 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWA-KD: Dual-Space Weighting and Time-Warped Alignment for Cross-Tokenizer Knowledge Distillation
Feb 25, 2026Knowledge Distillation (KD) has emerged as a crucial technique for compressing Large Language Models (LLMs). Although existing cross-tokenizer KD methods have made notable progress, their effectiveness remains constrained by suboptimal alignment across sequence and vocabulary levels. To address these limitations, we introduce Dual-Space Weighting and Time-Warped Alignment (DWA-KD), a novel cross-tokenizer distillation framework that enhances token-wise distillation through dual-space entropy-based weighting and achieves precise sequence-level alignment by leveraging both lexical and semantic information. At the token level, DWA-KD maps teacher representations into the student space and vice versa, performing dual-space KD via Kullback-Leibler divergence (KL). The process is modulated by dual-space weights that up-weight tokens where the student is uncertain and the teacher is confident, thereby focusing learning on informative tokens rather than treating all positions equally. At the sequence level, DWA-KD applies Soft Dynamic Time Warping (Soft-DTW) to both the embedding and final hidden-state layers, enabling robust alignment of lexical and contextual semantics between teacher and student sequences. Extensive experiments across diverse NLP benchmarks demonstrate that DWA-KD outperforms state-of-the-art KD baselines, while ablation studies confirm the complementary contributions of entropy-based token weighting and embedding and final hidden state layer Soft-DTW alignment.
FAID: Fine-grained AI-generated Text Detection using Multi-task Auxiliary and Multi-level Contrastive Learning
May 20, 2025



The growing collaboration between humans and AI models in generative tasks has introduced new challenges in distinguishing between human-written, AI-generated, and human-AI collaborative texts. In this work, we collect a multilingual, multi-domain, multi-generator dataset FAIDSet. We further introduce a fine-grained detection framework FAID to classify text into these three categories, meanwhile identifying the underlying AI model family. Unlike existing binary classifiers, FAID is built to capture both authorship and model-specific characteristics. Our method combines multi-level contrastive learning with multi-task auxiliary classification to learn subtle stylistic cues. By modeling AI families as distinct stylistic entities, FAID offers improved interpretability. We incorporate an adaptation to address distributional shifts without retraining for unseen data. Experimental results demonstrate that FAID outperforms several baseline approaches, particularly enhancing the generalization accuracy on unseen domains and new AI models. It provide a potential solution for improving transparency and accountability in AI-assisted writing.
GloCOM: A Short Text Neural Topic Model via Global Clustering Context
Nov 30, 2024
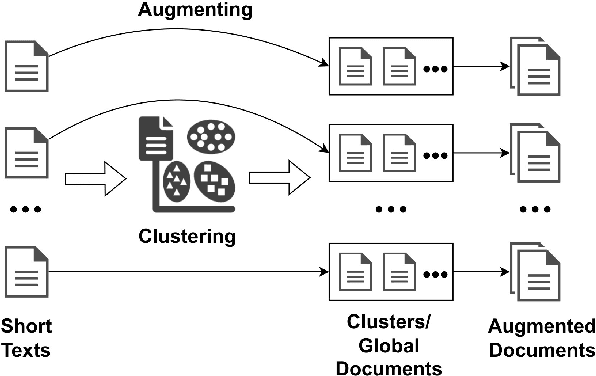
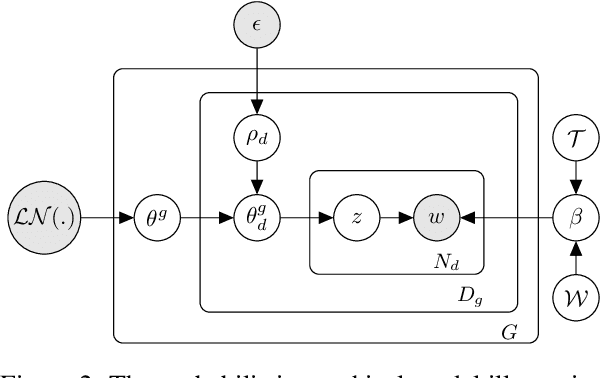
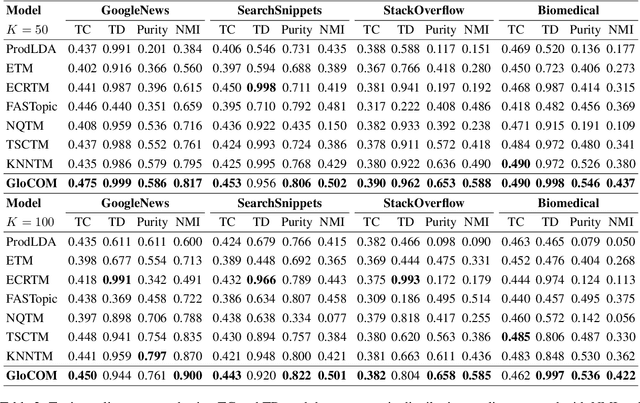
Uncovering hidden topics from short texts is challenging for traditional and neural models due to data sparsity, which limits word co-occurrence patterns, and label sparsity, stemming from incomplete reconstruction targets. Although data aggregation offers a potential solution, existing neural topic models often overlook it due to time complexity, poor aggregation quality, and difficulty in inferring topic proportions for individual documents. In this paper, we propose a novel model, GloCOM (Global Clustering COntexts for Topic Models), which addresses these challenges by constructing aggregated global clustering contexts for short documents, leveraging text embeddings from pre-trained language models. GloCOM can infer both global topic distributions for clustering contexts and local distributions for individual short texts. Additionally, the model incorporates these global contexts to augment the reconstruction loss, effectively handling the label sparsity issue. Extensive experiments on short text datasets show that our approach outperforms other state-of-the-art models in both topic quality and document representations.
SemiKong: Curating, Training, and Evaluating A Semiconductor Industry-Specific Large Language Model
Nov 22, 2024



