 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchy-Guided Multimodal Representation Learning for Taxonomic Inference
Mar 26, 2026Accurate biodiversity identification from large-scale field data is a foundational problem with direct impact on ecology, conservation, and environmental monitoring. In practice, the core task is taxonomic prediction - inferring order, family, genus, or species from imperfect inputs such as specimen images, DNA barcodes, or both. Existing multimodal methods often treat taxonomy as a flat label space and therefore fail to encode the hierarchical structure of biological classification, which is critical for robustness under noise and missing modalities. We present two end-to-end variants for hierarchy-aware multimodal learning: CLiBD-HiR, which introduces Hierarchical Information Regularization (HiR) to shape embedding geometry across taxonomic levels, yielding structured and noise-robust representations; and CLiBD-HiR-Fuse, which additionally trains a lightweight fusion predictor that supports image-only, DNA-only, or joint inference and is resilient to modality corruption. Across large-scale biodiversity benchmarks, our approach improves taxonomic classification accuracy by over 14 percent compared to strong multimodal baselines, with particularly large gains under partial and corrupted DNA conditions. These results highlight that explicitly encoding biological hierarchy, together with flexible fusion, is key for practical biodiversity foundation models.
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL
May 30, 2025Although chain-of-thought reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based "thinking" skills via supervised fine-tuning on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization. To enable the model to reason through text before generating images, We automatically generate and release a corpus of model crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision language model to assess overall visual quality, optimizing the policy in each update. Evaluations on GenEval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. More: aka.ms/reasongen.
Will Large Language Models be a Panacea to Autonomous Driving?
Sep 24, 2024



Artificial intelligence (AI) plays a crucial role in autonomous driving (AD) research, propelling its development towards intelligence and efficiency. Currently, the development of AD technology follows two main technical paths: modularization and end-to-end. Modularization decompose the driving task into modules such as perception, prediction, planning, and control, and train them separately. Due to the inconsistency of training objectives between modules, the integrated effect suffers from bias. End-to-end attempts to address this issue by utilizing a single model that directly maps from sensor data to control signals. This path has limited learning capabilities in a comprehensive set of features and struggles to handle unpredictable long-tail events and complex urban traffic scenarios. In the face of challenges encountered in both paths, many researchers believe that large language models (LLMs) with powerful reasoning capabilities and extensive knowledge understanding may be the solution, expecting LLMs to provide AD systems with deeper levels of understanding and decision-making capabilities. In light of the challenges faced by both paths, many researchers believe that LLMs, with their powerful reasoning abilities and extensive knowledge, could offer a solution. To understand if LLMs could enhance AD, this paper conducts a thorough analysis of the potential applications of LLMs in AD systems, including exploring their optimization strategies in both modular and end-to-end approaches, with a particular focus on how LLMs can tackle the problems and challenges present in current solutions. Furthermore, we discuss an important question: Can LLM-based artificial general intelligence (AGI) be a key to achieve high-level AD? We further analyze the potential limitations and challenges that LLMs may encounter in promoting the development of AD technology.
Transferable Fairness for Cold-Start Recommendation
Jan 25, 2023



With the increasing use and impact of recommender systems in our daily lives, how to achieve fairness in recommendation has become an important problem. Previous works on fairness-aware recommendation mainly focus on a predefined set of (usually warm-start) users. However, recommender systems often face more challenging fairness issues for new users or cold-start users due to their insufficient amount of interactions. Therefore, it is essential to study whether the trained model still performs fairly for a new set of cold-start users. This paper considers the scenario where the recommender system meets new users who only have limited or even no interaction with the platform, and aims at providing high-quality and fair recommendations to such users effectively. The sufficient interaction data from warm users is treated as the source user domain, while the data from new users is treated as the target user domain, and we consider to transfer the counterfactual fairness from the source users to the target users. To this end, we introduce a framework to achieve transferable counterfactual fairness in recommendation. The proposed method is able to transfer the knowledge of a fair model learned from the source users to the target users with the hope of improving the recommendation performance and keeping the fairness property on the target users. Experiments on two real-world datasets with representative recommendation algorithms show that our method not only promotes fairness for the target users, but also outperforms comparative models in terms of recommendation performance.
Causal Inference for Recommendation: Foundations, Methods and Applications
Jan 08, 2023



