 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining datasets with different ground truths using Low-Rank Adaptation to generalize image-based CNN models for photometric redshift prediction
Jan 01, 2026In this work, we demonstrate how Low-Rank Adaptation (LoRA) can be used to combine different galaxy imaging datasets to improve redshift estimation with CNN models for cosmology. LoRA is an established technique for large language models that adds adapter networks to adjust model weights and biases to efficiently fine-tune large base models without retraining. We train a base model using a photometric redshift ground truth dataset, which contains broad galaxy types but is less accurate. We then fine-tune using LoRA on a spectroscopic redshift ground truth dataset. These redshifts are more accurate but limited to bright galaxies and take orders of magnitude more time to obtain, so are less available for large surveys. Ideally, the combination of the two datasets would yield more accurate models that generalize well. The LoRA model performs better than a traditional transfer learning method, with $\sim2.5\times$ less bias and $\sim$2.2$\times$ less scatter. Retraining the model on a combined dataset yields a model that generalizes better than LoRA but at a cost of greater computation time. Our work shows that LoRA is useful for fine-tuning regression models in astrophysics by providing a middle ground between full retraining and no retraining. LoRA shows potential in allowing us to leverage existing pretrained astrophysical models, especially for data sparse tasks.
Multi-Modal Masked Autoencoders for Learning Image-Spectrum Associations for Galaxy Evolution and Cosmology
Oct 26, 2025Upcoming surveys will produce billions of galaxy images but comparatively few spectra, motivating models that learn cross-modal representations. We build a dataset of 134,533 galaxy images (HSC-PDR2) and spectra (DESI-DR1) and adapt a Multi-Modal Masked Autoencoder (MMAE) to embed both images and spectra in a shared representation. The MMAE is a transformer-based architecture, which we train by masking 75% of the data and reconstructing missing image and spectral tokens. We use this model to test three applications: spectral and image reconstruction from heavily masked data and redshift regression from images alone. It recovers key physical features, such as galaxy shapes, atomic emission line peaks, and broad continuum slopes, though it struggles with fine image details and line strengths. For redshift regression, the MMAE performs comparably or better than prior multi-modal models in terms of prediction scatter even when missing spectra in testing. These results highlight both the potential and limitations of masked autoencoders in astrophysics and motivate extensions to additional modalities, such as text, for foundation models.
Latent Adaptive Planner for Dynamic Manipulation
May 06, 2025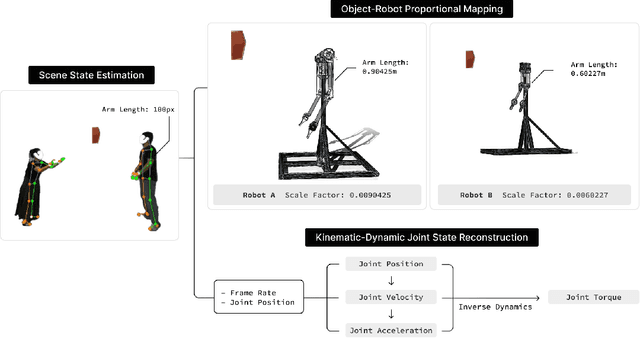
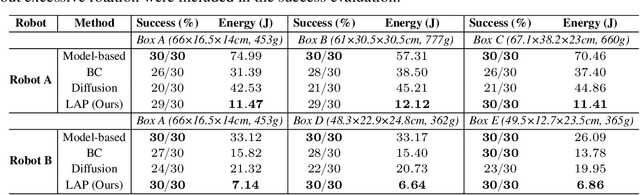
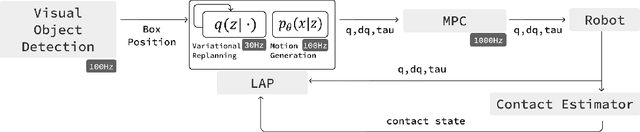

This paper presents Latent Adaptive Planner (LAP), a novel approach for dynamic nonprehensile manipulation tasks that formulates planning as latent space inference, effectively learned from human demonstration videos. Our method addresses key challenges in visuomotor policy learning through a principled variational replanning framework that maintains temporal consistency while efficiently adapting to environmental changes. LAP employs Bayesian updating in latent space to incrementally refine plans as new observations become available, striking an optimal balance between computational efficiency and real-time adaptability. We bridge the embodiment gap between humans and robots through model-based proportional mapping that regenerates accurate kinematic-dynamic joint states and object positions from human demonstrations. Experimental evaluations across multiple complex manipulation benchmarks demonstrate that LAP achieves state-of-the-art performance, outperforming existing approaches in success rate, trajectory smoothness, and energy efficiency, particularly in dynamic adaptation scenarios. Our approach enables robots to perform complex interactions with human-like adaptability while providing an expandable framework applicable to diverse robotic platforms using the same human demonstration videos.
Better Prompt Compression Without Multi-Layer Perceptrons
Jan 12, 2025



