 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiKong: Curating, Training, and Evaluating A Semiconductor Industry-Specific Large Language Model
Nov 22, 2024



Large Language Models (LLMs) have demonstrated the potential to address some issues within the semiconductor industry. However, they are often general-purpose models that lack the specialized knowledge needed to tackle the unique challenges of this sector, such as the intricate physics and chemistry of semiconductor devices and processes. SemiKong, the first industry-specific LLM for the semiconductor domain, provides a foundation that can be used to develop tailored proprietary models. With SemiKong 1.0, we aim to develop a foundational model capable of understanding etching problems at an expert level. Our key contributions include (a) curating a comprehensive corpus of semiconductor-related texts, (b) creating a foundational model with in-depth semiconductor knowledge, and (c) introducing a framework for integrating expert knowledge, thereby advancing the evaluation process of domain-specific AI models. Through fine-tuning a pre-trained LLM using our curated dataset, we have shown that SemiKong outperforms larger, general-purpose LLMs in various semiconductor manufacturing and design tasks. Our extensive experiments underscore the importance of developing domain-specific LLMs as a foundation for company- or tool-specific proprietary models, paving the way for further research and applications in the semiconductor domain. Code and dataset will be available at https://github.com/aitomatic/semikong
Using Galaxy Evolution as Source of Physics-Based Ground Truth for Generative Models
Jul 09, 2024
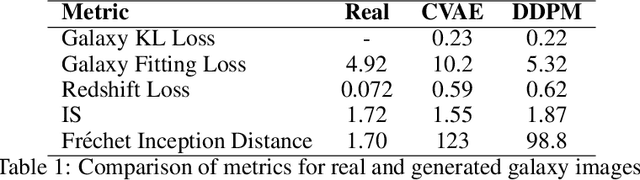


Generative models producing images have enormous potential to advance discoveries across scientific fields and require metrics capable of quantifying the high dimensional output. We propose that astrophysics data, such as galaxy images, can test generative models with additional physics-motivated ground truths in addition to human judgment. For example, galaxies in the Universe form and change over billions of years, following physical laws and relationships that are both easy to characterize and difficult to encode in generative models. We build a conditional denoising diffusion probabilistic model (DDPM) and a conditional variational autoencoder (CVAE) and test their ability to generate realistic galaxies conditioned on their redshifts (galaxy ages). This is one of the first studies to probe these generative models using physically motivated metrics. We find that both models produce comparable realistic galaxies based on human evaluation, but our physics-based metrics are better able to discern the strengths and weaknesses of the generative models. Overall, the DDPM model performs better than the CVAE on the majority of the physics-based metrics. Ultimately, if we can show that generative models can learn the physics of galaxy evolution, they have the potential to unlock new astrophysical discoveries.
Enhancing Q&A with Domain-Specific Fine-Tuning and Iterative Reasoning: A Comparative Study
Apr 17, 2024



This paper investigates the impact of domain-specific model fine-tuning and of reasoning mechanisms on the performance of question-answering (Q&A) systems powered by large language models (LLMs) and Retrieval-Augmented Generation (RAG). Using the FinanceBench SEC financial filings dataset, we observe that, for RAG, combining a fine-tuned embedding model with a fine-tuned LLM achieves better accuracy than generic models, with relatively greater gains attributable to fine-tuned embedding models. Additionally, employing reasoning iterations on top of RAG delivers an even bigger jump in performance, enabling the Q&A systems to get closer to human-expert quality. We discuss the implications of such findings, propose a structured technical design space capturing major technical components of Q&A AI, and provide recommendations for making high-impact technical choices for such components. We plan to follow up on this work with actionable guides for AI teams and further investigations into the impact of domain-specific augmentation in RAG and into agentic AI capabilities such as advanced planning and reasoning.