 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-LIME: Surgical Interpretation of Long-Context Large Language Models via Proxy-Based Neighborhood Selection
Feb 04, 2026As Large Language Models (LLMs) scale to handle massive context windows, achieving surgical feature-level interpretation is essential for high-stakes tasks like legal auditing and code debugging. However, existing local model-agnostic explanation methods face a critical dilemma in these scenarios: feature-based methods suffer from attribution dilution due to high feature dimensionality, thus failing to provide faithful explanations. In this paper, we propose Focus-LIME, a coarse-to-fine framework designed to restore the tractability of surgical interpretation. Focus-LIME utilizes a proxy model to curate the perturbation neighborhood, allowing the target model to perform fine-grained attribution exclusively within the optimized context. Empirical evaluations on long-context benchmarks demonstrate that our method makes surgical explanations practicable and provides faithful explanations to users.
Towards Budget-Friendly Model-Agnostic Explanation Generation for Large Language Models
May 18, 2025With Large language models (LLMs) becoming increasingly prevalent in various applications, the need for interpreting their predictions has become a critical challenge. As LLMs vary in architecture and some are closed-sourced, model-agnostic techniques show great promise without requiring access to the model's internal parameters. However, existing model-agnostic techniques need to invoke LLMs many times to gain sufficient samples for generating faithful explanations, which leads to high economic costs. In this paper, we show that it is practical to generate faithful explanations for large-scale LLMs by sampling from some budget-friendly models through a series of empirical studies. Moreover, we show that such proxy explanations also perform well on downstream tasks. Our analysis provides a new paradigm of model-agnostic explanation methods for LLMs, by including information from budget-friendly models.
Single-Cell Omics Arena: A Benchmark Study for Large Language Models on Cell Type Annotation Using Single-Cell Data
Dec 03, 2024
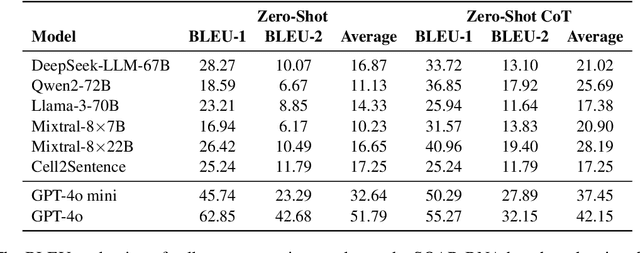


Over the past decade, the revolution in single-cell sequencing has enabled the simultaneous molecular profiling of various modalities across thousands of individual cells, allowing scientists to investigate the diverse functions of complex tissues and uncover underlying disease mechanisms. Among all the analytical steps, assigning individual cells to specific types is fundamental for understanding cellular heterogeneity. However, this process is usually labor-intensive and requires extensive expert knowledge. Recent advances in large language models (LLMs) have demonstrated their ability to efficiently process and synthesize vast corpora of text to automatically extract essential biological knowledge, such as marker genes, potentially promoting more efficient and automated cell type annotations. To thoroughly evaluate the capability of modern instruction-tuned LLMs in automating the cell type identification process, we introduce SOAR, a comprehensive benchmarking study of LLMs for cell type annotation tasks in single-cell genomics. Specifically, we assess the performance of 8 instruction-tuned LLMs across 11 datasets, spanning multiple cell types and species. Our study explores the potential of LLMs to accurately classify and annotate cell types in single-cell RNA sequencing (scRNA-seq) data, while extending their application to multiomics data through cross-modality translation. Additionally, we evaluate the effectiveness of chain-of-thought (CoT) prompting techniques in generating detailed biological insights during the annotation process. The results demonstrate that LLMs can provide robust interpretations of single-cell data without requiring additional fine-tuning, advancing the automation of cell type annotation in genomics research.
