 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Large Language Models to Follow Instructions and Hallucinate Less via Effective Data Filtering
Feb 11, 2025Training LLMs on data that contains unfamiliar knowledge during the instruction tuning stage can make LLMs overconfident and encourage hallucinations. To address this challenge, we introduce a novel framework, NOVA, which identifies high-quality data that aligns well with the LLM's learned knowledge to reduce hallucinations. NOVA includes Internal Consistency Probing (ICP) and Semantic Equivalence Identification (SEI) to measure how familiar the LLM is with instruction data. Specifically, ICP evaluates the LLM's understanding of the given instruction by calculating the tailored consistency among multiple self-generated responses. SEI further assesses the familiarity of the LLM with the target response by comparing it to the generated responses, using the proposed semantic clustering and well-designed voting strategy. Finally, we introduce an expert-aligned reward model, considering characteristics beyond just familiarity to enhance data quality. By considering data quality and avoiding unfamiliar data, we can utilize the selected data to effectively align LLMs to follow instructions and hallucinate less. Extensive experiments and analysis show that NOVA significantly reduces hallucinations and allows LLMs to maintain a strong ability to follow instructions.
UltraIF: Advancing Instruction Following from the Wild
Feb 06, 2025



Instruction-following made modern large language models (LLMs) helpful assistants. However, the key to taming LLMs on complex instructions remains mysterious, for that there are huge gaps between models trained by open-source community and those trained by leading companies. To bridge the gap, we propose a simple and scalable approach UltraIF for building LLMs that can follow complex instructions with open-source data. UltraIF first decomposes real-world user prompts into simpler queries, constraints, and corresponding evaluation questions for the constraints. Then, we train an UltraComposer to compose constraint-associated prompts with evaluation questions. This prompt composer allows us to synthesize complicated instructions as well as filter responses with evaluation questions. In our experiment, for the first time, we successfully align LLaMA-3.1-8B-Base to catch up with its instruct version on 5 instruction-following benchmarks without any benchmark information, using only 8B model as response generator and evaluator. The aligned model also achieved competitive scores on other benchmarks. Moreover, we also show that UltraIF could further improve LLaMA-3.1-8B-Instruct through self-alignment, motivating broader use cases for the method. Our code will be available at https://github.com/kkk-an/UltraIF.
Selecting Influential Samples for Long Context Alignment via Homologous Models' Guidance and Contextual Awareness Measurement
Oct 21, 2024The expansion of large language models to effectively handle instructions with extremely long contexts has yet to be fully investigated. The primary obstacle lies in constructing a high-quality long instruction-following dataset devised for long context alignment. Existing studies have attempted to scale up the available data volume by synthesizing long instruction-following samples. However, indiscriminately increasing the quantity of data without a well-defined strategy for ensuring data quality may introduce low-quality samples and restrict the final performance. To bridge this gap, we aim to address the unique challenge of long-context alignment, i.e., modeling the long-range dependencies for handling instructions and lengthy input contexts. We propose GATEAU, a novel framework designed to identify the influential and high-quality samples enriched with long-range dependency relations by utilizing crafted Homologous Models' Guidance (HMG) and Contextual Awareness Measurement (CAM). Specifically, HMG attempts to measure the difficulty of generating corresponding responses due to the long-range dependencies, using the perplexity scores of the response from two homologous models with different context windows. Also, the role of CAM is to measure the difficulty of understanding the long input contexts due to long-range dependencies by evaluating whether the model's attention is focused on important segments. Built upon both proposed methods, we select the most challenging samples as the influential data to effectively frame the long-range dependencies, thereby achieving better performance of LLMs. Comprehensive experiments indicate that GATEAU effectively identifies samples enriched with long-range dependency relations and the model trained on these selected samples exhibits better instruction-following and long-context understanding capabilities.
Rethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
Sep 22, 2024Semantic Parsing aims to capture the meaning of a sentence and convert it into a logical, structured form. Previous studies show that semantic parsing enhances the performance of smaller models (e.g., BERT) on downstream tasks. However, it remains unclear whether the improvements extend similarly to LLMs. In this paper, our empirical findings reveal that, unlike smaller models, directly adding semantic parsing results into LLMs reduces their performance. To overcome this, we propose SENSE, a novel prompting approach that embeds semantic hints within the prompt. Experiments show that SENSE consistently improves LLMs' performance across various tasks, highlighting the potential of integrating semantic information to improve LLM capabilities.
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale
Jul 07, 2024



This paper presents UltraEdit, a large-scale (approximately 4 million editing samples), automatically generated dataset for instruction-based image editing. Our key idea is to address the drawbacks in existing image editing datasets like InstructPix2Pix and MagicBrush, and provide a systematic approach to producing massive and high-quality image editing samples. UltraEdit offers several distinct advantages: 1) It features a broader range of editing instructions by leveraging the creativity of large language models (LLMs) alongside in-context editing examples from human raters; 2) Its data sources are based on real images, including photographs and artworks, which provide greater diversity and reduced bias compared to datasets solely generated by text-to-image models; 3) It also supports region-based editing, enhanced by high-quality, automatically produced region annotations. Our experiments show that canonical diffusion-based editing baselines trained on UltraEdit set new records on MagicBrush and Emu-Edit benchmarks. Our analysis further confirms the crucial role of real image anchors and region-based editing data. The dataset, code, and models can be found in https://ultra-editing.github.io.
