 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Language-Level Performance Disparity in mPLMs via Teacher Language Selection and Cross-lingual Self-Distillation
Apr 12, 2024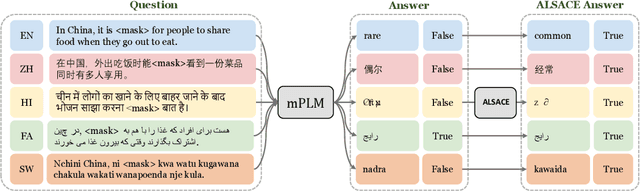
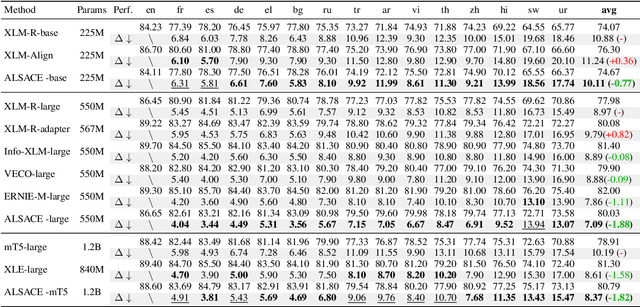
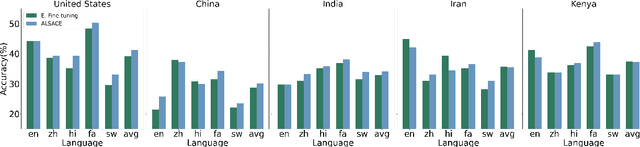
Large-scale multilingual Pretrained Language Models (mPLMs) yield impressive performance on cross-language tasks, yet significant performance disparities exist across different languages within the same mPLM. Previous studies endeavored to narrow these disparities by supervise fine-tuning the mPLMs with multilingual data. However, obtaining labeled multilingual data is time-consuming, and fine-tuning mPLM with limited labeled multilingual data merely encapsulates the knowledge specific to the labeled data. Therefore, we introduce ALSACE to leverage the learned knowledge from the well-performing languages to guide under-performing ones within the same mPLM, eliminating the need for additional labeled multilingual data. Experiments show that ALSACE effectively mitigates language-level performance disparity across various mPLMs while showing the competitive performance on different multilingual NLU tasks, ranging from full resource to limited resource settings. The code for our approach is available at https://github.com/pkunlp-icler/ALSACE.
DiffCap: Exploring Continuous Diffusion on Image Captioning
May 20, 2023Current image captioning works usually focus on generating descriptions in an autoregressive manner. However, there are limited works that focus on generating descriptions non-autoregressively, which brings more decoding diversity. Inspired by the success of diffusion models on generating natural-looking images, we propose a novel method DiffCap to apply continuous diffusions on image captioning. Unlike image generation where the output is fixed-size and continuous, image description length varies with discrete tokens. Our method transforms discrete tokens in a natural way and applies continuous diffusion on them to successfully fuse extracted image features for diffusion caption generation. Our experiments on COCO dataset demonstrate that our method uses a much simpler structure to achieve comparable results to the previous non-autoregressive works. Apart from quality, an intriguing property of DiffCap is its high diversity during generation, which is missing from many autoregressive models. We believe our method on fusing multimodal features in diffusion language generation will inspire more researches on multimodal language generation tasks for its simplicity and decoding flexibility.