ConLUX: Concept-Based Local Unified Explanations
Oct 16, 2024
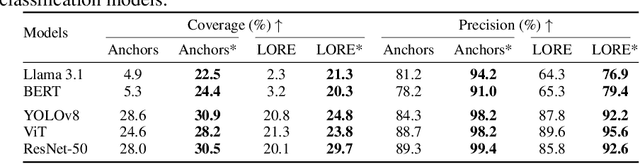
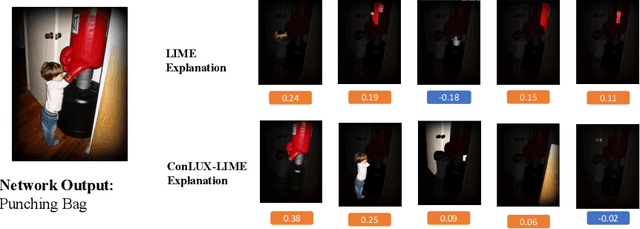
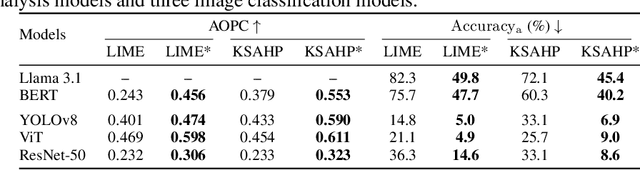
With the rapid advancements of various machine learning models, there is a significant demand for model-agnostic explanation techniques, which can explain these models across different architectures. Mainstream model-agnostic explanation techniques generate local explanations based on basic features (e.g., words for text models and (super-)pixels for image models). However, these explanations often do not align with the decision-making processes of the target models and end-users, resulting in explanations that are unfaithful and difficult for users to understand. On the other hand, concept-based techniques provide explanations based on high-level features (e.g., topics for text models and objects for image models), but most are model-specific or require additional pre-defined external concept knowledge. To address this limitation, we propose \toolname, a general framework to provide concept-based local explanations for any machine learning models. Our key insight is that we can automatically extract high-level concepts from large pre-trained models, and uniformly extend existing local model-agnostic techniques to provide unified concept-based explanations. We have instantiated \toolname on four different types of explanation techniques: LIME, Kernel SHAP, Anchor, and LORE, and applied these techniques to text and image models. Our evaluation results demonstrate that 1) compared to the vanilla versions, \toolname offers more faithful explanations and makes them more understandable to users, and 2) by offering multiple forms of explanations, \toolname outperforms state-of-the-art concept-based explanation techniques specifically designed for text and image models, respectively.
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Jun 27, 2024



Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
One Shot Learning as Instruction Data Prospector for Large Language Models
Jan 04, 2024Aligning large language models(LLMs) with human is a critical step in effectively utilizing their pre-trained capabilities across a wide array of language tasks. Current instruction tuning practices often rely on expanding dataset size without a clear strategy for ensuring data quality, which can inadvertently introduce noise and degrade model performance. To address this challenge, we introduce Nuggets, a novel and efficient methodology that employs one shot learning to select high-quality instruction data from expansive datasets. Nuggets assesses the potential of individual instruction examples to act as effective one shot examples, thereby identifying those that can significantly enhance diverse task performance. Nuggets utilizes a scoring system based on the impact of candidate examples on the perplexity of a diverse anchor set, facilitating the selection of the most beneficial data for instruction tuning. Through rigorous testing on two benchmarks, including MT-Bench and Alpaca-Eval, we demonstrate that instruction tuning with the top 1% of Nuggets-curated examples substantially outperforms conventional methods that use the full dataset. These findings advocate for a data selection paradigm that prioritizes quality, offering a more efficient pathway to align LLMs with humans.
