 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Hallucinations: Correctness, Consistency, and Prompt Multiplicity
Jan 31, 2026Large language models (LLMs) are known to "hallucinate" by generating false or misleading outputs. Hallucinations pose various harms, from erosion of trust to widespread misinformation. Existing hallucination evaluation, however, focuses only on correctness and often overlooks consistency, necessary to distinguish and address these harms. To bridge this gap, we introduce prompt multiplicity, a framework for quantifying consistency in LLM evaluations. Our analysis reveals significant multiplicity (over 50% inconsistency in benchmarks like Med-HALT), suggesting that hallucination-related harms have been severely misunderstood. Furthermore, we study the role of consistency in hallucination detection and mitigation. We find that: (a) detection techniques detect consistency, not correctness, and (b) mitigation techniques like RAG, while beneficial, can introduce additional inconsistencies. By integrating prompt multiplicity into hallucination evaluation, we provide an improved framework of potential harms and uncover critical limitations in current detection and mitigation strategies.
Say It Another Way: A Framework for User-Grounded Paraphrasing
May 06, 2025Small changes in how a prompt is worded can lead to meaningful differences in the behavior of large language models (LLMs), raising concerns about the stability and reliability of their evaluations. While prior work has explored simple formatting changes, these rarely capture the kinds of natural variation seen in real-world language use. We propose a controlled paraphrasing framework based on a taxonomy of minimal linguistic transformations to systematically generate natural prompt variations. Using the BBQ dataset, we validate our method with both human annotations and automated checks, then use it to study how LLMs respond to paraphrased prompts in stereotype evaluation tasks. Our analysis shows that even subtle prompt modifications can lead to substantial changes in model behavior. These results highlight the need for robust, paraphrase-aware evaluation protocols.
The Curious Case of Arbitrariness in Machine Learning
Jan 24, 2025Algorithmic modelling relies on limited information in data to extrapolate outcomes for unseen scenarios, often embedding an element of arbitrariness in its decisions. A perspective on this arbitrariness that has recently gained interest is multiplicity-the study of arbitrariness across a set of "good models", i.e., those likely to be deployed in practice. In this work, we systemize the literature on multiplicity by: (a) formalizing the terminology around model design choices and their contribution to arbitrariness, (b) expanding the definition of multiplicity to incorporate underrepresented forms beyond just predictions and explanations, (c) clarifying the distinction between multiplicity and other traditional lenses of arbitrariness, i.e., uncertainty and variance, and (d) distilling the benefits and potential risks of multiplicity into overarching trends, situating it within the broader landscape of responsible AI. We conclude by identifying open research questions and highlighting emerging trends in this young but rapidly growing area of research.
Different Horses for Different Courses: Comparing Bias Mitigation Algorithms in ML
Nov 19, 2024
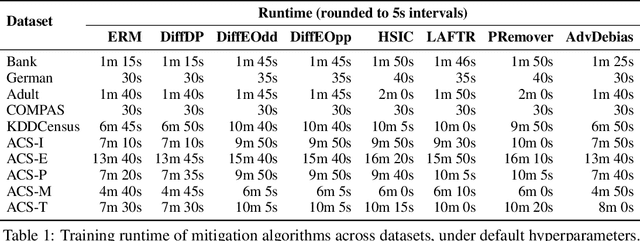


With fairness concerns gaining significant attention in Machine Learning (ML), several bias mitigation techniques have been proposed, often compared against each other to find the best method. These benchmarking efforts tend to use a common setup for evaluation under the assumption that providing a uniform environment ensures a fair comparison. However, bias mitigation techniques are sensitive to hyperparameter choices, random seeds, feature selection, etc., meaning that comparison on just one setting can unfairly favour certain algorithms. In this work, we show significant variance in fairness achieved by several algorithms and the influence of the learning pipeline on fairness scores. We highlight that most bias mitigation techniques can achieve comparable performance, given the freedom to perform hyperparameter optimization, suggesting that the choice of the evaluation parameters-rather than the mitigation technique itself-can sometimes create the perceived superiority of one method over another. We hope our work encourages future research on how various choices in the lifecycle of developing an algorithm impact fairness, and trends that guide the selection of appropriate algorithms.
