 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Task Success: Behavioral and Representational Diagnostics for WAM and VLA
May 31, 2026Vision-language-action (VLA) policies and World-Action Models (WAM) represent two increasingly important paradigms for robotic manipulation. However, it remains unclear whether future prediction in WAMs leads to behaviorally meaningful improvements beyond final task success. In this paper, we ask whether WAMs merely add future prediction, or whether they change robot behavior and internal representations in ways that are actionable for control. We introduce a model-agnostic diagnostic framework that compares WAMs and VLAs through two complementary lenses: behavioral rollout analysis and sparse-autoencoder-based feature analysis. The behavioral protocol measures action dynamics consistency, target-object progress, distractor disturbance, and runtime cost. The feature-space protocol characterizes internal representations as memorized, reactive, or predictive, revealing whether models encode future-oriented structure. Across LIBERO and RoboTwin2.0, we evaluate 7 policies spanning direct VLAs and joint, sequential, and auxiliary WAMs. Our results show that success alone hides key differences: WAMs often improve object-level behavior and target selectivity, but their gains depend on architecture and incur higher inference cost. Sequential WAMs show the clearest predictive structure, while auxiliary and joint WAMs respectively compress or entangle future information. These findings suggest future directions for WAMs design to preserve behaviorally actionable future representations for efficient manipulation.
EA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection
Feb 19, 2026Recent advances in foundation video generators such as Sora2, Veo3, and other commercial systems have produced highly realistic synthetic videos, exposing the limitations of existing detection methods that rely on shallow embedding trajectories, image-based adaptation, or computationally heavy MLLMs. We propose EA-Swin, an Embedding-Agnostic Swin Transformer that models spatiotemporal dependencies directly on pretrained video embeddings via a factorized windowed attention design, making it compatible with generic ViT-style patch-based encoders. Alongside the model, we construct the EA-Video dataset, a benchmark dataset comprising 130K videos that integrates newly collected samples with curated existing datasets, covering diverse commercial and open-source generators and including unseen-generator splits for rigorous cross-distribution evaluation. Extensive experiments show that EA-Swin achieves 0.97-0.99 accuracy across major generators, outperforming prior SoTA methods (typically 0.8-0.9) by a margin of 5-20%, while maintaining strong generalization to unseen distributions, establishing a scalable and robust solution for modern AI-generated video detection.
Improving Generalization and Uncertainty Quantification of Photometric Redshift Models
Jan 23, 2026Accurate redshift estimates are a vital component in understanding galaxy evolution and precision cosmology. In this paper, we explore approaches to increase the applicability of machine learning models for photometric redshift estimation on a broader range of galaxy types. Typical models are trained with ground-truth redshifts from spectroscopy. We test the utility and effectiveness of two approaches for combining spectroscopic redshifts and redshifts derived from multiband ($\sim$35 filters) photometry, which sample different types of galaxies compared to spectroscopic surveys. The two approaches are (1) training on a composite dataset and (2) transfer learning from one dataset to another. We compile photometric redshifts from the COSMOS2020 catalog (TransferZ) to complement an established spectroscopic redshift dataset (GalaxiesML). We used two architectures, deterministic neural networks (NN) and Bayesian neural networks (BNN), to examine and evaluate their performance with respect to the Legacy Survey of Space and Time (LSST) photo-$z$ science requirements. We also use split conformal prediction for calibrating uncertainty estimates and producing prediction intervals for the BNN and NN, respectively. We find that a NN trained on a composite dataset predicts photo-$z$'s that are 4.5 times less biased within the redshift range $0.3<z<1.5$, 1.1 times less scattered, and has a 1.4 times lower outlier rate than a model trained on only spectroscopic ground truths. We also find that BNNs produce reliable uncertainty estimates, but are sensitive to the different ground truths. This investigation leverages different sources of ground truths to develop models that can accurately predict photo-$z$'s for a broader population of galaxies crucial for surveys such as Euclid and LSST.