Marathon: A Race Through the Realm of Long Context with Large Language Models
Dec 15, 2023
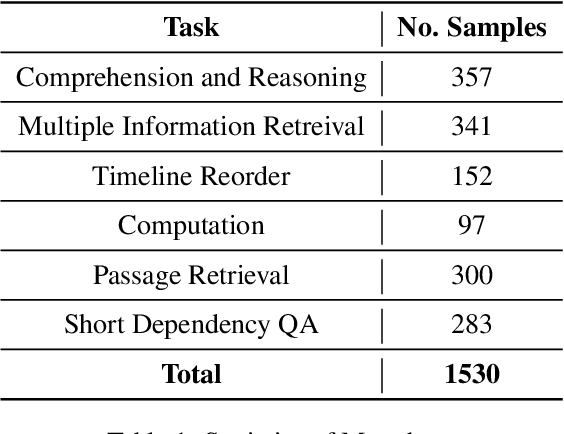


Although there are currently many benchmarks available for evaluating the long context understanding and reasoning capability of large language models, with the expansion of the context window in these models, the existing long context benchmarks are no longer sufficient for evaluating the long context understanding and reasoning capability of large language models. In this paper, we have developed a fresh long context evaluation benchmark, which we name it Marathon in the form of multiple choice questions, inspired by benchmarks such as MMLU, for assessing the long context comprehension capability of large language models quickly, accurately, and objectively. We have evaluated several of the latest and most popular large language models, as well as three recent and effective long context optimization methods, on our benchmark. This showcases the long context reasoning and comprehension capabilities of these large language models and validates the effectiveness of these optimization methods. Marathon is available at https://huggingface.co/datasets/Lemoncoke/Marathon.
Self-Distillation with Meta Learning for Knowledge Graph Completion
May 20, 2023



In this paper, we propose a selfdistillation framework with meta learning(MetaSD) for knowledge graph completion with dynamic pruning, which aims to learn compressed graph embeddings and tackle the longtail samples. Specifically, we first propose a dynamic pruning technique to obtain a small pruned model from a large source model, where the pruning mask of the pruned model could be updated adaptively per epoch after the model weights are updated. The pruned model is supposed to be more sensitive to difficult to memorize samples(e.g., longtail samples) than the source model. Then, we propose a onestep meta selfdistillation method for distilling comprehensive knowledge from the source model to the pruned model, where the two models coevolve in a dynamic manner during training. In particular, we exploit the performance of the pruned model, which is trained alongside the source model in one iteration, to improve the source models knowledge transfer ability for the next iteration via meta learning. Extensive experiments show that MetaSD achieves competitive performance compared to strong baselines, while being 10x smaller than baselines.
ReX: A Framework for Generating Local Explanations to Recurrent Neural Networks
Sep 08, 2022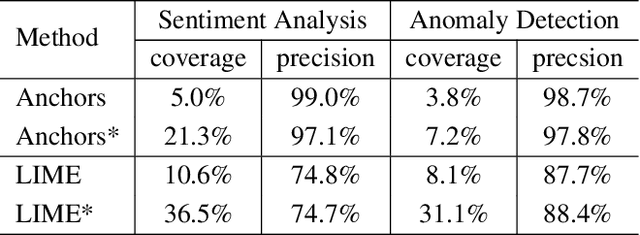



We propose a general framework to adapt various local explanation techniques to recurrent neural networks. In particular, our explanations add temporal information, which expand explanations generated from existing techniques to cover data points that have different lengths compared to the original input data point. Our approach is general as it only modifies the perturbation model and feature representation of existing techniques without touching their core algorithms. We have instantiated our approach on LIME and Anchors. Our empirical evaluation shows that it effectively improves the usefulness of explanations generated by these two techniques on a sentiment analysis network and an anomaly detection network.