Towards More Realistic Extraction Attacks: An Adversarial Perspective
Jul 02, 2024Language models are prone to memorizing large parts of their training data, making them vulnerable to extraction attacks. Existing research on these attacks remains limited in scope, often studying isolated trends rather than the real-world interactions with these models. In this paper, we revisit extraction attacks from an adversarial perspective, exploiting the brittleness of language models. We find significant churn in extraction attack trends, i.e., even minor, unintuitive changes to the prompt, or targeting smaller models and older checkpoints, can exacerbate the risks of extraction by up to $2-4 \times$. Moreover, relying solely on the widely accepted verbatim match underestimates the extent of extracted information, and we provide various alternatives to more accurately capture the true risks of extraction. We conclude our discussion with data deduplication, a commonly suggested mitigation strategy, and find that while it addresses some memorization concerns, it remains vulnerable to the same escalation of extraction risks against a real-world adversary. Our findings highlight the necessity of acknowledging an adversary's true capabilities to avoid underestimating extraction risks.
The Data Minimization Principle in Machine Learning
May 29, 2024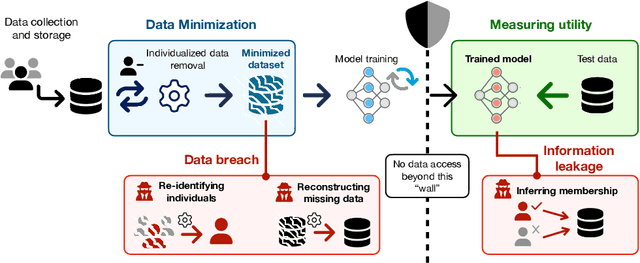


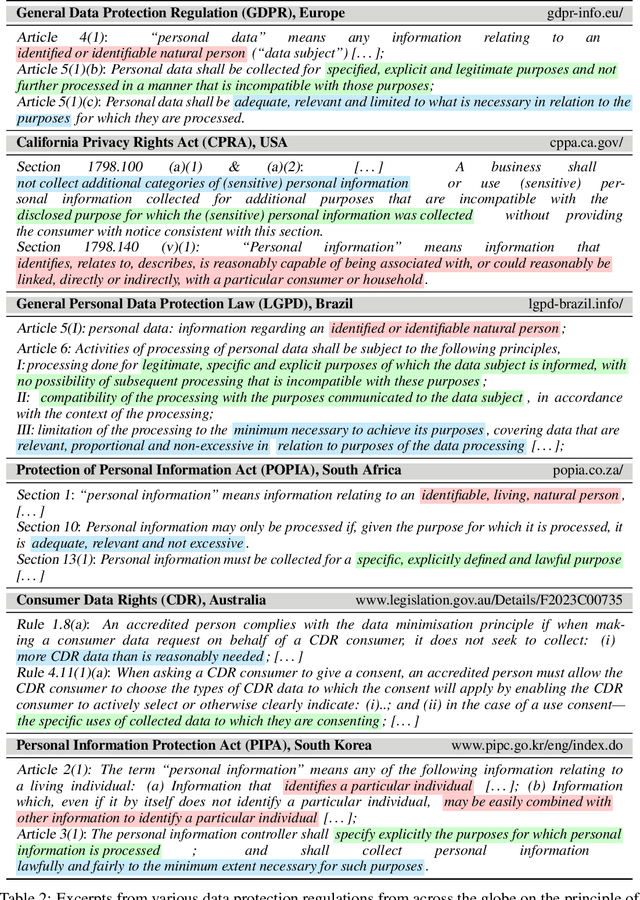
The principle of data minimization aims to reduce the amount of data collected, processed or retained to minimize the potential for misuse, unauthorized access, or data breaches. Rooted in privacy-by-design principles, data minimization has been endorsed by various global data protection regulations. However, its practical implementation remains a challenge due to the lack of a rigorous formulation. This paper addresses this gap and introduces an optimization framework for data minimization based on its legal definitions. It then adapts several optimization algorithms to perform data minimization and conducts a comprehensive evaluation in terms of their compliance with minimization objectives as well as their impact on user privacy. Our analysis underscores the mismatch between the privacy expectations of data minimization and the actual privacy benefits, emphasizing the need for approaches that account for multiple facets of real-world privacy risks.