Combining datasets with different ground truths using Low-Rank Adaptation to generalize image-based CNN models for photometric redshift prediction
Jan 01, 2026In this work, we demonstrate how Low-Rank Adaptation (LoRA) can be used to combine different galaxy imaging datasets to improve redshift estimation with CNN models for cosmology. LoRA is an established technique for large language models that adds adapter networks to adjust model weights and biases to efficiently fine-tune large base models without retraining. We train a base model using a photometric redshift ground truth dataset, which contains broad galaxy types but is less accurate. We then fine-tune using LoRA on a spectroscopic redshift ground truth dataset. These redshifts are more accurate but limited to bright galaxies and take orders of magnitude more time to obtain, so are less available for large surveys. Ideally, the combination of the two datasets would yield more accurate models that generalize well. The LoRA model performs better than a traditional transfer learning method, with $\sim2.5\times$ less bias and $\sim$2.2$\times$ less scatter. Retraining the model on a combined dataset yields a model that generalizes better than LoRA but at a cost of greater computation time. Our work shows that LoRA is useful for fine-tuning regression models in astrophysics by providing a middle ground between full retraining and no retraining. LoRA shows potential in allowing us to leverage existing pretrained astrophysical models, especially for data sparse tasks.
Multi-Modal Masked Autoencoders for Learning Image-Spectrum Associations for Galaxy Evolution and Cosmology
Oct 26, 2025Upcoming surveys will produce billions of galaxy images but comparatively few spectra, motivating models that learn cross-modal representations. We build a dataset of 134,533 galaxy images (HSC-PDR2) and spectra (DESI-DR1) and adapt a Multi-Modal Masked Autoencoder (MMAE) to embed both images and spectra in a shared representation. The MMAE is a transformer-based architecture, which we train by masking 75% of the data and reconstructing missing image and spectral tokens. We use this model to test three applications: spectral and image reconstruction from heavily masked data and redshift regression from images alone. It recovers key physical features, such as galaxy shapes, atomic emission line peaks, and broad continuum slopes, though it struggles with fine image details and line strengths. For redshift regression, the MMAE performs comparably or better than prior multi-modal models in terms of prediction scatter even when missing spectra in testing. These results highlight both the potential and limitations of masked autoencoders in astrophysics and motivate extensions to additional modalities, such as text, for foundation models.
Learning the Evolution of Physical Structure of Galaxies via Diffusion Models
Nov 27, 2024



In astrophysics, understanding the evolution of galaxies in primarily through imaging data is fundamental to comprehending the formation of the Universe. This paper introduces a novel approach to conditioning Denoising Diffusion Probabilistic Models (DDPM) on redshifts for generating galaxy images. We explore whether this advanced generative model can accurately capture the physical characteristics of galaxies based solely on their images and redshift measurements. Our findings demonstrate that this model not only produces visually realistic galaxy images but also encodes the underlying changes in physical properties with redshift that are the result of galaxy evolution. This approach marks a significant advancement in using generative models to enhance our scientific insight into cosmic phenomena.
Using different sources of ground truths and transfer learning to improve the generalization of photometric redshift estimation
Nov 27, 2024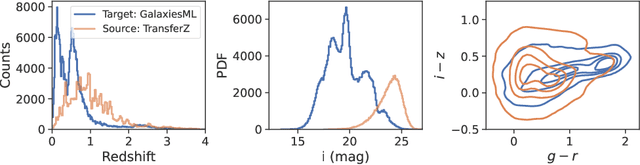
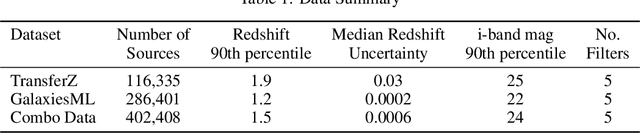
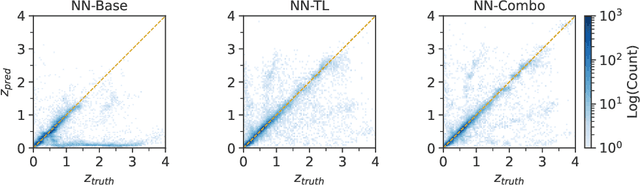
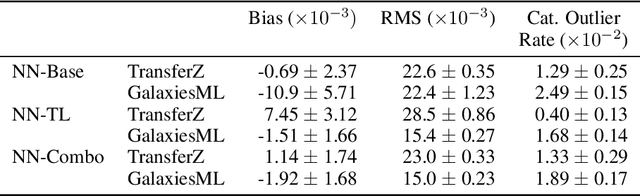
In this work, we explore methods to improve galaxy redshift predictions by combining different ground truths. Traditional machine learning models rely on training sets with known spectroscopic redshifts, which are precise but only represent a limited sample of galaxies. To make redshift models more generalizable to the broader galaxy population, we investigate transfer learning and directly combining ground truth redshifts derived from photometry and spectroscopy. We use the COSMOS2020 survey to create a dataset, TransferZ, which includes photometric redshift estimates derived from up to 35 imaging filters using template fitting. This dataset spans a wider range of galaxy types and colors compared to spectroscopic samples, though its redshift estimates are less accurate. We first train a base neural network on TransferZ and then refine it using transfer learning on a dataset of galaxies with more precise spectroscopic redshifts (GalaxiesML). In addition, we train a neural network on a combined dataset of TransferZ and GalaxiesML. Both methods reduce bias by $\sim$ 5x, RMS error by $\sim$ 1.5x, and catastrophic outlier rates by 1.3x on GalaxiesML, compared to a baseline trained only on TransferZ. However, we also find a reduction in performance for RMS and bias when evaluated on TransferZ data. Overall, our results demonstrate these approaches can meet cosmological requirements.