Free Lunch for Co-Saliency Detection: Context Adjustment
Aug 04, 2021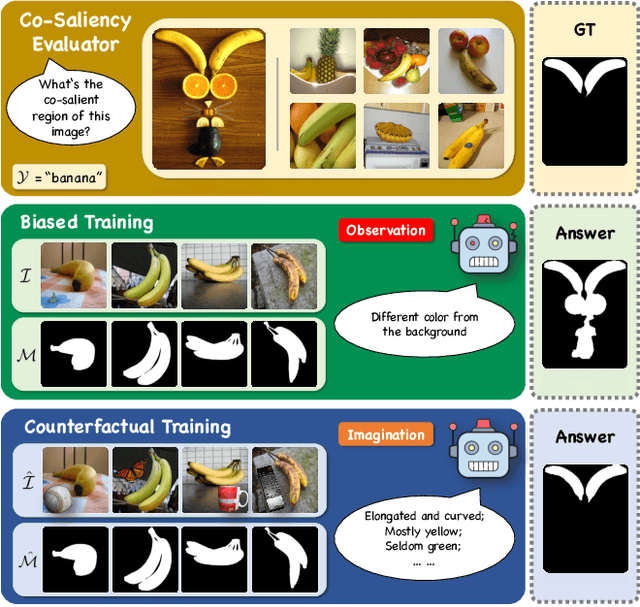
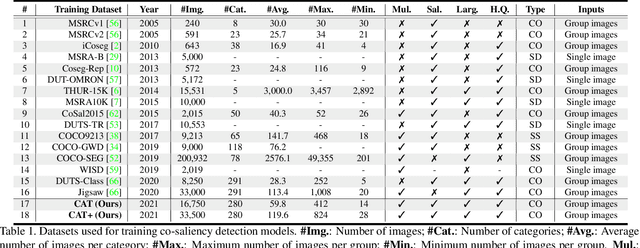
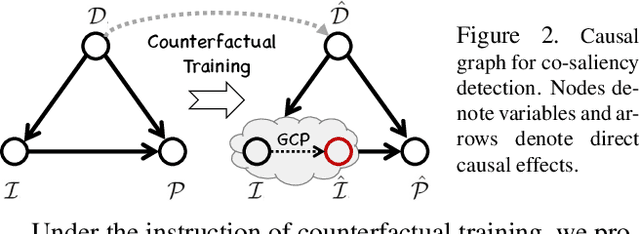
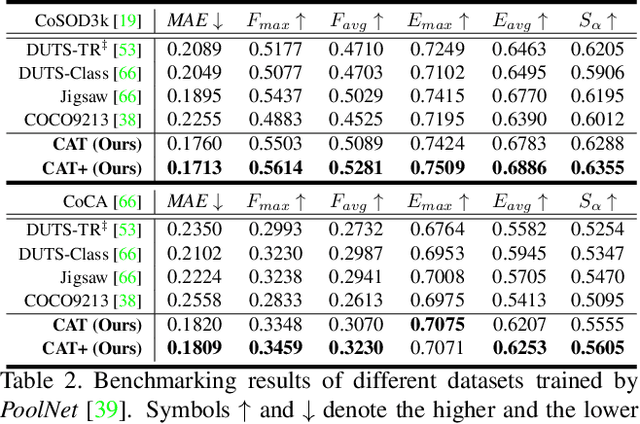
We unveil a long-standing problem in the prevailing co-saliency detection systems: there is indeed inconsistency between training and testing. Constructing a high-quality co-saliency detection dataset involves time-consuming and labor-intensive pixel-level labeling, which has forced most recent works to rely instead on semantic segmentation or saliency detection datasets for training. However, the lack of proper co-saliency and the absence of multiple foreground objects in these datasets can lead to spurious variations and inherent biases learned by models. To tackle this, we introduce the idea of counterfactual training through context adjustment, and propose a "cost-free" group-cut-paste (GCP) procedure to leverage images from off-the-shelf saliency detection datasets and synthesize new samples. Following GCP, we collect a novel dataset called Context Adjustment Training. The two variants of our dataset, i.e., CAT and CAT+, consist of 16,750 and 33,500 images, respectively. All images are automatically annotated with high-quality masks. As a side-product, object categories, as well as edge information, are also provided to facilitate other related works. Extensive experiments with state-of-the-art models are conducted to demonstrate the superiority of our dataset. We hope that the scale, diversity, and quality of CAT/CAT+ can benefit researchers in this area and beyond. The dataset and benchmark toolkit will be accessible through our project page.