Recommender systems are important and powerful tools for various personalized services. Traditionally, these systems use data mining and machine learning techniques to make recommendations based on correlations found in the data. However, relying solely on correlation without considering the underlying causal mechanism may lead to various practical issues such as fairness, explainability, robustness, bias, echo chamber and controllability problems. Therefore, researchers in related area have begun incorporating causality into recommendation systems to address these issues. In this survey, we review the existing literature on causal inference in recommender systems. We discuss the fundamental concepts of both recommender systems and causal inference as well as their relationship, and review the existing work on causal methods for different problems in recommender systems. Finally, we discuss open problems and future directions in the field of causal inference for recommendations.
Elements of effective machine learning datasets in astronomy
Nov 29, 2022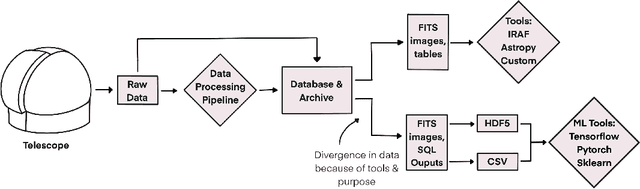
In this work, we identify elements of effective machine learning datasets in astronomy and present suggestions for their design and creation. Machine learning has become an increasingly important tool for analyzing and understanding the large-scale flood of data in astronomy. To take advantage of these tools, datasets are required for training and testing. However, building machine learning datasets for astronomy can be challenging. Astronomical data is collected from instruments built to explore science questions in a traditional fashion rather than to conduct machine learning. Thus, it is often the case that raw data, or even downstream processed data is not in a form amenable to machine learning. We explore the construction of machine learning datasets and we ask: what elements define effective machine learning datasets? We define effective machine learning datasets in astronomy to be formed with well-defined data points, structure, and metadata. We discuss why these elements are important for astronomical applications and ways to put them in practice. We posit that these qualities not only make the data suitable for machine learning, they also help to foster usable, reusable, and replicable science practices.
Learn Basic Skills and Reuse: Modularized Adaptive Neural Architecture Search (MANAS)
Aug 24, 2022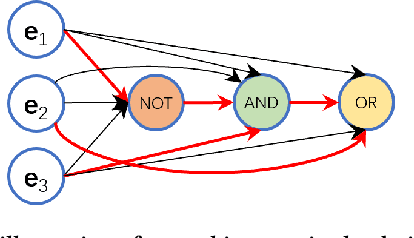


Human intelligence is able to first learn some basic skills for solving basic problems and then assemble such basic skills into complex skills for solving complex or new problems. For example, the basic skills "dig hole," "put tree," "backfill" and "watering" compose a complex skill "plant a tree". Besides, some basic skills can be reused for solving other problems. For example, the basic skill "dig hole" not only can be used for planting a tree, but also can be used for mining treasures, building a drain, or landfilling. The ability to learn basic skills and reuse them for various tasks is very important for humans because it helps to avoid learning too many skills for solving each individual task, and makes it possible to solve a compositional number of tasks by learning just a few number of basic skills, which saves a considerable amount of memory and computation in the human brain. We believe that machine intelligence should also capture the ability of learning basic skills and reusing them by composing into complex skills. In computer science language, each basic skill is a "module", which is a reusable network of a concrete meaning and performs a specific basic operation. The modules are assembled into a bigger "model" for doing a more complex task. The assembling procedure is adaptive to the input or task, i.e., for a given task, the modules should be assembled into the best model for solving the task. As a result, different inputs or tasks could have different assembled models, which enables Auto-Assembling AI (AAAI). In this work, we propose Modularized Adaptive Neural Architecture Search (MANAS) to demonstrate the above idea. Experiments on different datasets show that the adaptive architecture assembled by MANAS outperforms static global architectures. Further experiments and empirical analysis provide insights to the effectiveness of MANAS.
A Survey on Trustworthy Recommender Systems
Jul 25, 2022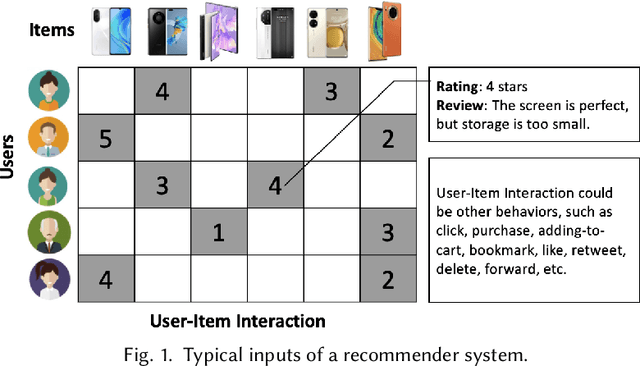

