 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Plan Transformer: Planning as Latent Variable Inference
Paper and Code
Feb 07, 2024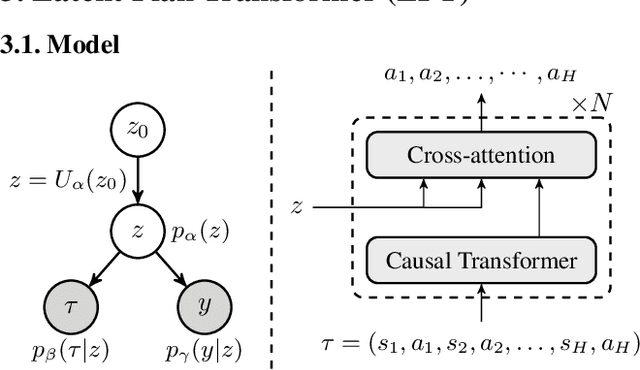
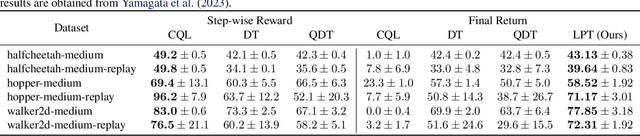

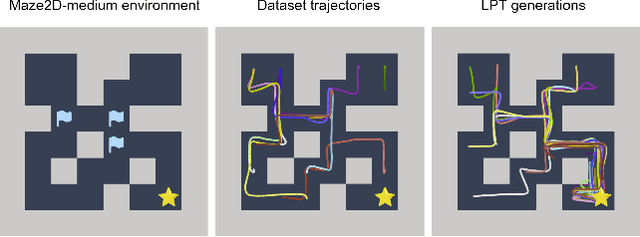
In tasks aiming for long-term returns, planning becomes necessary. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent space to connect a Transformer-based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally gathers sub-trajectories to form a consistent abstraction despite the finite context. During test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. It then guides the autoregressive policy throughout the episode, functioning as a plan. Our experiments demonstrate that LPT can discover improved decisions from suboptimal trajectories. It achieves competitive performance across several benchmarks, including Gym-Mujoco, Maze2D, and Connect Four, exhibiting capabilities of nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.