 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSeal: A Localized LLM Watermark for Provenance & Distillation Protection
May 12, 2026We introduce TextSeal, a state-of-the-art watermark for large language models. Building on Gumbel-max sampling, TextSeal introduces dual-key generation to restore output diversity, along with entropy-weighted scoring and multi-region localization for improved detection. It supports serving optimizations such as speculative decoding and multi-token prediction, and does not add any inference overhead. TextSeal strictly dominates baselines like SynthID-text in detection strength and is robust to dilution, maintaining confident localized detection even in heavily mixed human/AI documents. The scheme is theoretically distortion-free, and evaluation across reasoning benchmarks confirms that it preserves downstream performance; while a multilingual human evaluation (6000 A/B comparisons, 5 languages) shows no perceptible quality difference. Beyond its use for provenance detection, TextSeal is also ``radioactive'': its watermark signal transfers through model distillation, enabling detection of unauthorized use.
Overcoming the Retrieval Barrier: Indirect Prompt Injection in the Wild for LLM Systems
Jan 11, 2026Large language models (LLMs) increasingly rely on retrieving information from external corpora. This creates a new attack surface: indirect prompt injection (IPI), where hidden instructions are planted in the corpora and hijack model behavior once retrieved. Previous studies have highlighted this risk but often avoid the hardest step: ensuring that malicious content is actually retrieved. In practice, unoptimized IPI is rarely retrieved under natural queries, which leaves its real-world impact unclear. We address this challenge by decomposing the malicious content into a trigger fragment that guarantees retrieval and an attack fragment that encodes arbitrary attack objectives. Based on this idea, we design an efficient and effective black-box attack algorithm that constructs a compact trigger fragment to guarantee retrieval for any attack fragment. Our attack requires only API access to embedding models, is cost-efficient (as little as $0.21 per target user query on OpenAI's embedding models), and achieves near-100% retrieval across 11 benchmarks and 8 embedding models (including both open-source models and proprietary services). Based on this attack, we present the first end-to-end IPI exploits under natural queries and realistic external corpora, spanning both RAG and agentic systems with diverse attack objectives. These results establish IPI as a practical and severe threat: when a user issued a natural query to summarize emails on frequently asked topics, a single poisoned email was sufficient to coerce GPT-4o into exfiltrating SSH keys with over 80% success in a multi-agent workflow. We further evaluate several defenses and find that they are insufficient to prevent the retrieval of malicious text, highlighting retrieval as a critical open vulnerability.
How Good is Post-Hoc Watermarking With Language Model Rephrasing?
Dec 18, 2025Generation-time text watermarking embeds statistical signals into text for traceability of AI-generated content. We explore *post-hoc watermarking* where an LLM rewrites existing text while applying generation-time watermarking, to protect copyrighted documents, or detect their use in training or RAG via watermark radioactivity. Unlike generation-time approaches, which is constrained by how LLMs are served, this setting offers additional degrees of freedom for both generation and detection. We investigate how allocating compute (through larger rephrasing models, beam search, multi-candidate generation, or entropy filtering at detection) affects the quality-detectability trade-off. Our strategies achieve strong detectability and semantic fidelity on open-ended text such as books. Among our findings, the simple Gumbel-max scheme surprisingly outperforms more recent alternatives under nucleus sampling, and most methods benefit significantly from beam search. However, most approaches struggle when watermarking verifiable text such as code, where we counterintuitively find that smaller models outperform larger ones. This study reveals both the potential and limitations of post-hoc watermarking, laying groundwork for practical applications and future research.
Watermark Smoothing Attacks against Language Models
Jul 19, 2024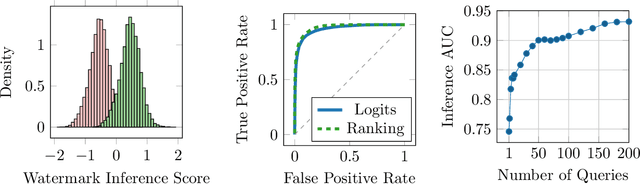

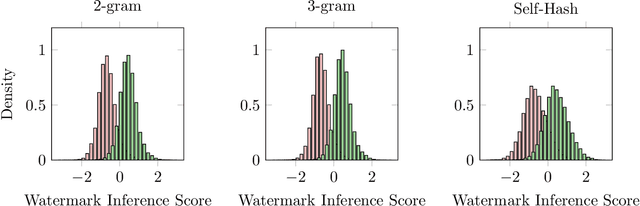

Watermarking is a technique used to embed a hidden signal in the probability distribution of text generated by large language models (LLMs), enabling attribution of the text to the originating model. We introduce smoothing attacks and show that existing watermarking methods are not robust against minor modifications of text. An adversary can use weaker language models to smooth out the distribution perturbations caused by watermarks without significantly compromising the quality of the generated text. The modified text resulting from the smoothing attack remains close to the distribution of text that the original model (without watermark) would have produced. Our attack reveals a fundamental limitation of a wide range of watermarking techniques.
