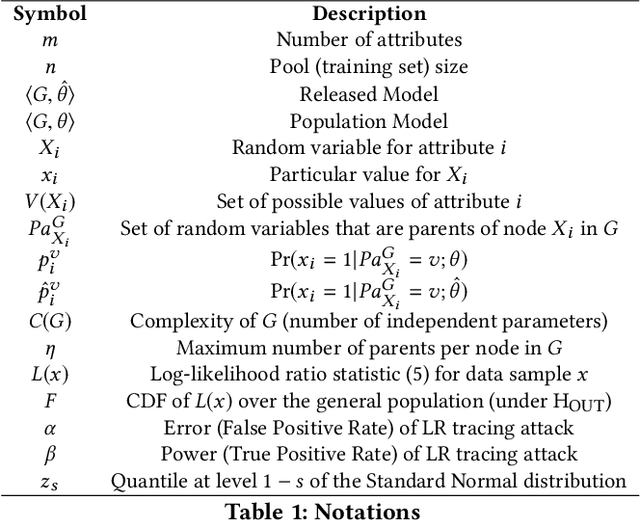
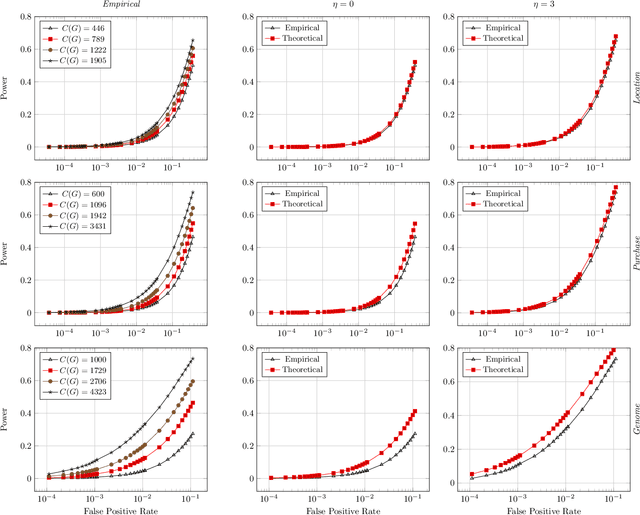
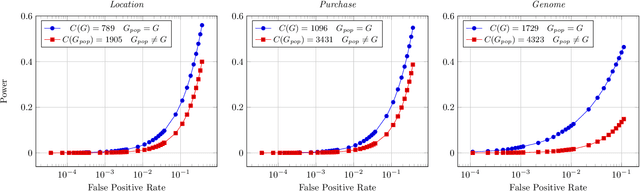
Models leak information about their training data. This enables attackers to infer sensitive information about their training sets, notably determine if a data sample was part of the model's training set. The existing works empirically show the possibility of these tracing (membership inference) attacks against complex models with a large number of parameters. However, the attack results are dependent on the specific training data, can be obtained only after the tedious process of training the model and performing the attack, and are missing any measure of the confidence and unused potential power of the attack. A model designer is interested in identifying which model structures leak more information, how adding new parameters to the model increases its privacy risk, and what is the gain of adding new data points to decrease the overall information leakage. The privacy analysis should also enable designing the most powerful inference attack. In this paper, we design a theoretical framework to analyze the maximum power of tracing attacks against high-dimensional models, with the focus on probabilistic graphical models. We provide a tight upper-bound on the power (true positive rate) of these attacks, with respect to their error (false positive rate). The bound, as it should be, is independent of the knowledge and algorithm of any specific attack, as well as the values of particular samples in the training set. It provides a measure of the potential leakage of a model given its structure, as a function of the structure complexity and the size of training set.