An Empirical Investigation into Benchmarking Model Multiplicity for Trustworthy Machine Learning: A Case Study on Image Classification
Nov 24, 2023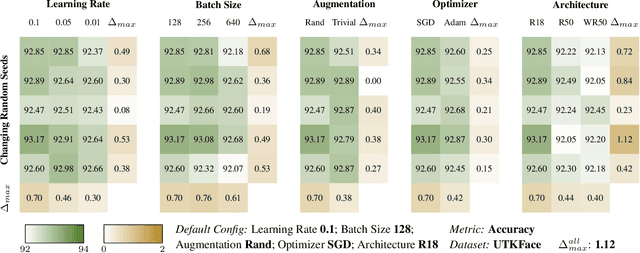
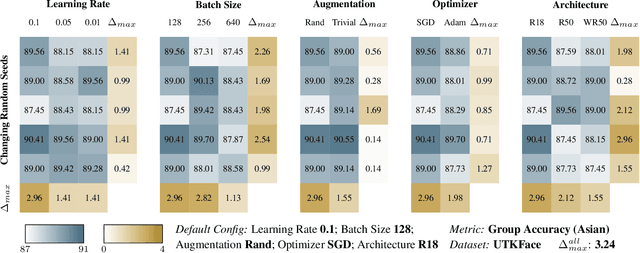

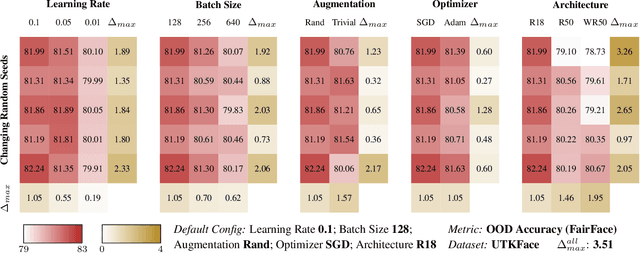
Deep learning models have proven to be highly successful. Yet, their over-parameterization gives rise to model multiplicity, a phenomenon in which multiple models achieve similar performance but exhibit distinct underlying behaviours. This multiplicity presents a significant challenge and necessitates additional specifications in model selection to prevent unexpected failures during deployment. While prior studies have examined these concerns, they focus on individual metrics in isolation, making it difficult to obtain a comprehensive view of multiplicity in trustworthy machine learning. Our work stands out by offering a one-stop empirical benchmark of multiplicity across various dimensions of model design and its impact on a diverse set of trustworthy metrics. In this work, we establish a consistent language for studying model multiplicity by translating several trustworthy metrics into accuracy under appropriate interventions. We also develop a framework, which we call multiplicity sheets, to benchmark multiplicity in various scenarios. We demonstrate the advantages of our setup through a case study in image classification and provide actionable insights into the impact and trends of different hyperparameters on model multiplicity. Finally, we show that multiplicity persists in deep learning models even after enforcing additional specifications during model selection, highlighting the severity of over-parameterization. The concerns of under-specification thus remain, and we seek to promote a more comprehensive discussion of multiplicity in trustworthy machine learning.