Thread: A Logic-Based Data Organization Paradigm for How-To Question Answering with Retrieval Augmented Generation
Jun 19, 2024
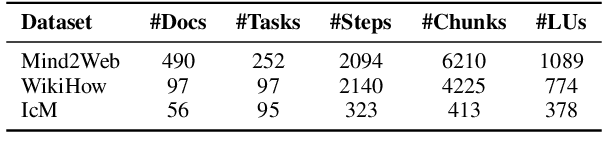
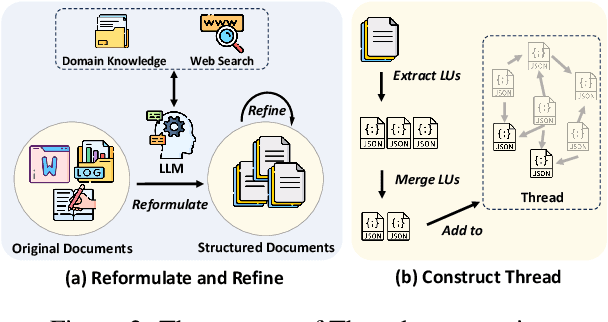
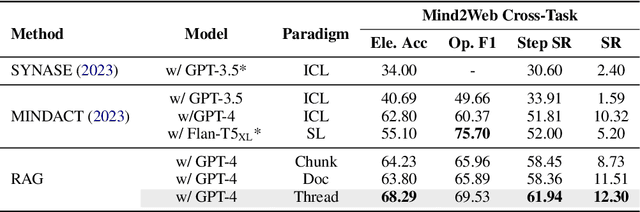
Current question answering systems leveraging retrieval augmented generation perform well in answering factoid questions but face challenges with non-factoid questions, particularly how-to queries requiring detailed step-by-step instructions and explanations. In this paper, we introduce Thread, a novel data organization paradigm that transforms documents into logic units based on their inter-connectivity. Extensive experiments across open-domain and industrial scenarios demonstrate that Thread outperforms existing data organization paradigms in RAG-based QA systems, significantly improving the handling of how-to questions.
LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Apr 16, 2024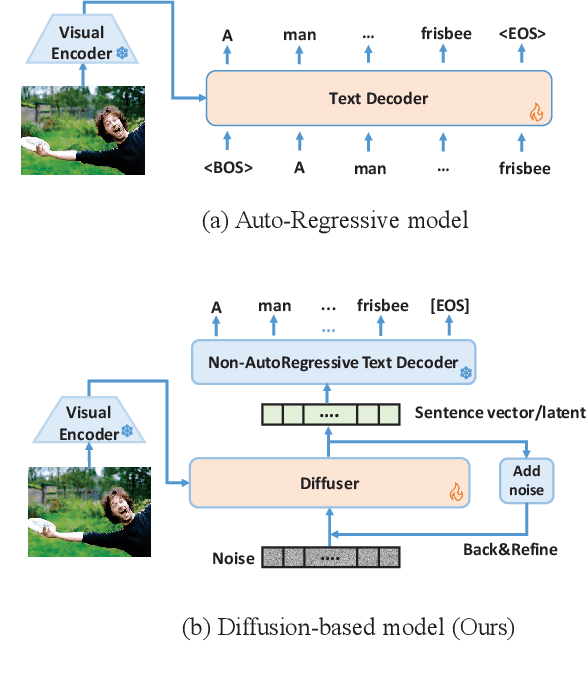
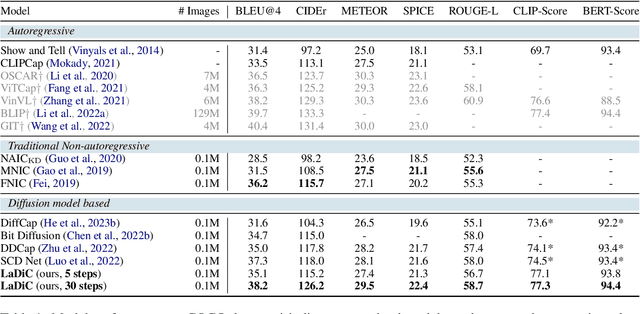
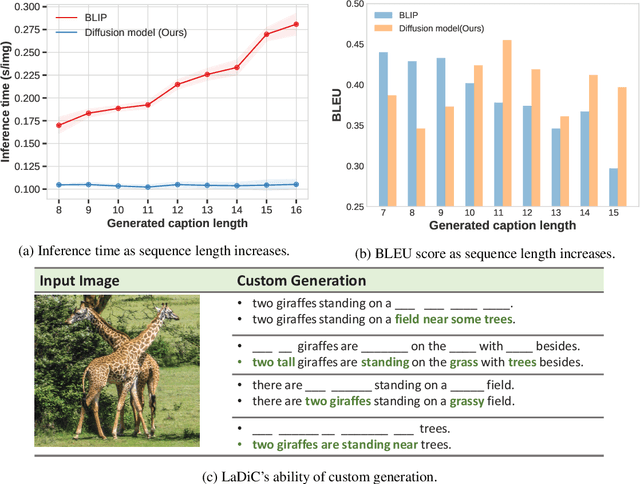
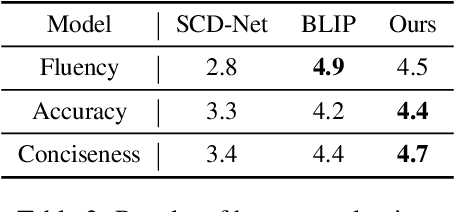
Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.
