 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Rethinking with Latent Thought Vectors for Math Reasoning
Feb 06, 2026Standard chain-of-thought reasoning generates a solution in a single forward pass, committing irrevocably to each token and lacking a mechanism to recover from early errors. We introduce Inference-Time Rethinking, a generative framework that enables iterative self-correction by decoupling declarative latent thought vectors from procedural generation. We factorize reasoning into a continuous latent thought vector (what to reason about) and a decoder that verbalizes the trace conditioned on this vector (how to reason). Beyond serving as a declarative buffer, latent thought vectors compress the reasoning structure into a continuous representation that abstracts away surface-level token variability, making gradient-based optimization over reasoning strategies well-posed. Our prior model maps unstructured noise to a learned manifold of valid reasoning patterns, and at test time we employ a Gibbs-style procedure that alternates between generating a candidate trace and optimizing the latent vector to better explain that trace, effectively navigating the latent manifold to refine the reasoning strategy. Training a 0.2B-parameter model from scratch on GSM8K, our method with 30 rethinking iterations surpasses baselines with 10 to 15 times more parameters, including a 3B counterpart. This result demonstrates that effective mathematical reasoning can emerge from sophisticated inference-time computation rather than solely from massive parameter counts.
Generative Actor Critic
Dec 25, 2025Conventional Reinforcement Learning (RL) algorithms, typically focused on estimating or maximizing expected returns, face challenges when refining offline pretrained models with online experiences. This paper introduces Generative Actor Critic (GAC), a novel framework that decouples sequential decision-making by reframing \textit{policy evaluation} as learning a generative model of the joint distribution over trajectories and returns, $p(τ, y)$, and \textit{policy improvement} as performing versatile inference on this learned model. To operationalize GAC, we introduce a specific instantiation based on a latent variable model that features continuous latent plan vectors. We develop novel inference strategies for both \textit{exploitation}, by optimizing latent plans to maximize expected returns, and \textit{exploration}, by sampling latent plans conditioned on dynamically adjusted target returns. Experiments on Gym-MuJoCo and Maze2D benchmarks demonstrate GAC's strong offline performance and significantly enhanced offline-to-online improvement compared to state-of-the-art methods, even in absence of step-wise rewards.
Reasoning Curriculum: Bootstrapping Broad LLM Reasoning from Math
Oct 30, 2025Reinforcement learning (RL) can elicit strong reasoning in large language models (LLMs), yet most open efforts focus on math and code. We propose Reasoning Curriculum, a simple two-stage curriculum that first elicits reasoning skills in pretraining-aligned domains such as math, then adapts and refines these skills across other domains via joint RL. Stage 1 performs a brief cold start and then math-only RL with verifiable rewards to develop reasoning skills. Stage 2 runs joint RL on mixed-domain data to transfer and consolidate these skills. The curriculum is minimal and backbone-agnostic, requiring no specialized reward models beyond standard verifiability checks. Evaluated on Qwen3-4B and Llama-3.1-8B over a multi-domain suite, reasoning curriculum yields consistent gains. Ablations and a cognitive-skill analysis indicate that both stages are necessary and that math-first elicitation increases cognitive behaviors important for solving complex problems. Reasoning Curriculum provides a compact, easy-to-adopt recipe for general reasoning.
Place Cells as Position Embeddings of Multi-Time Random Walk Transition Kernels for Path Planning
May 20, 2025The hippocampus orchestrates spatial navigation through collective place cell encodings that form cognitive maps. We reconceptualize the population of place cells as position embeddings approximating multi-scale symmetric random walk transition kernels: the inner product $\langle h(x, t), h(y, t) \rangle = q(y|x, t)$ represents normalized transition probabilities, where $h(x, t)$ is the embedding at location $ x $, and $q(y|x, t)$ is the normalized symmetric transition probability over time $t$. The time parameter $\sqrt{t}$ defines a spatial scale hierarchy, mirroring the hippocampal dorsoventral axis. $q(y|x, t)$ defines spatial adjacency between $x$ and $y$ at scale or resolution $\sqrt{t}$, and the pairwise adjacency relationships $(q(y|x, t), \forall x, y)$ are reduced into individual embeddings $(h(x, t), \forall x)$ that collectively form a map of the environment at sale $\sqrt{t}$. Our framework employs gradient ascent on $q(y|x, t) = \langle h(x, t), h(y, t)\rangle$ with adaptive scale selection, choosing the time scale with maximal gradient at each step for trap-free, smooth trajectories. Efficient matrix squaring $P_{2t} = P_t^2$ builds global representations from local transitions $P_1$ without memorizing past trajectories, enabling hippocampal preplay-like path planning. This produces robust navigation through complex environments, aligning with hippocampal navigation. Experimental results show that our model captures place cell properties -- field size distribution, adaptability, and remapping -- while achieving computational efficiency. By modeling collective transition probabilities rather than individual place fields, we offer a biologically plausible, scalable framework for spatial navigation.