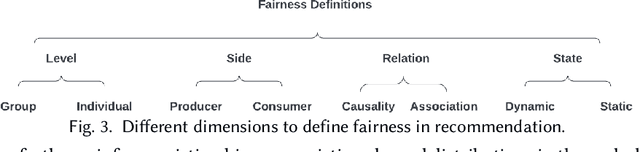

Recommender systems (RS), serving at the forefront of Human-centered AI, are widely deployed in almost every corner of the web and facilitate the human decision-making process. However, despite their enormous capabilities and potential, RS may also lead to undesired counter-effects on users, items, producers, platforms, or even the society at large, such as compromised user trust due to non-transparency, unfair treatment of different consumers, or producers, privacy concerns due to extensive use of user's private data for personalization, just to name a few. All of these create an urgent need for Trustworthy Recommender Systems (TRS) so as to mitigate or avoid such adverse impacts and risks. In this survey, we will introduce techniques related to trustworthy and responsible recommendation, including but not limited to explainable recommendation, fairness in recommendation, privacy-aware recommendation, robustness in recommendation, user controllable recommendation, as well as the relationship between these different perspectives in terms of trustworthy and responsible recommendation. Through this survey, we hope to deliver readers with a comprehensive view of the research area and raise attention to the community about the importance, existing research achievements, and future research directions on trustworthy recommendation.
Fairness in Recommendation: A Survey
Jun 01, 2022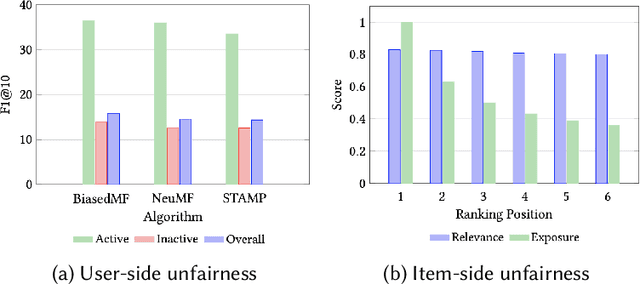
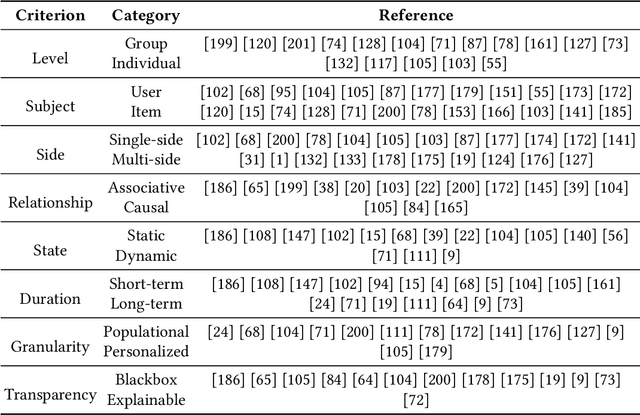
As one of the most pervasive applications of machine learning, recommender systems are playing an important role on assisting human decision making. The satisfaction of users and the interests of platforms are closely related to the quality of the generated recommendation results. However, as a highly data-driven system, recommender system could be affected by data or algorithmic bias and thus generate unfair results, which could weaken the reliance of the systems. As a result, it is crucial to address the potential unfairness problems in recommendation settings. Recently, there has been growing attention on fairness considerations in recommender systems with more and more literature on approaches to promote fairness in recommendation. However, the studies are rather fragmented and lack a systematic organization, thus making it difficult to penetrate for new researchers to the domain. This motivates us to provide a systematic survey of existing works on fairness in recommendation. This survey focuses on the foundations for fairness in recommendation literature. It first presents a brief introduction about fairness in basic machine learning tasks such as classification and ranking in order to provide a general overview of fairness research, as well as introduce the more complex situations and challenges that need to be considered when studying fairness in recommender systems. After that, the survey will introduce fairness in recommendation with a focus on the taxonomies of current fairness definitions, the typical techniques for improving fairness, as well as the datasets for fairness studies in recommendation. The survey also talks about the challenges and opportunities in fairness research with the hope of promoting the fair recommendation research area and beyond.
Learning and Evaluating Graph Neural Network Explanations based on Counterfactual and Factual Reasoning
Feb 17, 2022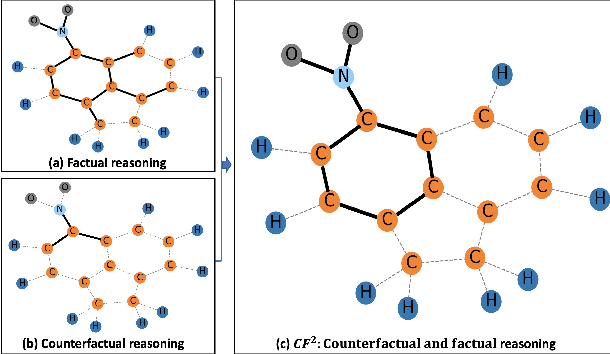
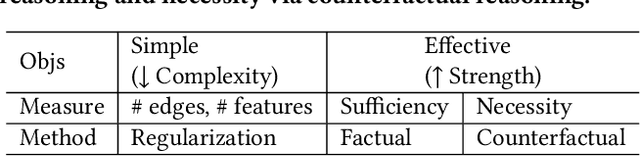