Using Galaxy Evolution as Source of Physics-Based Ground Truth for Generative Models
Jul 09, 2024
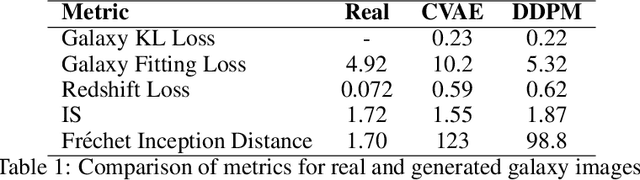


Generative models producing images have enormous potential to advance discoveries across scientific fields and require metrics capable of quantifying the high dimensional output. We propose that astrophysics data, such as galaxy images, can test generative models with additional physics-motivated ground truths in addition to human judgment. For example, galaxies in the Universe form and change over billions of years, following physical laws and relationships that are both easy to characterize and difficult to encode in generative models. We build a conditional denoising diffusion probabilistic model (DDPM) and a conditional variational autoencoder (CVAE) and test their ability to generate realistic galaxies conditioned on their redshifts (galaxy ages). This is one of the first studies to probe these generative models using physically motivated metrics. We find that both models produce comparable realistic galaxies based on human evaluation, but our physics-based metrics are better able to discern the strengths and weaknesses of the generative models. Overall, the DDPM model performs better than the CVAE on the majority of the physics-based metrics. Ultimately, if we can show that generative models can learn the physics of galaxy evolution, they have the potential to unlock new astrophysical discoveries.
Elements of effective machine learning datasets in astronomy
Nov 29, 2022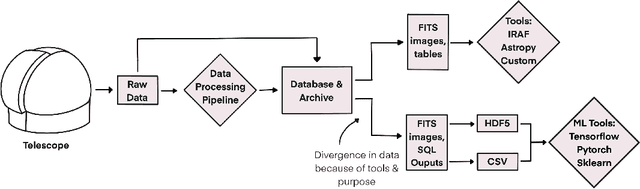
In this work, we identify elements of effective machine learning datasets in astronomy and present suggestions for their design and creation. Machine learning has become an increasingly important tool for analyzing and understanding the large-scale flood of data in astronomy. To take advantage of these tools, datasets are required for training and testing. However, building machine learning datasets for astronomy can be challenging. Astronomical data is collected from instruments built to explore science questions in a traditional fashion rather than to conduct machine learning. Thus, it is often the case that raw data, or even downstream processed data is not in a form amenable to machine learning. We explore the construction of machine learning datasets and we ask: what elements define effective machine learning datasets? We define effective machine learning datasets in astronomy to be formed with well-defined data points, structure, and metadata. We discuss why these elements are important for astronomical applications and ways to put them in practice. We posit that these qualities not only make the data suitable for machine learning, they also help to foster usable, reusable, and replicable science practices.
Multimodal Interactive Learning of Primitive Actions
Oct 01, 2018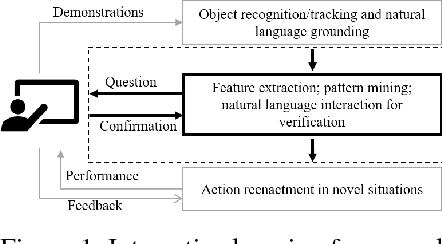

We describe an ongoing project in learning to perform primitive actions from demonstrations using an interactive interface. In our previous work, we have used demonstrations captured from humans performing actions as training samples for a neural network-based trajectory model of actions to be performed by a computational agent in novel setups. We found that our original framework had some limitations that we hope to overcome by incorporating communication between the human and the computational agent, using the interaction between them to fine-tune the model learned by the machine. We propose a framework that uses multimodal human-computer interaction to teach action concepts to machines, making use of both live demonstration and communication through natural language, as two distinct teaching modalities, while requiring few training samples.