Latent Adaptive Planner for Dynamic Manipulation
May 06, 2025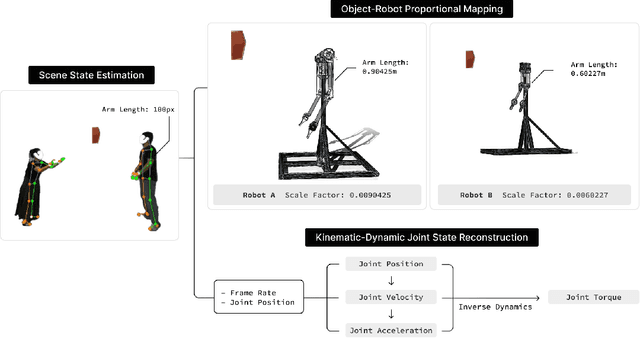
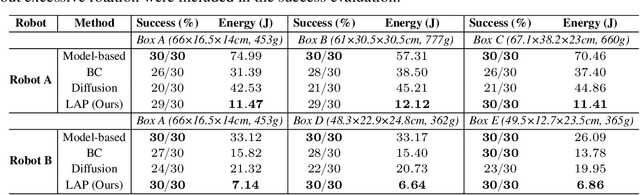
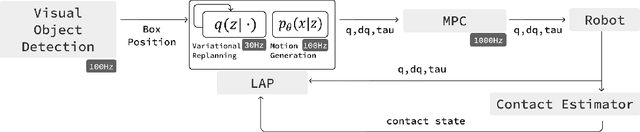

This paper presents Latent Adaptive Planner (LAP), a novel approach for dynamic nonprehensile manipulation tasks that formulates planning as latent space inference, effectively learned from human demonstration videos. Our method addresses key challenges in visuomotor policy learning through a principled variational replanning framework that maintains temporal consistency while efficiently adapting to environmental changes. LAP employs Bayesian updating in latent space to incrementally refine plans as new observations become available, striking an optimal balance between computational efficiency and real-time adaptability. We bridge the embodiment gap between humans and robots through model-based proportional mapping that regenerates accurate kinematic-dynamic joint states and object positions from human demonstrations. Experimental evaluations across multiple complex manipulation benchmarks demonstrate that LAP achieves state-of-the-art performance, outperforming existing approaches in success rate, trajectory smoothness, and energy efficiency, particularly in dynamic adaptation scenarios. Our approach enables robots to perform complex interactions with human-like adaptability while providing an expandable framework applicable to diverse robotic platforms using the same human demonstration videos.
