 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
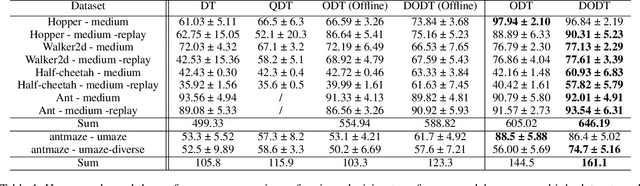
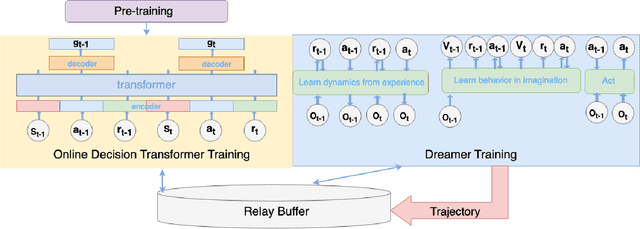
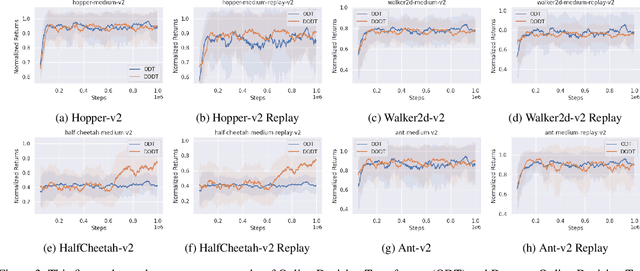
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale
Jul 07, 2024



This paper presents UltraEdit, a large-scale (approximately 4 million editing samples), automatically generated dataset for instruction-based image editing. Our key idea is to address the drawbacks in existing image editing datasets like InstructPix2Pix and MagicBrush, and provide a systematic approach to producing massive and high-quality image editing samples. UltraEdit offers several distinct advantages: 1) It features a broader range of editing instructions by leveraging the creativity of large language models (LLMs) alongside in-context editing examples from human raters; 2) Its data sources are based on real images, including photographs and artworks, which provide greater diversity and reduced bias compared to datasets solely generated by text-to-image models; 3) It also supports region-based editing, enhanced by high-quality, automatically produced region annotations. Our experiments show that canonical diffusion-based editing baselines trained on UltraEdit set new records on MagicBrush and Emu-Edit benchmarks. Our analysis further confirms the crucial role of real image anchors and region-based editing data. The dataset, code, and models can be found in https://ultra-editing.github.io.
Flow Priors for Linear Inverse Problems via Iterative Corrupted Trajectory Matching
May 29, 2024



Generative models based on flow matching have attracted significant attention for their simplicity and superior performance in high-resolution image synthesis. By leveraging the instantaneous change-of-variables formula, one can directly compute image likelihoods from a learned flow, making them enticing candidates as priors for downstream tasks such as inverse problems. In particular, a natural approach would be to incorporate such image probabilities in a maximum-a-posteriori (MAP) estimation problem. A major obstacle, however, lies in the slow computation of the log-likelihood, as it requires backpropagating through an ODE solver, which can be prohibitively slow for high-dimensional problems. In this work, we propose an iterative algorithm to approximate the MAP estimator efficiently to solve a variety of linear inverse problems. Our algorithm is mathematically justified by the observation that the MAP objective can be approximated by a sum of $N$ ``local MAP'' objectives, where $N$ is the number of function evaluations. By leveraging Tweedie's formula, we show that we can perform gradient steps to sequentially optimize these objectives. We validate our approach for various linear inverse problems, such as super-resolution, deblurring, inpainting, and compressed sensing, and demonstrate that we can outperform other methods based on flow matching.
Latent Energy-Based Odyssey: Black-Box Optimization via Expanded Exploration in the Energy-Based Latent Space
May 27, 2024Offline Black-Box Optimization (BBO) aims at optimizing a black-box function using the knowledge from a pre-collected offline dataset of function values and corresponding input designs. However, the high-dimensional and highly-multimodal input design space of black-box function pose inherent challenges for most existing methods that model and operate directly upon input designs. These issues include but are not limited to high sample complexity, which relates to inaccurate approximation of black-box function; and insufficient coverage and exploration of input design modes, which leads to suboptimal proposal of new input designs. In this work, we consider finding a latent space that serves as a compressed yet accurate representation of the design-value joint space, enabling effective latent exploration of high-value input design modes. To this end, we formulate an learnable energy-based latent space, and propose Noise-intensified Telescoping density-Ratio Estimation (NTRE) scheme for variational learning of an accurate latent space model without costly Markov Chain Monte Carlo. The optimization process is then exploration of high-value designs guided by the learned energy-based model in the latent space, formulated as gradient-based sampling from a latent-variable-parameterized inverse model. We show that our particular parameterization encourages expanded exploration around high-value design modes, motivated by inversion thinking of a fundamental result of conditional covariance matrix typically used for variance reduction. We observe that our method, backed by an accurately learned informative latent space and an expanding-exploration model design, yields significant improvements over strong previous methods on both synthetic and real world datasets such as the design-bench suite.
Watermarking Generative Tabular Data
May 22, 2024