Prompt compression is a promising approach to speeding up language model inference without altering the generative model. Prior works compress prompts into smaller sequences of learned tokens using an encoder that is trained as a LowRank Adaptation (LoRA) of the inference language model. However, we show that the encoder does not need to keep the original language model's architecture to achieve useful compression. We introduce the Attention-Only Compressor (AOC), which learns a prompt compression encoder after removing the multilayer perceptron (MLP) layers in the Transformer blocks of a language model, resulting in an encoder with roughly 67% less parameters compared to the original model. Intriguingly we find that, across a range of compression ratios up to 480x, AOC can better regenerate prompts and outperform a baseline compression encoder that is a LoRA of the inference language model without removing MLP layers. These results demonstrate that the architecture of prompt compression encoders does not need to be identical to that of the original decoder language model, paving the way for further research into architectures and approaches for prompt compression.
Learning the Evolution of Physical Structure of Galaxies via Diffusion Models
Nov 27, 2024



In astrophysics, understanding the evolution of galaxies in primarily through imaging data is fundamental to comprehending the formation of the Universe. This paper introduces a novel approach to conditioning Denoising Diffusion Probabilistic Models (DDPM) on redshifts for generating galaxy images. We explore whether this advanced generative model can accurately capture the physical characteristics of galaxies based solely on their images and redshift measurements. Our findings demonstrate that this model not only produces visually realistic galaxy images but also encodes the underlying changes in physical properties with redshift that are the result of galaxy evolution. This approach marks a significant advancement in using generative models to enhance our scientific insight into cosmic phenomena.
Unlocking the Potential of Text-to-Image Diffusion with PAC-Bayesian Theory
Nov 25, 2024
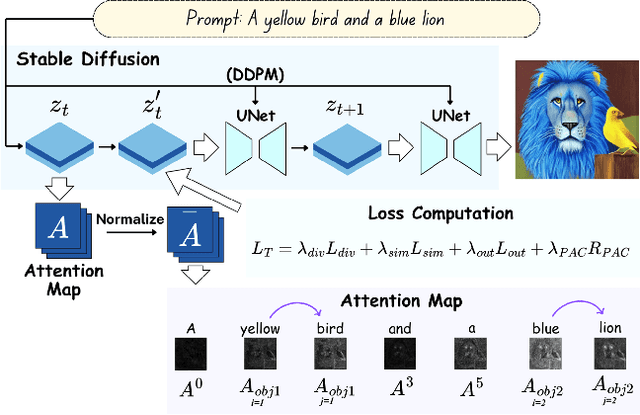
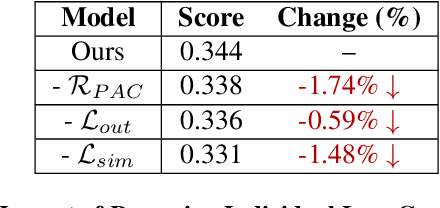

Text-to-image (T2I) diffusion models have revolutionized generative modeling by producing high-fidelity, diverse, and visually realistic images from textual prompts. Despite these advances, existing models struggle with complex prompts involving multiple objects and attributes, often misaligning modifiers with their corresponding nouns or neglecting certain elements. Recent attention-based methods have improved object inclusion and linguistic binding, but still face challenges such as attribute misbinding and a lack of robust generalization guarantees. Leveraging the PAC-Bayes framework, we propose a Bayesian approach that designs custom priors over attention distributions to enforce desirable properties, including divergence between objects, alignment between modifiers and their corresponding nouns, minimal attention to irrelevant tokens, and regularization for better generalization. Our approach treats the attention mechanism as an interpretable component, enabling fine-grained control and improved attribute-object alignment. We demonstrate the effectiveness of our method on standard benchmarks, achieving state-of-the-art results across multiple metrics. By integrating custom priors into the denoising process, our method enhances image quality and addresses long-standing challenges in T2I diffusion models, paving the way for more reliable and interpretable generative models.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024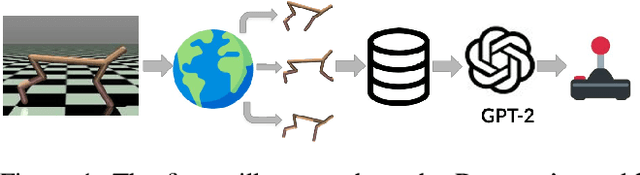
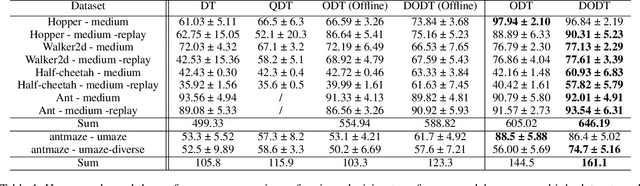
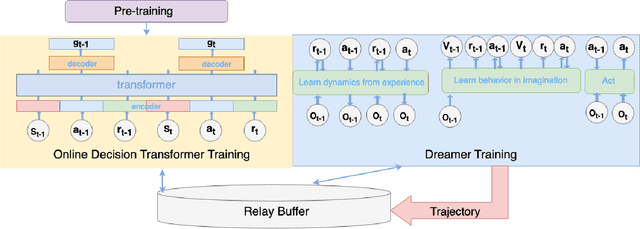
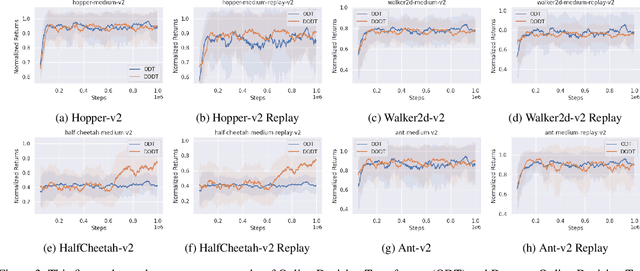
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
Latent Plan Transformer: Planning as Latent Variable Inference
Feb 07, 2024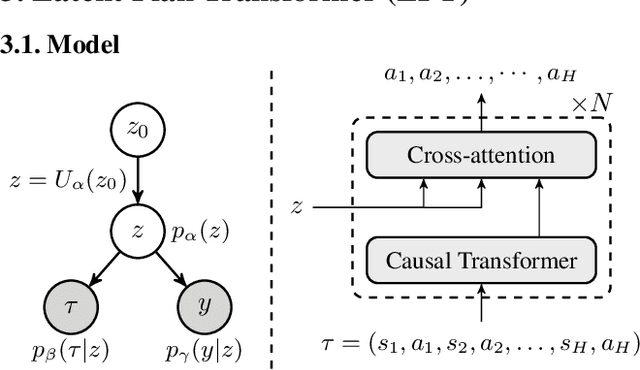
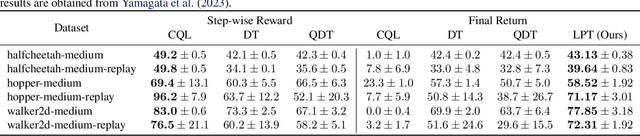