Scalable Language Models with Posterior Inference of Latent Thought Vectors
Feb 03, 2025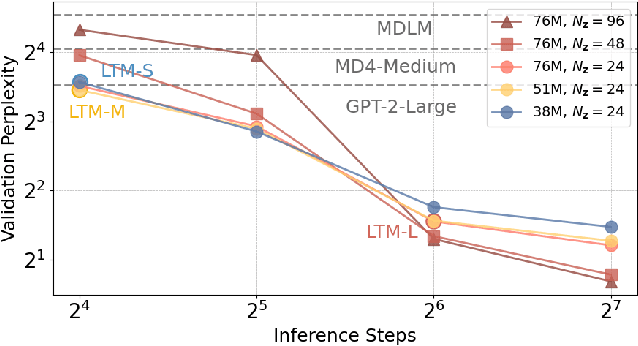
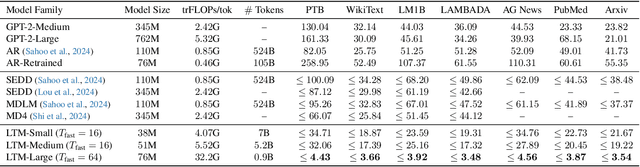
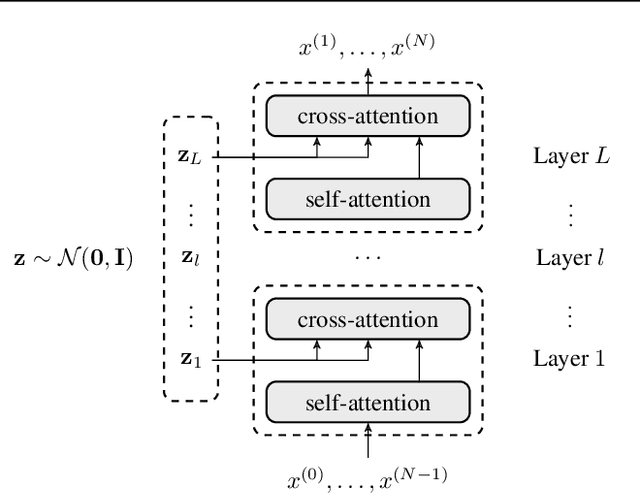
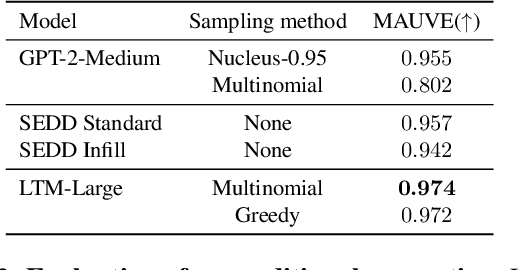
We propose a novel family of language models, Latent-Thought Language Models (LTMs), which incorporate explicit latent thought vectors that follow an explicit prior model in latent space. These latent thought vectors guide the autoregressive generation of ground tokens through a Transformer decoder. Training employs a dual-rate optimization process within the classical variational Bayes framework: fast learning of local variational parameters for the posterior distribution of latent vectors, and slow learning of global decoder parameters. Empirical studies reveal that LTMs possess additional scaling dimensions beyond traditional LLMs, yielding a structured design space. Higher sample efficiency can be achieved by increasing training compute per token, with further gains possible by trading model size for more inference steps. Designed based on these scaling properties, LTMs demonstrate superior sample and parameter efficiency compared to conventional autoregressive models and discrete diffusion models. They significantly outperform these counterparts in validation perplexity and zero-shot language modeling. Additionally, LTMs exhibit emergent few-shot in-context reasoning capabilities that scale with model and latent size, and achieve competitive performance in conditional and unconditional text generation.
A minimalistic representation model for head direction system
Nov 15, 2024



We present a minimalistic representation model for the head direction (HD) system, aiming to learn a high-dimensional representation of head direction that captures essential properties of HD cells. Our model is a representation of rotation group $U(1)$, and we study both the fully connected version and convolutional version. We demonstrate the emergence of Gaussian-like tuning profiles and a 2D circle geometry in both versions of the model. We also demonstrate that the learned model is capable of accurate path integration.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
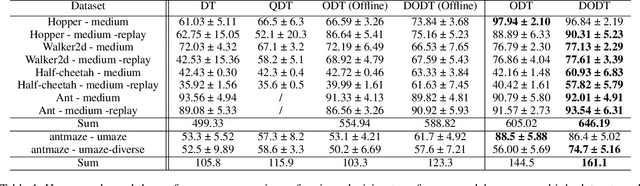
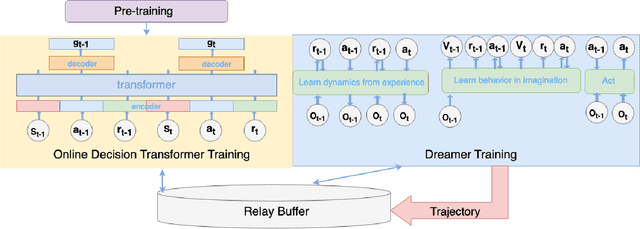
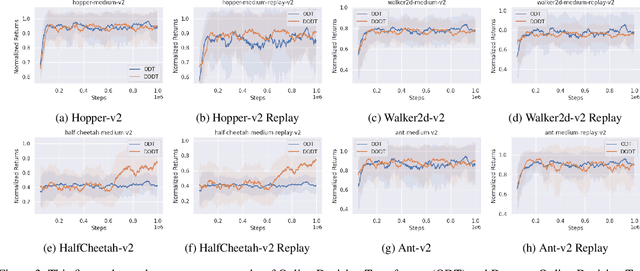
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
Latent Space Energy-based Neural ODEs
Sep 05, 2024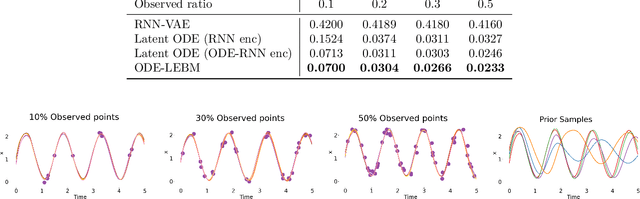


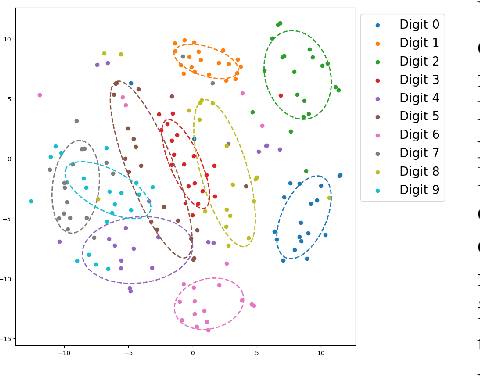