In this paper, we introduce a simple yet effective tabular data watermarking mechanism with statistical guarantees. We show theoretically that the proposed watermark can be effectively detected, while faithfully preserving the data fidelity, and also demonstrates appealing robustness against additive noise attack. The general idea is to achieve the watermarking through a strategic embedding based on simple data binning. Specifically, it divides the feature's value range into finely segmented intervals and embeds watermarks into selected ``green list" intervals. To detect the watermarks, we develop a principled statistical hypothesis-testing framework with minimal assumptions: it remains valid as long as the underlying data distribution has a continuous density function. The watermarking efficacy is demonstrated through rigorous theoretical analysis and empirical validation, highlighting its utility in enhancing the security of synthetic and real-world datasets.
Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models
Apr 10, 2024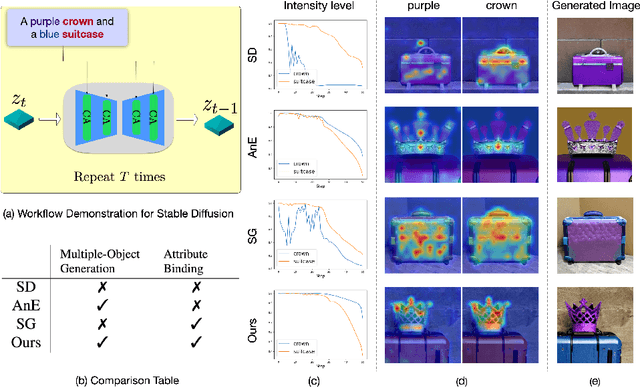



Text-to-image diffusion models have shown great success in generating high-quality text-guided images. Yet, these models may still fail to semantically align generated images with the provided text prompts, leading to problems like incorrect attribute binding and/or catastrophic object neglect. Given the pervasive object-oriented structure underlying text prompts, we introduce a novel object-conditioned Energy-Based Attention Map Alignment (EBAMA) method to address the aforementioned problems. We show that an object-centric attribute binding loss naturally emerges by approximately maximizing the log-likelihood of a $z$-parameterized energy-based model with the help of the negative sampling technique. We further propose an object-centric intensity regularizer to prevent excessive shifts of objects attention towards their attributes. Extensive qualitative and quantitative experiments, including human evaluation, on several challenging benchmarks demonstrate the superior performance of our method over previous strong counterparts. With better aligned attention maps, our approach shows great promise in further enhancing the text-controlled image editing ability of diffusion models.
Learning Energy-Based Prior Model with Diffusion-Amortized MCMC
Oct 05, 2023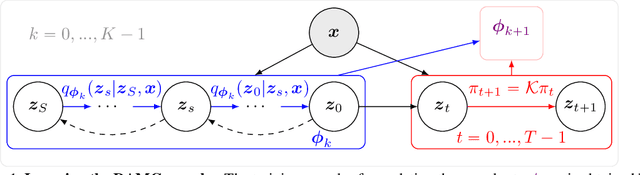
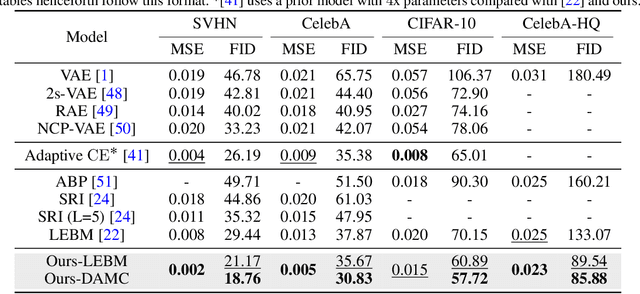