On The Impact of Machine Learning Randomness on Group Fairness
Jul 09, 2023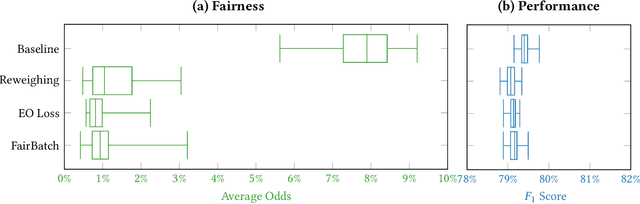
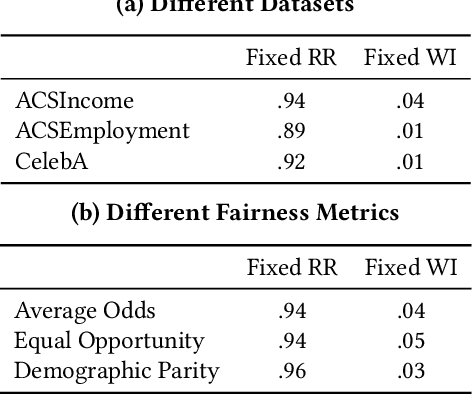
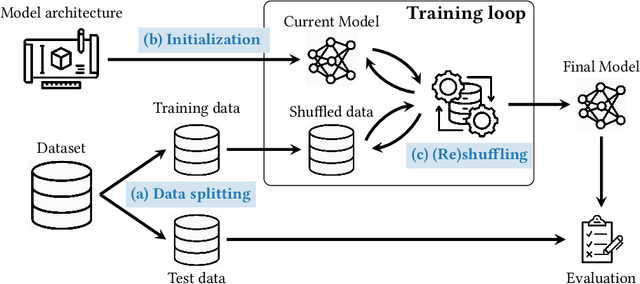
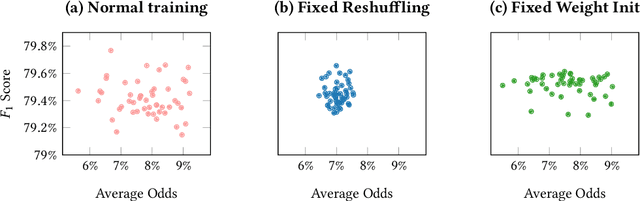
Statistical measures for group fairness in machine learning reflect the gap in performance of algorithms across different groups. These measures, however, exhibit a high variance between different training instances, which makes them unreliable for empirical evaluation of fairness. What causes this high variance? We investigate the impact on group fairness of different sources of randomness in training neural networks. We show that the variance in group fairness measures is rooted in the high volatility of the learning process on under-represented groups. Further, we recognize the dominant source of randomness as the stochasticity of data order during training. Based on these findings, we show how one can control group-level accuracy (i.e., model fairness), with high efficiency and negligible impact on the model's overall performance, by simply changing the data order for a single epoch.
HiKonv: High Throughput Quantized Convolution With Novel Bit-wise Management and Computation
Dec 28, 2021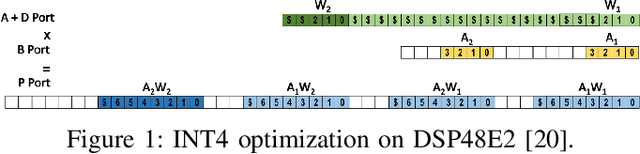
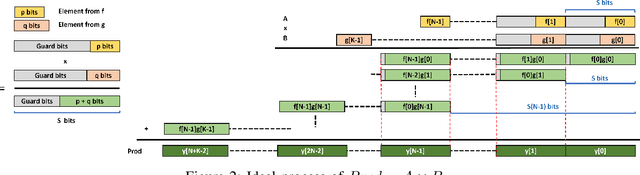

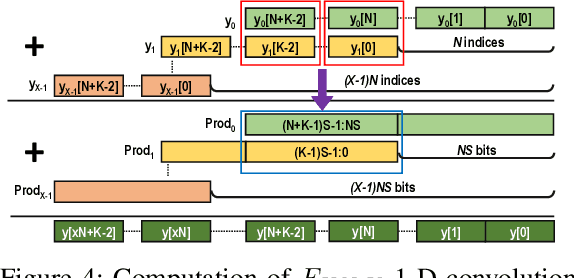
Quantization for Convolutional Neural Network (CNN) has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data inputs. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as CPUs and DSPs, can be better utilized to carry out significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the compute throughput of a given underlying processing unit to process low-bitwidth quantized data inputs through novel bit-wise parallel computation. We establish theoretical performance bounds using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit can deliver 128 binarized convolution operations (multiplications and