 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial UV Map Completion for Pose-invariant Face Recognition: A Novel Adversarial Approach based on Coupled Attention Residual UNets
Nov 02, 2020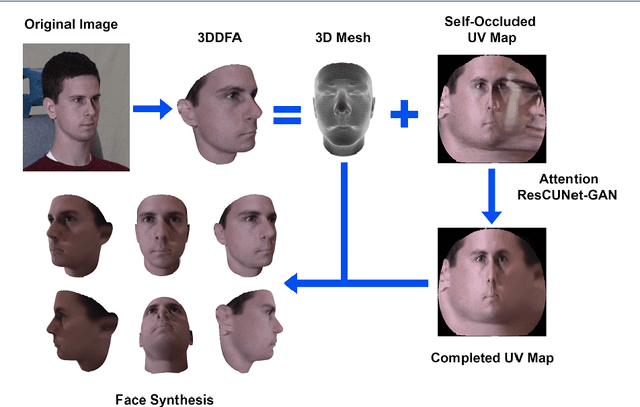

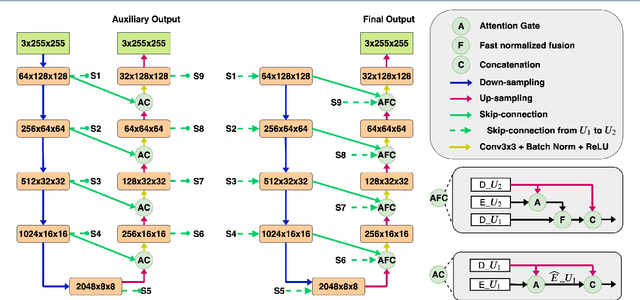
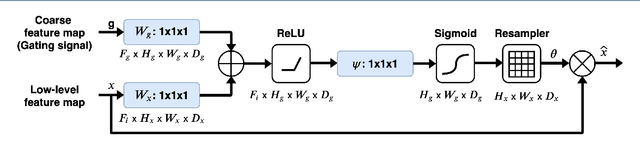
Pose-invariant face recognition refers to the problem of identifying or verifying a person by analyzing face images captured from different poses. This problem is challenging due to the large variation of pose, illumination and facial expression. A promising approach to deal with pose variation is to fulfill incomplete UV maps extracted from in-the-wild faces, then attach the completed UV map to a fitted 3D mesh and finally generate different 2D faces of arbitrary poses. The synthesized faces increase the pose variation for training deep face recognition models and reduce the pose discrepancy during the testing phase. In this paper, we propose a novel generative model called Attention ResCUNet-GAN to improve the UV map completion. We enhance the original UV-GAN by using a couple of U-Nets. Particularly, the skip connections within each U-Net are boosted by attention gates. Meanwhile, the features from two U-Nets are fused with trainable scalar weights. The experiments on the popular benchmarks, including Multi-PIE, LFW, CPLWF and CFP datasets, show that the proposed method yields superior performance compared to other existing methods.