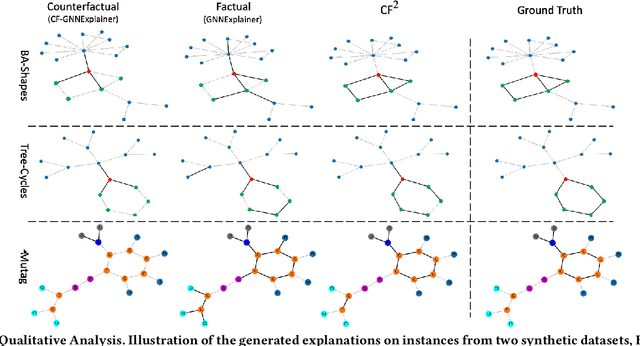
Structural data well exists in Web applications, such as social networks in social media, citation networks in academic websites, and threads data in online forums. Due to the complex topology, it is difficult to process and make use of the rich information within such data. Graph Neural Networks (GNNs) have shown great advantages on learning representations for structural data. However, the non-transparency of the deep learning models makes it non-trivial to explain and interpret the predictions made by GNNs. Meanwhile, it is also a big challenge to evaluate the GNN explanations, since in many cases, the ground-truth explanations are unavailable. In this paper, we take insights of Counterfactual and Factual (CF^2) reasoning from causal inference theory, to solve both the learning and evaluation problems in explainable GNNs. For generating explanations, we propose a model-agnostic framework by formulating an optimization problem based on both of the two casual perspectives. This distinguishes CF^2 from previous explainable GNNs that only consider one of them. Another contribution of the work is the evaluation of GNN explanations. For quantitatively evaluating the generated explanations without the requirement of ground-truth, we design metrics based on Counterfactual and Factual reasoning to evaluate the necessity and sufficiency of the explanations. Experiments show that no matter ground-truth explanations are available or not, CF^2 generates better explanations than previous state-of-the-art methods on real-world datasets. Moreover, the statistic analysis justifies the correlation between the performance on ground-truth evaluation and our proposed metrics.