additions) under one CPU instruction, and a single 27x18 DSP core can deliver eight convolution operations with 4-bit inputs in one cycle. We demonstrate the effectiveness of HiKonv on CPU and FPGA for both convolutional layers or a complete DNN model. For a convolutional layer quantized to 4-bit, HiKonv achieves a 3.17x latency improvement over the baseline implementation using C++ on CPU. Compared to the DAC-SDC 2020 champion model for FPGA, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs
Oct 26, 2021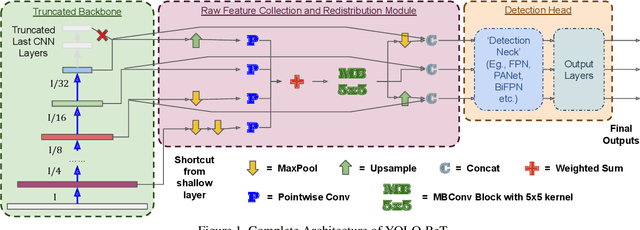
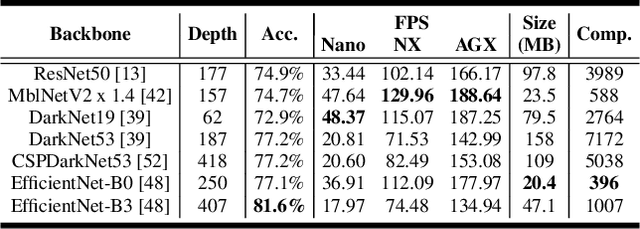
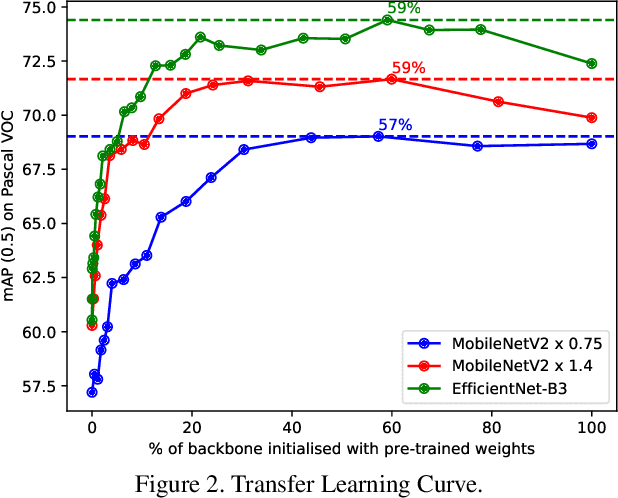
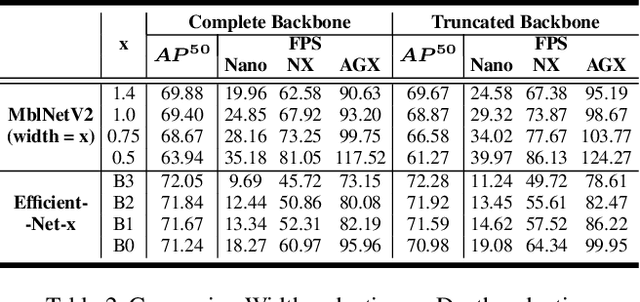
Performance of object detection models has been growing rapidly on two major fronts, model accuracy and efficiency. However, in order to map deep neural network (DNN) based object detection models to edge devices, one typically needs to compress such models significantly, thus compromising the model accuracy. In this paper, we propose a novel edge GPU friendly module for multi-scale feature interaction by exploiting missing combinatorial connections between various feature scales in existing state-of-the-art methods. Additionally, we propose a novel transfer learning backbone adoption inspired by the changing translational information flow across various tasks, designed to complement our feature interaction module and together improve both accuracy as well as execution speed on various edge GPU devices available in the market. For instance, YOLO-ReT with MobileNetV2x0.75 backbone runs real-time on Jetson Nano, and achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO, beating its peers by 3.05 mAP and 0.91 mAP respectively, while executing faster by 3.05 FPS. Furthermore, introducing our multi-scale feature interaction module in YOLOv4-tiny and YOLOv4-tiny (3l) improves their performance to 41.5 and 48.1 mAP respectively on COCO, outperforming the original versions by 1.3 and 0.9 mAP.