Bias Propagation in Federated Learning
Sep 05, 2023We show that participating in federated learning can be detrimental to group fairness. In fact, the bias of a few parties against under-represented groups (identified by sensitive attributes such as gender or race) can propagate through the network to all the parties in the network. We analyze and explain bias propagation in federated learning on naturally partitioned real-world datasets. Our analysis reveals that biased parties unintentionally yet stealthily encode their bias in a small number of model parameters, and throughout the training, they steadily increase the dependence of the global model on sensitive attributes. What is important to highlight is that the experienced bias in federated learning is higher than what parties would otherwise encounter in centralized training with a model trained on the union of all their data. This indicates that the bias is due to the algorithm. Our work calls for auditing group fairness in federated learning and designing learning algorithms that are robust to bias propagation.
On The Impact of Machine Learning Randomness on Group Fairness
Jul 09, 2023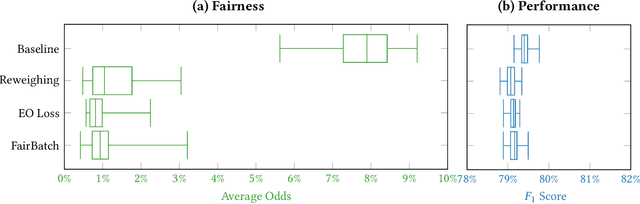
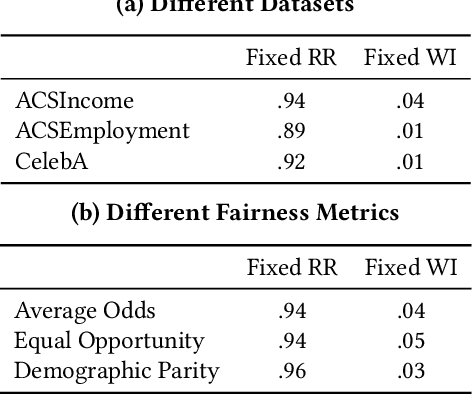
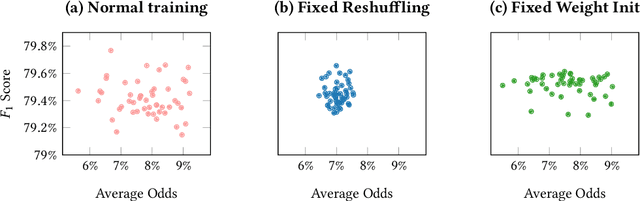
Statistical measures for group fairness in machine learning reflect the gap in performance of algorithms across different groups. These measures, however, exhibit a high variance between different training instances, which makes them unreliable for empirical evaluation of fairness. What causes this high variance? We investigate the impact on group fairness of different sources of randomness in training neural networks. We show that the variance in group fairness measures is rooted in the high volatility of the learning process on under-represented groups. Further, we recognize the dominant source of randomness as the stochasticity of data order during training. Based on these findings, we show how one can control group-level accuracy (i.e., model fairness), with high efficiency and negligible impact on the model's overall performance, by simply changing the data order for a single epoch.
On the Privacy Risks of Algorithmic Fairness
Nov 07, 2020
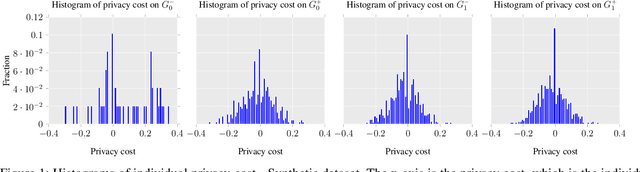

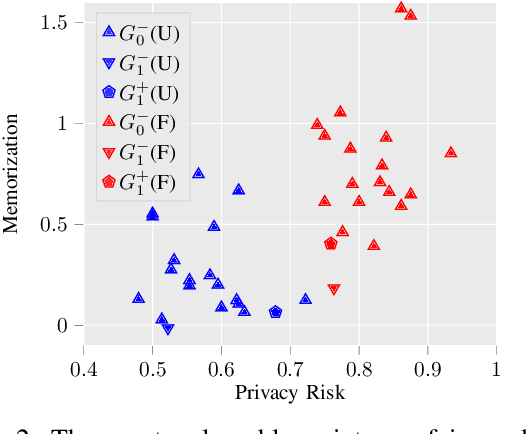
Algorithmic fairness and privacy are essential elements of trustworthy machine learning for critical decision making processes. Fair machine learning algorithms are developed to minimize discrimination against protected groups in machine learning. This is achieved, for example, by imposing a constraint on the model to equalize its behavior across different groups. This can significantly increase the influence of some training data points on the fair model. We study how this change in influence can change the information leakage of the model about its training data. We analyze the privacy risks of statistical notions of fairness (i.e., equalized odds) through the lens of membership inference attacks: inferring whether a data point was used for training a model. We show that fairness comes at the cost of privacy. However, this privacy cost is not distributed equally: the information leakage of fair models increases significantly on the unprivileged subgroups, which suffer from the discrimination in regular models. Furthermore, the more biased the underlying data is, the higher the privacy cost of achieving fairness for the unprivileged subgroups is. We demonstrate this effect on multiple datasets and explain how fairness-aware learning impacts privacy.
