 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Co-Saliency Detection: Context Adjustment
Paper and Code
Aug 04, 2021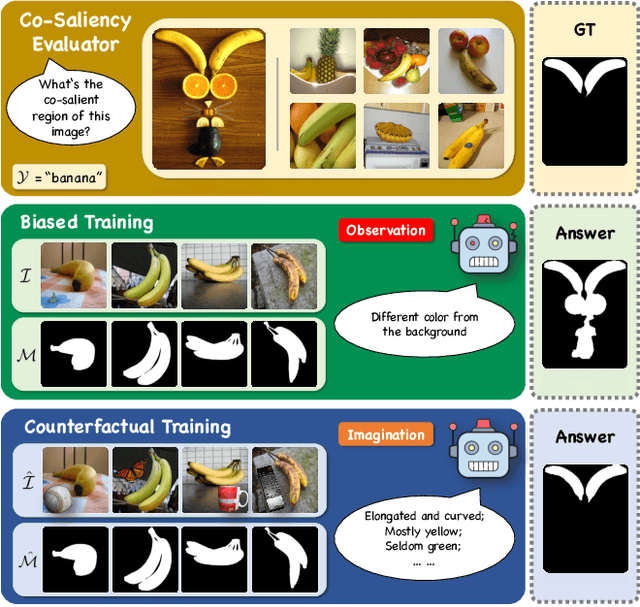
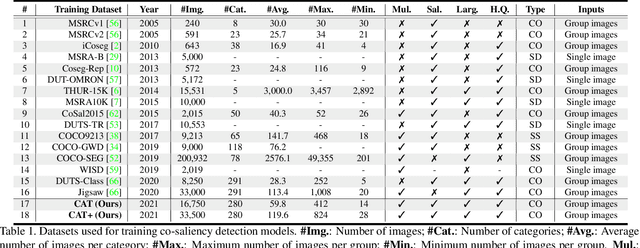
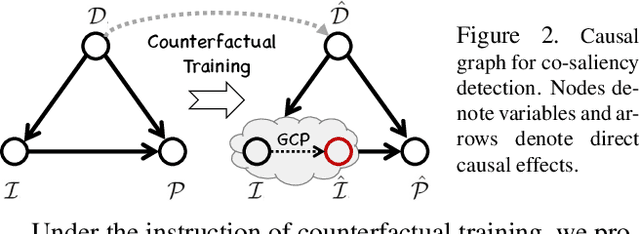
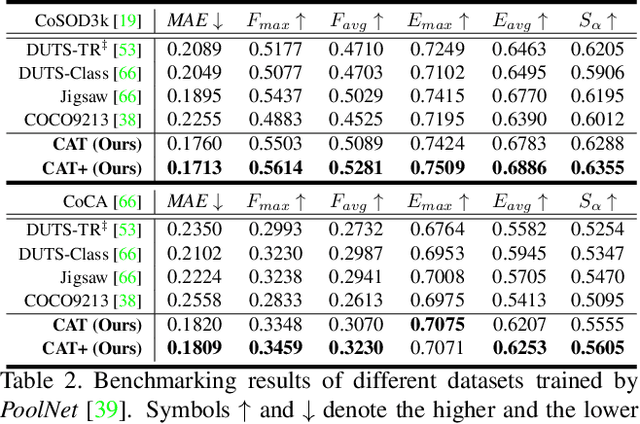
We unveil a long-standing problem in the prevailing co-saliency detection systems: there is indeed inconsistency between training and testing. Constructing a high-quality co-saliency detection dataset involves time-consuming and labor-intensive pixel-level labeling, which has forced most recent works to rely instead on semantic segmentation or saliency detection datasets for training. However, the lack of proper co-saliency and the absence of multiple foreground objects in these datasets can lead to spurious variations and inherent biases learned by models. To tackle this, we introduce the idea of counterfactual training through context adjustment, and propose a "cost-free" group-cut-paste (GCP) procedure to leverage images from off-the-shelf saliency detection datasets and synthesize new samples. Following GCP, we collect a novel dataset called Context Adjustment Training. The two variants of our dataset, i.e., CAT and CAT+, consist of 16,750 and 33,500 images, respectively. All images are automatically annotated with high-quality masks. As a side-product, object categories, as well as edge information, are also provided to facilitate other related works. Extensive experiments with state-of-the-art models are conducted to demonstrate the superiority of our dataset. We hope that the scale, diversity, and quality of CAT/CAT+ can benefit researchers in this area and beyond. The dataset and benchmark toolkit will be accessible through our project page.