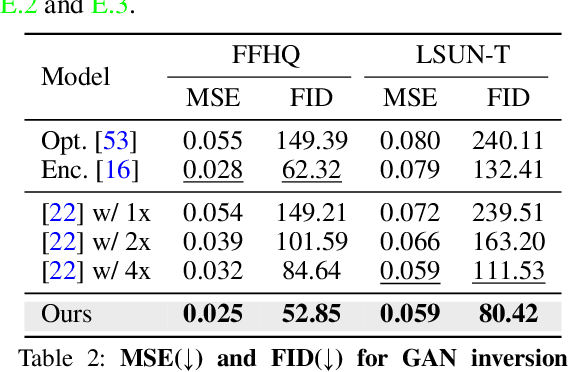
Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in the field of generative modeling due to its flexibility in the formulation and strong modeling power of the latent space. However, the common practice of learning latent space EBMs with non-convergent short-run MCMC for prior and posterior sampling is hindering the model from further progress; the degenerate MCMC sampling quality in practice often leads to degraded generation quality and instability in training, especially with highly multi-modal and/or high-dimensional target distributions. To remedy this sampling issue, in this paper we introduce a simple but effective diffusion-based amortization method for long-run MCMC sampling and develop a novel learning algorithm for the latent space EBM based on it. We provide theoretical evidence that the learned amortization of MCMC is a valid long-run MCMC sampler. Experiments on several image modeling benchmark datasets demonstrate the superior performance of our method compared with strong counterparts
Learning Concept-Based Visual Causal Transition and Symbolic Reasoning for Visual Planning
Oct 05, 2023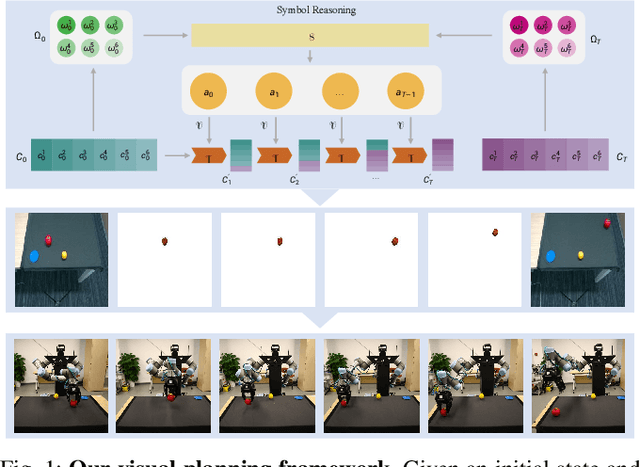
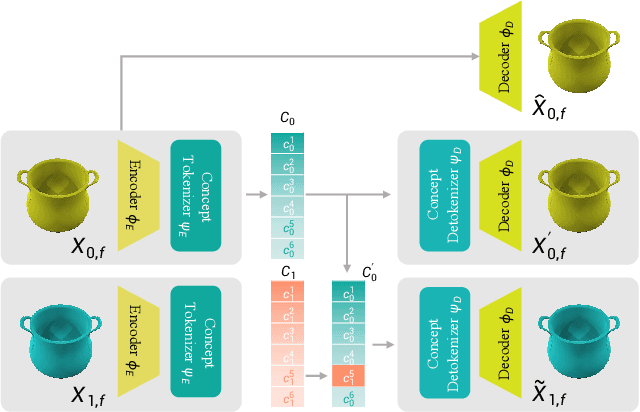