On Adversarial Bias and the Robustness of Fair Machine Learning
Jun 15, 2020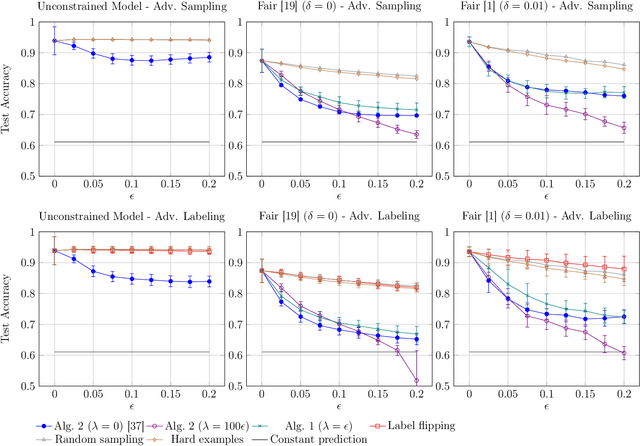
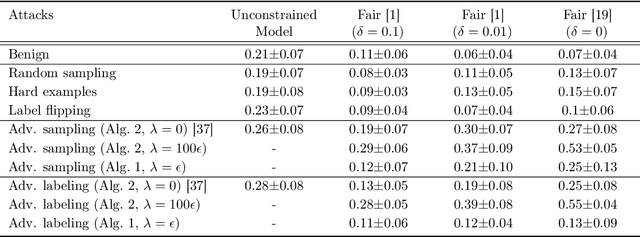
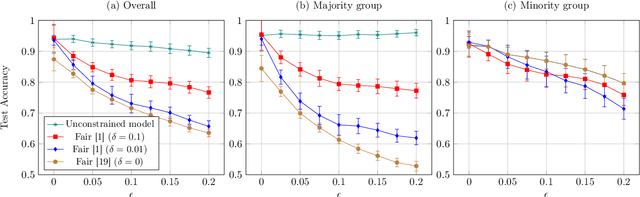
Optimizing prediction accuracy can come at the expense of fairness. Towards minimizing discrimination against a group, fair machine learning algorithms strive to equalize the behavior of a model across different groups, by imposing a fairness constraint on models. However, we show that giving the same importance to groups of different sizes and distributions, to counteract the effect of bias in training data, can be in conflict with robustness. We analyze data poisoning attacks against group-based fair machine learning, with the focus on equalized odds. An adversary who can control sampling or labeling for a fraction of training data, can reduce the test accuracy significantly beyond what he can achieve on unconstrained models. Adversarial sampling and adversarial labeling attacks can also worsen the model's fairness gap on test data, even though the model satisfies the fairness constraint on training data. We analyze the robustness of fair machine learning through an empirical evaluation of attacks on multiple algorithms and benchmark datasets.
