 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
InFi-Check: Interpretable and Fine-Grained Fact-Checking of LLMs
Jan 10, 2026Large language models (LLMs) often hallucinate, yet most existing fact-checking methods treat factuality evaluation as a binary classification problem, offering limited interpretability and failing to capture fine-grained error types. In this paper, we introduce InFi-Check, a framework for interpretable and fine-grained fact-checking of LLM outputs. Specifically, we first propose a controlled data synthesis pipeline that generates high-quality data featuring explicit evidence, fine-grained error type labels, justifications, and corrections. Based on this, we further construct large-scale training data and a manually verified benchmark InFi-Check-FG for fine-grained fact-checking of LLM outputs. Building on these high-quality training data, we further propose InFi-Checker, which can jointly provide supporting evidence, classify fine-grained error types, and produce justifications along with corrections. Experiments show that InFi-Checker achieves state-of-the-art performance on InFi-Check-FG and strong generalization across various downstream tasks, significantly improving the utility and trustworthiness of factuality evaluation.
MEIC-DT: Memory-Efficient Incremental Clustering for Long-Text Coreference Resolution with Dual-Threshold Constraints
Dec 31, 2025In the era of large language models (LLMs), supervised neural methods remain the state-of-the-art (SOTA) for Coreference Resolution. Yet, their full potential is underexplored, particularly in incremental clustering, which faces the critical challenge of balancing efficiency with performance for long texts. To address the limitation, we propose \textbf{MEIC-DT}, a novel dual-threshold, memory-efficient incremental clustering approach based on a lightweight Transformer. MEIC-DT features a dual-threshold constraint mechanism designed to precisely control the Transformer's input scale within a predefined memory budget. This mechanism incorporates a Statistics-Aware Eviction Strategy (\textbf{SAES}), which utilizes distinct statistical profiles from the training and inference phases for intelligent cache management. Furthermore, we introduce an Internal Regularization Policy (\textbf{IRP}) that strategically condenses clusters by selecting the most representative mentions, thereby preserving semantic integrity. Extensive experiments on common benchmarks demonstrate that MEIC-DT achieves highly competitive coreference performance under stringent memory constraints.
FaithLens: Detecting and Explaining Faithfulness Hallucination
Dec 23, 2025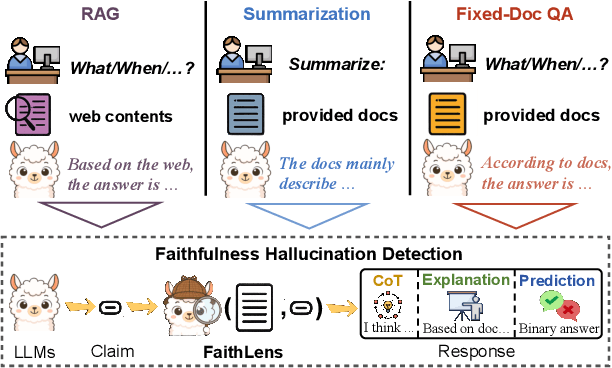
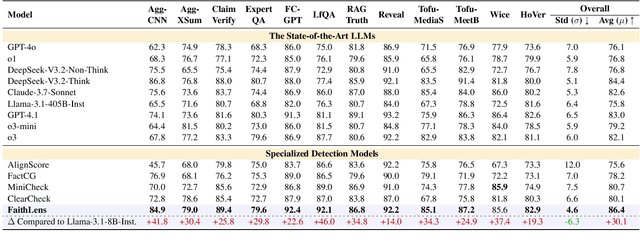
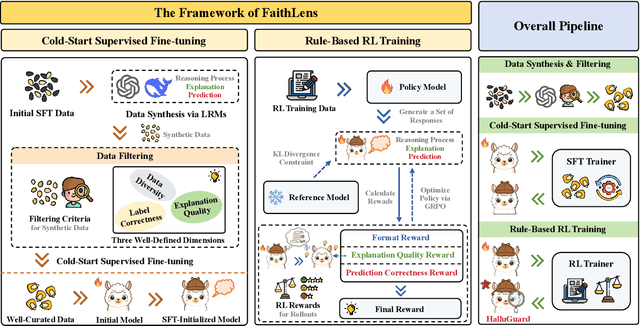
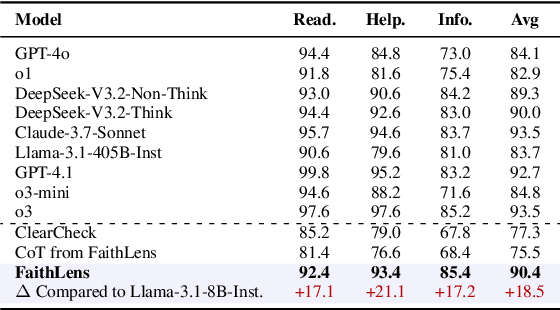
Recognizing whether outputs from large language models (LLMs) contain faithfulness hallucination is crucial for real-world applications, e.g., retrieval-augmented generation and summarization. In this paper, we introduce FaithLens, a cost-efficient and effective faithfulness hallucination detection model that can jointly provide binary predictions and corresponding explanations to improve trustworthiness. To achieve this, we first synthesize training data with explanations via advanced LLMs and apply a well-defined data filtering strategy to ensure label correctness, explanation quality, and data diversity. Subsequently, we fine-tune the model on these well-curated training data as a cold start and further optimize it with rule-based reinforcement learning, using rewards for both prediction correctness and explanation quality. Results on 12 diverse tasks show that the 8B-parameter FaithLens outperforms advanced models such as GPT-4.1 and o3. Also, FaithLens can produce high-quality explanations, delivering a distinctive balance of trustworthiness, efficiency, and effectiveness.