Visual planning simulates how humans make decisions to achieve desired goals in the form of searching for visual causal transitions between an initial visual state and a final visual goal state. It has become increasingly important in egocentric vision with its advantages in guiding agents to perform daily tasks in complex environments. In this paper, we propose an interpretable and generalizable visual planning framework consisting of i) a novel Substitution-based Concept Learner (SCL) that abstracts visual inputs into disentangled concept representations, ii) symbol abstraction and reasoning that performs task planning via the self-learned symbols, and iii) a Visual Causal Transition model (ViCT) that grounds visual causal transitions to semantically similar real-world actions. Given an initial state, we perform goal-conditioned visual planning with a symbolic reasoning method fueled by the learned representations and causal transitions to reach the goal state. To verify the effectiveness of the proposed model, we collect a large-scale visual planning dataset based on AI2-THOR, dubbed as CCTP. Extensive experiments on this challenging dataset demonstrate the superior performance of our method in visual task planning. Empirically, we show that our framework can generalize to unseen task trajectories and unseen object categories.
Latent Diffusion Energy-Based Model for Interpretable Text Modeling
Jun 14, 2022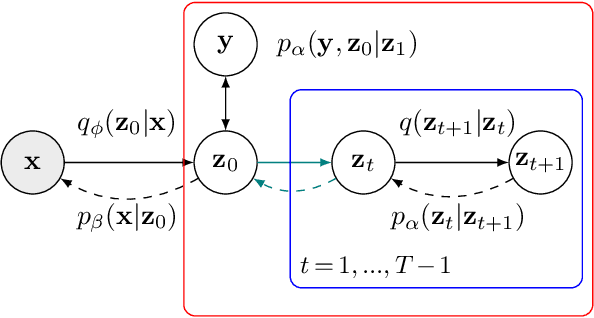
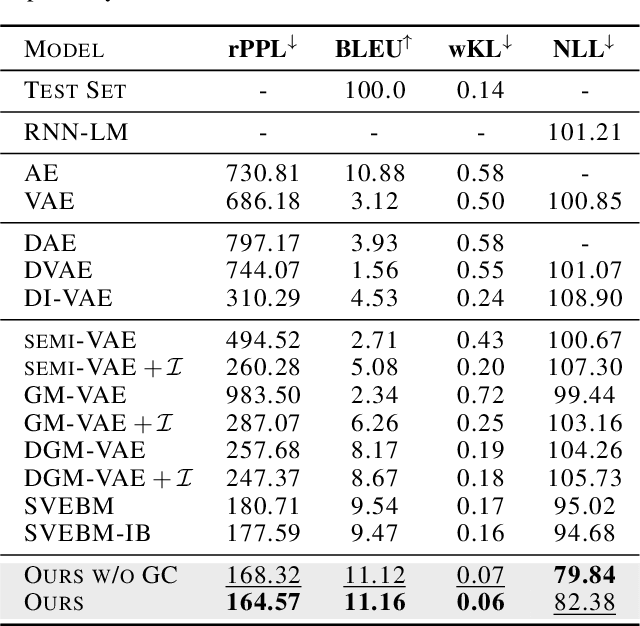
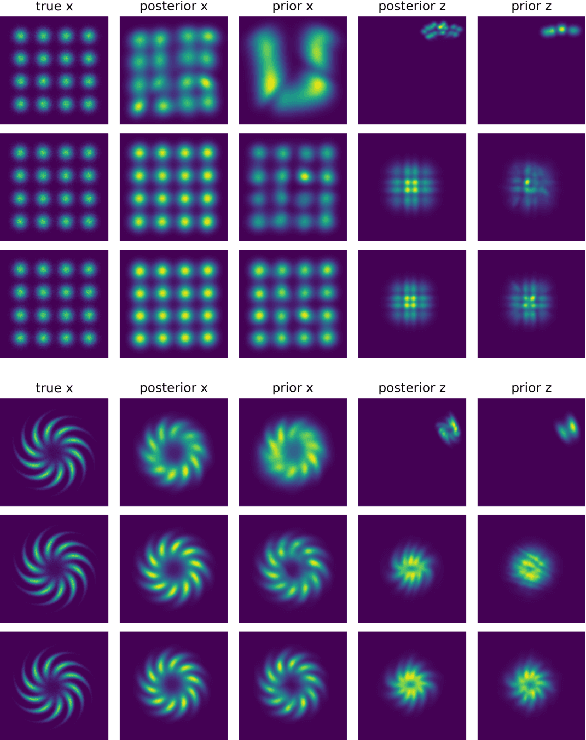

Latent space Energy-Based Models (EBMs), also known as energy-based priors, have drawn growing interests in generative modeling. Fueled by its flexibility in the formulation and strong modeling power of the latent space, recent works built upon it have made interesting attempts aiming at the interpretability of text modeling. However, latent space EBMs also inherit some flaws from EBMs in data space; the degenerate MCMC sampling quality in practice can lead to poor generation quality and instability in training, especially on data with complex latent structures. Inspired by the recent efforts that leverage diffusion recovery likelihood learning as a cure for the sampling issue, we introduce a novel symbiosis between the diffusion models and latent space EBMs in a variational learning framework, coined as the latent diffusion energy-based model. We develop a geometric clustering-based regularization jointly with the information bottleneck to further improve the quality of the learned latent space. Experiments on several challenging tasks demonstrate the superior performance of our model on interpretable text modeling over strong counterparts.
Unsupervised Foreground Extraction via Deep Region Competition
Nov 09, 2021



We present Deep Region Competition (DRC), an algorithm designed to extract foreground objects from images in a fully unsupervised manner. Foreground extraction can be viewed as a special case of generic image segmentation that focuses on identifying and disentangling objects from the background. In this work, we rethink the foreground extraction by reconciling energy-based prior with generative image modeling in the form of Mixture of Experts (MoE), where we further introduce the learned pixel re-assignment as the essential inductive bias to capture the regularities of background regions. With this modeling, the foreground-background partition can be naturally found through Expectation-Maximization (EM). We show that the proposed method effectively exploits the interaction between the mixture components during the partitioning process, which closely connects to region competition, a seminal approach for generic image segmentation. Experiments demonstrate that DRC exhibits more competitive performances on complex real-world data and challenging multi-object scenes compared with prior methods. Moreover, we show empirically that DRC can potentially generalize to novel foreground objects even from categories unseen during training.