Cronus: Robust and Heterogeneous Collaborative Learning with Black-Box Knowledge Transfer
Dec 24, 2019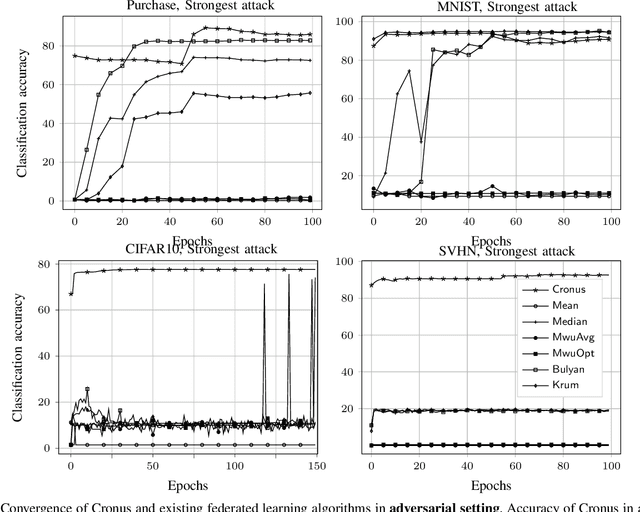
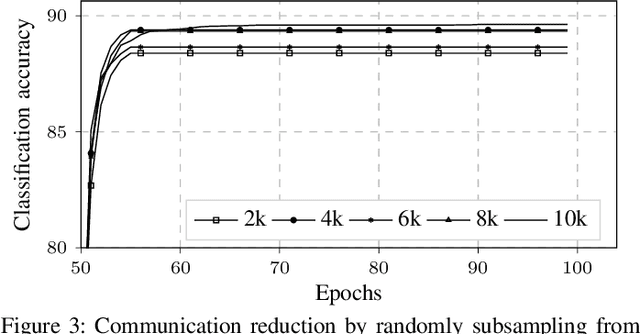
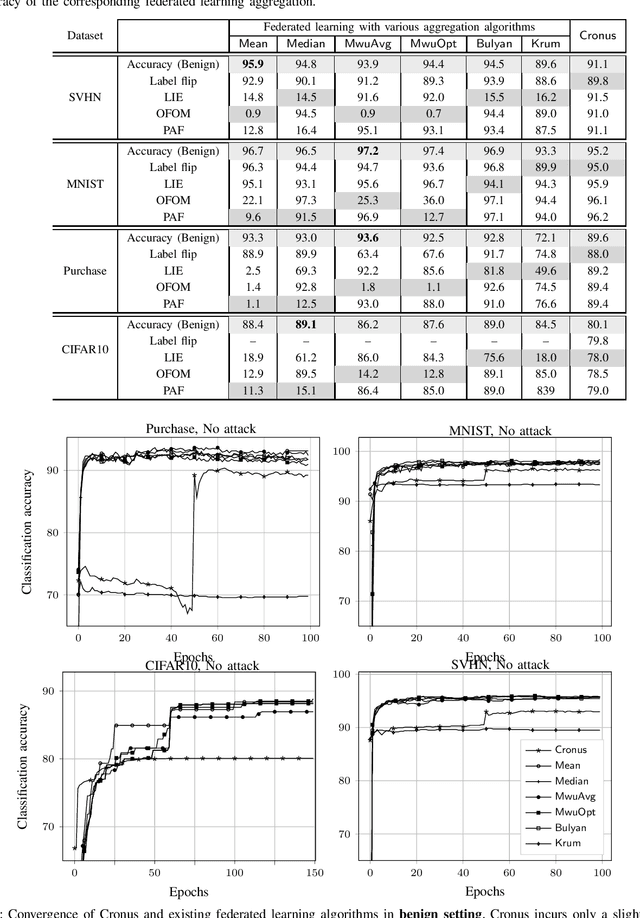
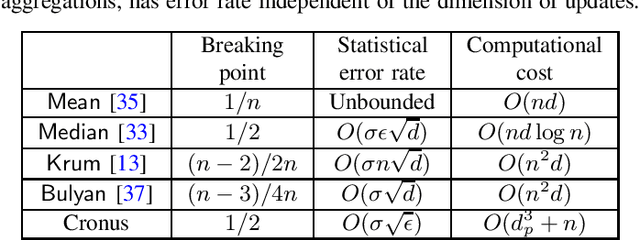
Collaborative (federated) learning enables multiple parties to train a model without sharing their private data, but through repeated sharing of the parameters of their local models. Despite its advantages, this approach has many known privacy and security weaknesses and performance overhead, in addition to being limited only to models with homogeneous architectures. Shared parameters leak a significant amount of information about the local (and supposedly private) datasets. Besides, federated learning is severely vulnerable to poisoning attacks, where some participants can adversarially influence the aggregate parameters. Large models, with high dimensional parameter vectors, are in particular highly susceptible to privacy and security attacks: curse of dimensionality in federated learning. We argue that sharing parameters is the most naive way of information exchange in collaborative learning, as they open all the internal state of the model to inference attacks, and maximize the model's malleability by stealthy poisoning attacks. We propose Cronus, a robust collaborative machine learning framework. The simple yet effective idea behind designing Cronus is to control, unify, and significantly reduce the dimensions of the exchanged information between parties, through robust knowledge transfer between their black-box local models. We evaluate all existing federated learning algorithms against poisoning attacks, and we show that Cronus is the only secure method, due to its tight robustness guarantee. Treating local models as black-box, reduces the information leakage through models, and enables us using existing privacy-preserving algorithms that mitigate the risk of information leakage through the model's output (predictions). Cronus also has a significantly lower sample complexity, compared to federated learning, which does not bind its security to the number of participants.