From Context to EDUs: Faithful and Structured Context Compression via Elementary Discourse Unit Decomposition
Dec 18, 2025Managing extensive context remains a critical bottleneck for Large Language Models (LLMs), particularly in applications like long-document question answering and autonomous agents where lengthy inputs incur high computational costs and introduce noise. Existing compression techniques often disrupt local coherence through discrete token removal or rely on implicit latent encoding that suffers from positional bias and incompatibility with closed-source APIs. To address these limitations, we introduce the EDU-based Context Compressor, a novel explicit compression framework designed to preserve both global structure and fine-grained details. Our approach reformulates context compression as a structure-then-select process. First, our LingoEDU transforms linear text into a structural relation tree of Elementary Discourse Units (EDUs) which are anchored strictly to source indices to eliminate hallucination. Second, a lightweight ranking module selects query-relevant sub-trees for linearization. To rigorously evaluate structural understanding, we release StructBench, a manually annotated dataset of 248 diverse documents. Empirical results demonstrate that our method achieves state-of-the-art structural prediction accuracy and significantly outperforms frontier LLMs while reducing costs. Furthermore, our structure-aware compression substantially enhances performance across downstream tasks ranging from long-context tasks to complex Deep Search scenarios.
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
May 22, 2025Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
Aligning Large Language Models to Follow Instructions and Hallucinate Less via Effective Data Filtering
Feb 11, 2025Training LLMs on data that contains unfamiliar knowledge during the instruction tuning stage can make LLMs overconfident and encourage hallucinations. To address this challenge, we introduce a novel framework, NOVA, which identifies high-quality data that aligns well with the LLM's learned knowledge to reduce hallucinations. NOVA includes Internal Consistency Probing (ICP) and Semantic Equivalence Identification (SEI) to measure how familiar the LLM is with instruction data. Specifically, ICP evaluates the LLM's understanding of the given instruction by calculating the tailored consistency among multiple self-generated responses. SEI further assesses the familiarity of the LLM with the target response by comparing it to the generated responses, using the proposed semantic clustering and well-designed voting strategy. Finally, we introduce an expert-aligned reward model, considering characteristics beyond just familiarity to enhance data quality. By considering data quality and avoiding unfamiliar data, we can utilize the selected data to effectively align LLMs to follow instructions and hallucinate less. Extensive experiments and analysis show that NOVA significantly reduces hallucinations and allows LLMs to maintain a strong ability to follow instructions.
UltraIF: Advancing Instruction Following from the Wild
Feb 06, 2025



Instruction-following made modern large language models (LLMs) helpful assistants. However, the key to taming LLMs on complex instructions remains mysterious, for that there are huge gaps between models trained by open-source community and those trained by leading companies. To bridge the gap, we propose a simple and scalable approach UltraIF for building LLMs that can follow complex instructions with open-source data. UltraIF first decomposes real-world user prompts into simpler queries, constraints, and corresponding evaluation questions for the constraints. Then, we train an UltraComposer to compose constraint-associated prompts with evaluation questions. This prompt composer allows us to synthesize complicated instructions as well as filter responses with evaluation questions. In our experiment, for the first time, we successfully align LLaMA-3.1-8B-Base to catch up with its instruct version on 5 instruction-following benchmarks without any benchmark information, using only 8B model as response generator and evaluator. The aligned model also achieved competitive scores on other benchmarks. Moreover, we also show that UltraIF could further improve LLaMA-3.1-8B-Instruct through self-alignment, motivating broader use cases for the method. Our code will be available at https://github.com/kkk-an/UltraIF.
Looking Beyond Text: Reducing Language bias in Large Vision-Language Models via Multimodal Dual-Attention and Soft-Image Guidance
Nov 21, 2024Large vision-language models (LVLMs) have achieved impressive results in various vision-language tasks. However, despite showing promising performance, LVLMs suffer from hallucinations caused by language bias, leading to diminished focus on images and ineffective visual comprehension. We identify two primary reasons for this bias: 1. Different scales of training data between the pretraining stage of LLM and multimodal alignment stage. 2. The learned inference bias due to short-term dependency of text data. Therefore, we propose LACING, a systemic framework designed to address the language bias of LVLMs with muLtimodal duAl-attention meChanIsm (MDA) aNd soft-image Guidance (IFG). Specifically, MDA introduces a parallel dual-attention mechanism that enhances the integration of visual inputs across the model. IFG introduces a learnable soft visual prompt during training and inference to replace visual inputs, designed to compel LVLMs to prioritize text inputs. Then, IFG further proposes a novel decoding strategy using the soft visual prompt to mitigate the model's over-reliance on adjacent text inputs. Comprehensive experiments demonstrate that our method effectively debiases LVLMs from their language bias, enhancing visual comprehension and reducing hallucinations without requiring additional training resources or data. The code and model are available at [lacing-lvlm.github.io](https://lacing-lvlm.github.io).