 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Adversarial Bias and the Robustness of Fair Machine Learning
Paper and Code
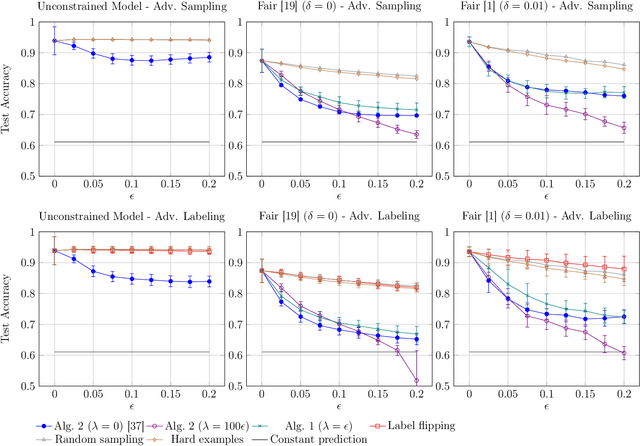
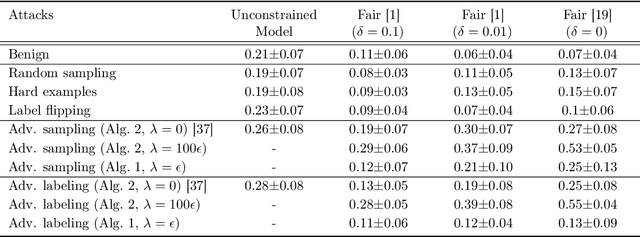
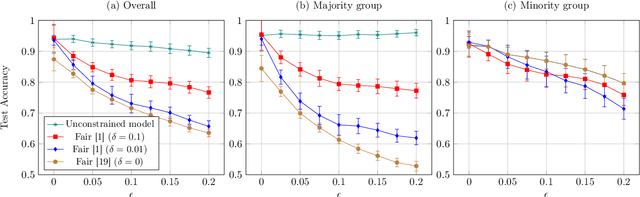
Optimizing prediction accuracy can come at the expense of fairness. Towards minimizing discrimination against a group, fair machine learning algorithms strive to equalize the behavior of a model across different groups, by imposing a fairness constraint on models. However, we show that giving the same importance to groups of different sizes and distributions, to counteract the effect of bias in training data, can be in conflict with robustness. We analyze data poisoning attacks against group-based fair machine learning, with the focus on equalized odds. An adversary who can control sampling or labeling for a fraction of training data, can reduce the test accuracy significantly beyond what he can achieve on unconstrained models. Adversarial sampling and adversarial labeling attacks can also worsen the model's fairness gap on test data, even though the model satisfies the fairness constraint on training data. We analyze the robustness of fair machine learning through an empirical evaluation of attacks on multiple algorithms and benchmark datasets.