 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Impact of Machine Learning Randomness on Group Fairness
Paper and Code
Jul 09, 2023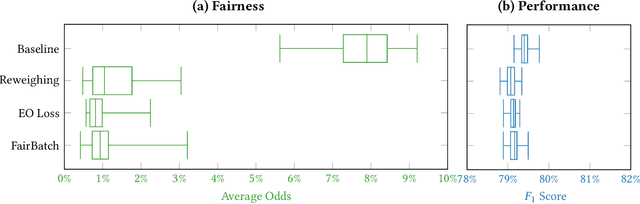
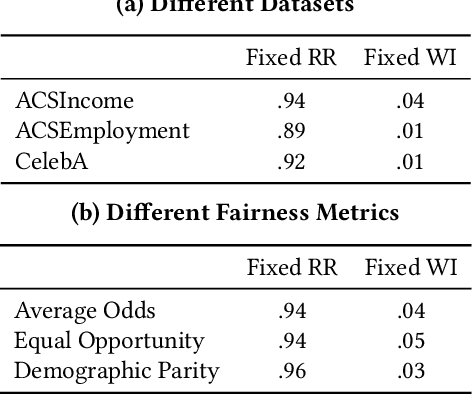
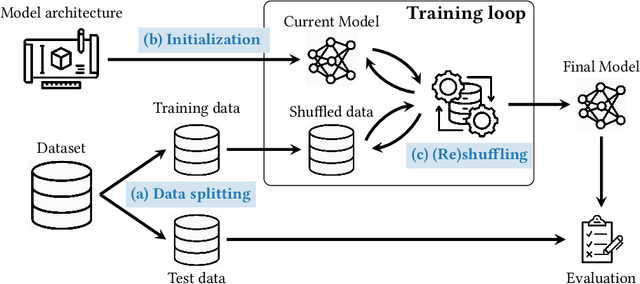
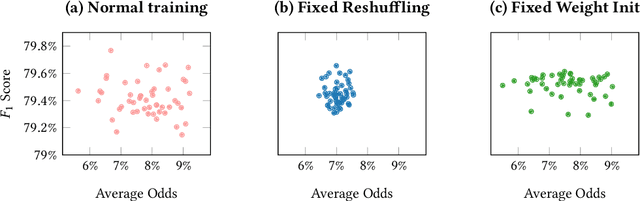
Statistical measures for group fairness in machine learning reflect the gap in performance of algorithms across different groups. These measures, however, exhibit a high variance between different training instances, which makes them unreliable for empirical evaluation of fairness. What causes this high variance? We investigate the impact on group fairness of different sources of randomness in training neural networks. We show that the variance in group fairness measures is rooted in the high volatility of the learning process on under-represented groups. Further, we recognize the dominant source of randomness as the stochasticity of data order during training. Based on these findings, we show how one can control group-level accuracy (i.e., model fairness), with high efficiency and negligible impact on the model's overall performance, by simply changing the data order for a single epoch.