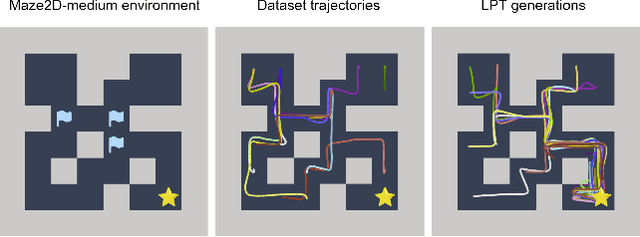
In tasks aiming for long-term returns, planning becomes necessary. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent space to connect a Transformer-based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally gathers sub-trajectories to form a consistent abstraction despite the finite context. During test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. It then guides the autoregressive policy throughout the episode, functioning as a plan. Our experiments demonstrate that LPT can discover improved decisions from suboptimal trajectories. It achieves competitive performance across several benchmarks, including Gym-Mujoco, Maze2D, and Connect Four, exhibiting capabilities of nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.
SDSRA: A Skill-Driven Skill-Recombination Algorithm for Efficient Policy Learning
Dec 06, 2023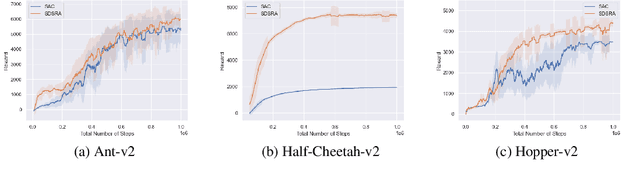
In this paper, we introduce a novel algorithm - the Skill-Driven Skill Recombination Algorithm (SDSRA) - an innovative framework that significantly enhances the efficiency of achieving maximum entropy in reinforcement learning tasks. We find that SDSRA achieves faster convergence compared to the traditional Soft Actor-Critic (SAC) algorithm and produces improved policies. By integrating skill-based strategies within the robust Actor-Critic framework, SDSRA demonstrates remarkable adaptability and performance across a wide array of complex and diverse benchmarks.
Differentiable VQ-VAE's for Robust White Matter Streamline Encodings
Nov 18, 2023



Given the complex geometry of white matter streamlines, Autoencoders have been proposed as a dimension-reduction tool to simplify the analysis streamlines in a low-dimensional latent spaces. However, despite these recent successes, the majority of encoder architectures only perform dimension reduction on single streamlines as opposed to a full bundle of streamlines. This is a severe limitation of the encoder architecture that completely disregards the global geometric structure of streamlines at the expense of individual fibers. Moreover, the latent space may not be well structured which leads to doubt into their interpretability. In this paper we propose a novel Differentiable Vector Quantized Variational Autoencoder, which are engineered to ingest entire bundles of streamlines as single data-point and provides reliable trustworthy encodings that can then be later used to analyze streamlines in the latent space. Comparisons with several state of the art Autoencoders demonstrate superior performance in both encoding and synthesis.