Mitigating Language-Level Performance Disparity in mPLMs via Teacher Language Selection and Cross-lingual Self-Distillation
Apr 12, 2024
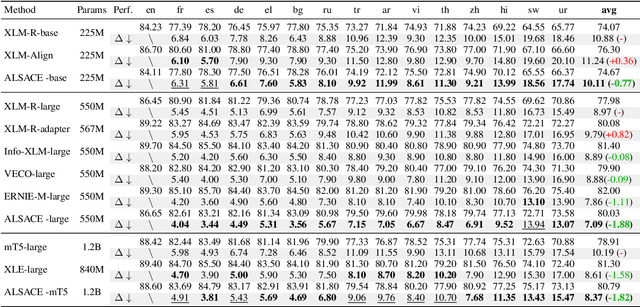
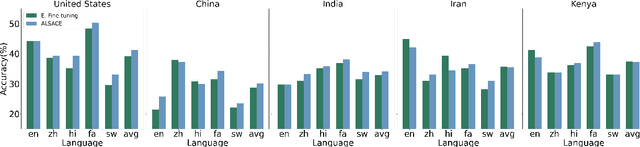
Large-scale multilingual Pretrained Language Models (mPLMs) yield impressive performance on cross-language tasks, yet significant performance disparities exist across different languages within the same mPLM. Previous studies endeavored to narrow these disparities by supervise fine-tuning the mPLMs with multilingual data. However, obtaining labeled multilingual data is time-consuming, and fine-tuning mPLM with limited labeled multilingual data merely encapsulates the knowledge specific to the labeled data. Therefore, we introduce ALSACE to leverage the learned knowledge from the well-performing languages to guide under-performing ones within the same mPLM, eliminating the need for additional labeled multilingual data. Experiments show that ALSACE effectively mitigates language-level performance disparity across various mPLMs while showing the competitive performance on different multilingual NLU tasks, ranging from full resource to limited resource settings. The code for our approach is available at https://github.com/pkunlp-icler/ALSACE.
Nissist: An Incident Mitigation Copilot based on Troubleshooting Guides
Feb 27, 2024Effective incident management is pivotal for the smooth operation of enterprises-level cloud services. In order to expedite incident mitigation, service teams compile troubleshooting knowledge into Troubleshooting Guides (TSGs) accessible to on-call engineers (OCEs). While automated pipelines are enabled to resolve the most frequent and easy incidents, there still exist complex incidents that require OCEs' intervention. However, TSGs are often unstructured and incomplete, which requires manual interpretation by OCEs, leading to on-call fatigue and decreased productivity, especially among new-hire OCEs. In this work, we propose Nissist which leverages TSGs and incident mitigation histories to provide proactive suggestions, reducing human intervention. Leveraging Large Language Models (LLM), Nissist extracts insights from unstructured TSGs and historical incident mitigation discussions, forming a comprehensive knowledge base. Its multi-agent system design enhances proficiency in precisely discerning user queries, retrieving relevant information, and delivering systematic plans consecutively. Through our user case and experiment, we demonstrate that Nissist significant reduce Time to Mitigate (TTM) in incident mitigation, alleviating operational burdens on OCEs and improving service reliability. Our demo is available at https://aka.ms/nissist_demo.
GAIA: Zero-shot Talking Avatar Generation
Nov 26, 2023



Zero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of the generated avatars. In this work, we introduce GAIA (Generative AI for Avatar), which eliminates the domain priors in talking avatar generation. In light of the observation that the speech only drives the motion of the avatar while the appearance of the avatar and the background typically remain the same throughout the entire video, we divide our approach into two stages: 1) disentangling each frame into motion and appearance representations; 2) generating motion sequences conditioned on the speech and reference portrait image. We collect a large-scale high-quality talking avatar dataset and train the model on it with different scales (up to 2B parameters). Experimental results verify the superiority, scalability, and flexibility of GAIA as 1) the resulting model beats previous baseline models in terms of naturalness, diversity, lip-sync quality, and visual quality; 2) the framework is scalable since larger models yield better results; 3) it is general and enables different applications like controllable talking avatar generation and text-instructed avatar generation.