Large Language Models (LLMs) have demonstrated the potential to address some issues within the semiconductor industry. However, they are often general-purpose models that lack the specialized knowledge needed to tackle the unique challenges of this sector, such as the intricate physics and chemistry of semiconductor devices and processes. SemiKong, the first industry-specific LLM for the semiconductor domain, provides a foundation that can be used to develop tailored proprietary models. With SemiKong 1.0, we aim to develop a foundational model capable of understanding etching problems at an expert level. Our key contributions include (a) curating a comprehensive corpus of semiconductor-related texts, (b) creating a foundational model with in-depth semiconductor knowledge, and (c) introducing a framework for integrating expert knowledge, thereby advancing the evaluation process of domain-specific AI models. Through fine-tuning a pre-trained LLM using our curated dataset, we have shown that SemiKong outperforms larger, general-purpose LLMs in various semiconductor manufacturing and design tasks. Our extensive experiments underscore the importance of developing domain-specific LLMs as a foundation for company- or tool-specific proprietary models, paving the way for further research and applications in the semiconductor domain. Code and dataset will be available at https://github.com/aitomatic/semikong
Enhancing Q&A with Domain-Specific Fine-Tuning and Iterative Reasoning: A Comparative Study
Apr 17, 2024



This paper investigates the impact of domain-specific model fine-tuning and of reasoning mechanisms on the performance of question-answering (Q&A) systems powered by large language models (LLMs) and Retrieval-Augmented Generation (RAG). Using the FinanceBench SEC financial filings dataset, we observe that, for RAG, combining a fine-tuned embedding model with a fine-tuned LLM achieves better accuracy than generic models, with relatively greater gains attributable to fine-tuned embedding models. Additionally, employing reasoning iterations on top of RAG delivers an even bigger jump in performance, enabling the Q&A systems to get closer to human-expert quality. We discuss the implications of such findings, propose a structured technical design space capturing major technical components of Q&A AI, and provide recommendations for making high-impact technical choices for such components. We plan to follow up on this work with actionable guides for AI teams and further investigations into the impact of domain-specific augmentation in RAG and into agentic AI capabilities such as advanced planning and reasoning.
Facial UV Map Completion for Pose-invariant Face Recognition: A Novel Adversarial Approach based on Coupled Attention Residual UNets
Nov 02, 2020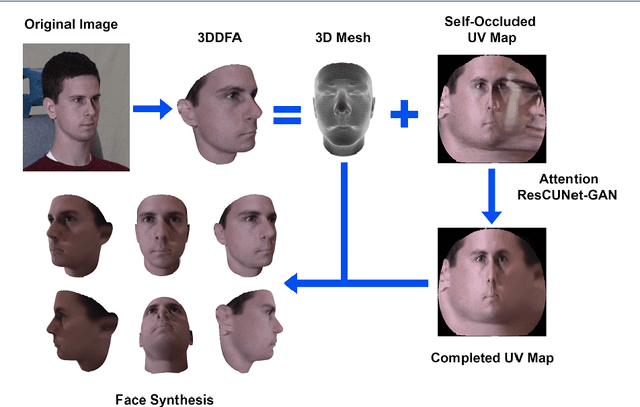

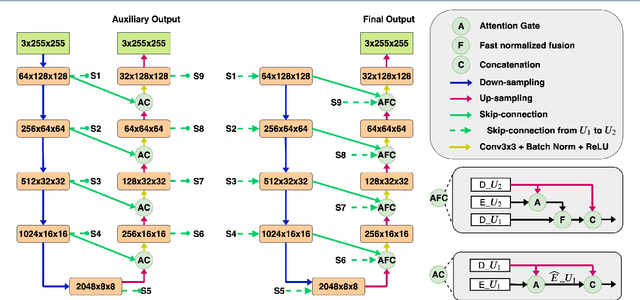
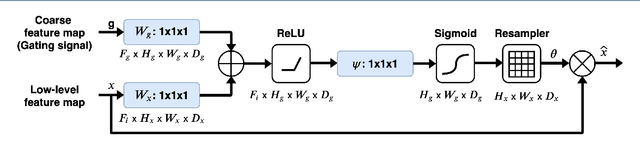
Pose-invariant face recognition refers to the problem of identifying or verifying a person by analyzing face images captured from different poses. This problem is challenging due to the large variation of pose, illumination and facial expression. A promising approach to deal with pose variation is to fulfill incomplete UV maps extracted from in-the-wild faces, then attach the completed UV map to a fitted 3D mesh and finally generate different 2D faces of arbitrary poses. The synthesized faces increase the pose variation for training deep face recognition models and reduce the pose discrepancy during the testing phase. In this paper, we propose a novel generative model called Attention ResCUNet-GAN to improve the UV map completion. We enhance the original UV-GAN by using a couple of U-Nets. Particularly, the skip connections within each U-Net are boosted by attention gates. Meanwhile, the features from two U-Nets are fused with trainable scalar weights. The experiments on the popular benchmarks, including Multi-PIE, LFW, CPLWF and CFP datasets, show that the proposed method yields superior performance compared to other existing methods.