This paper introduces a novel family of deep dynamical models designed to represent continuous-time sequence data. This family of models generates each data point in the time series by a neural emission model, which is a non-linear transformation of a latent state vector. The trajectory of the latent states is implicitly described by a neural ordinary differential equation (ODE), with the initial state following an informative prior distribution parameterized by an energy-based model. Furthermore, we can extend this model to disentangle dynamic states from underlying static factors of variation, represented as time-invariant variables in the latent space. We train the model using maximum likelihood estimation with Markov chain Monte Carlo (MCMC) in an end-to-end manner, without requiring additional assisting components such as an inference network. Our experiments on oscillating systems, videos and real-world state sequences (MuJoCo) illustrate that ODEs with the learnable energy-based prior outperform existing counterparts, and can generalize to new dynamic parameterization, enabling long-horizon predictions.
Latent Energy-Based Odyssey: Black-Box Optimization via Expanded Exploration in the Energy-Based Latent Space
May 27, 2024Offline Black-Box Optimization (BBO) aims at optimizing a black-box function using the knowledge from a pre-collected offline dataset of function values and corresponding input designs. However, the high-dimensional and highly-multimodal input design space of black-box function pose inherent challenges for most existing methods that model and operate directly upon input designs. These issues include but are not limited to high sample complexity, which relates to inaccurate approximation of black-box function; and insufficient coverage and exploration of input design modes, which leads to suboptimal proposal of new input designs. In this work, we consider finding a latent space that serves as a compressed yet accurate representation of the design-value joint space, enabling effective latent exploration of high-value input design modes. To this end, we formulate an learnable energy-based latent space, and propose Noise-intensified Telescoping density-Ratio Estimation (NTRE) scheme for variational learning of an accurate latent space model without costly Markov Chain Monte Carlo. The optimization process is then exploration of high-value designs guided by the learned energy-based model in the latent space, formulated as gradient-based sampling from a latent-variable-parameterized inverse model. We show that our particular parameterization encourages expanded exploration around high-value design modes, motivated by inversion thinking of a fundamental result of conditional covariance matrix typically used for variance reduction. We observe that our method, backed by an accurately learned informative latent space and an expanding-exploration model design, yields significant improvements over strong previous methods on both synthetic and real world datasets such as the design-bench suite.