 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization and Uncertainty Quantification of Photometric Redshift Models
Jan 23, 2026Accurate redshift estimates are a vital component in understanding galaxy evolution and precision cosmology. In this paper, we explore approaches to increase the applicability of machine learning models for photometric redshift estimation on a broader range of galaxy types. Typical models are trained with ground-truth redshifts from spectroscopy. We test the utility and effectiveness of two approaches for combining spectroscopic redshifts and redshifts derived from multiband ($\sim$35 filters) photometry, which sample different types of galaxies compared to spectroscopic surveys. The two approaches are (1) training on a composite dataset and (2) transfer learning from one dataset to another. We compile photometric redshifts from the COSMOS2020 catalog (TransferZ) to complement an established spectroscopic redshift dataset (GalaxiesML). We used two architectures, deterministic neural networks (NN) and Bayesian neural networks (BNN), to examine and evaluate their performance with respect to the Legacy Survey of Space and Time (LSST) photo-$z$ science requirements. We also use split conformal prediction for calibrating uncertainty estimates and producing prediction intervals for the BNN and NN, respectively. We find that a NN trained on a composite dataset predicts photo-$z$'s that are 4.5 times less biased within the redshift range $0.3<z<1.5$, 1.1 times less scattered, and has a 1.4 times lower outlier rate than a model trained on only spectroscopic ground truths. We also find that BNNs produce reliable uncertainty estimates, but are sensitive to the different ground truths. This investigation leverages different sources of ground truths to develop models that can accurately predict photo-$z$'s for a broader population of galaxies crucial for surveys such as Euclid and LSST.
Using Galaxy Evolution as Source of Physics-Based Ground Truth for Generative Models
Jul 09, 2024
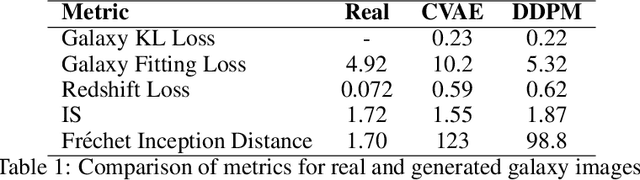


Generative models producing images have enormous potential to advance discoveries across scientific fields and require metrics capable of quantifying the high dimensional output. We propose that astrophysics data, such as galaxy images, can test generative models with additional physics-motivated ground truths in addition to human judgment. For example, galaxies in the Universe form and change over billions of years, following physical laws and relationships that are both easy to characterize and difficult to encode in generative models. We build a conditional denoising diffusion probabilistic model (DDPM) and a conditional variational autoencoder (CVAE) and test their ability to generate realistic galaxies conditioned on their redshifts (galaxy ages). This is one of the first studies to probe these generative models using physically motivated metrics. We find that both models produce comparable realistic galaxies based on human evaluation, but our physics-based metrics are better able to discern the strengths and weaknesses of the generative models. Overall, the DDPM model performs better than the CVAE on the majority of the physics-based metrics. Ultimately, if we can show that generative models can learn the physics of galaxy evolution, they have the potential to unlock new astrophysical discoveries.
Elements of effective machine learning datasets in astronomy
Nov 29, 2022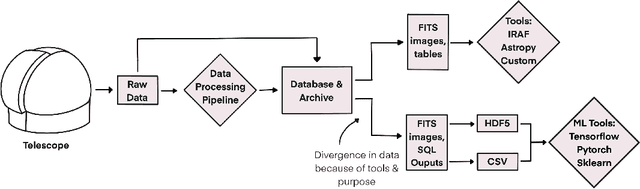
In this work, we identify elements of effective machine learning datasets in astronomy and present suggestions for their design and creation. Machine learning has become an increasingly important tool for analyzing and understanding the large-scale flood of data in astronomy. To take advantage of these tools, datasets are required for training and testing. However, building machine learning datasets for astronomy can be challenging. Astronomical data is collected from instruments built to explore science questions in a traditional fashion rather than to conduct machine learning. Thus, it is often the case that raw data, or even downstream processed data is not in a form amenable to machine learning. We explore the construction of machine learning datasets and we ask: what elements define effective machine learning datasets? We define effective machine learning datasets in astronomy to be formed with well-defined data points, structure, and metadata. We discuss why these elements are important for astronomical applications and ways to put them in practice. We posit that these qualities not only make the data suitable for machine learning, they also help to foster usable, reusable, and replicable science practices.