 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
Apr 23, 2026Learning robust representations of authorial style is crucial for authorship attribution and AI-generated text detection. However, existing methods often struggle with content-style entanglement, where models learn spurious correlations between authors' writing styles and topics, leading to poor generalization across domains. To address this challenge, we propose Explainable Authorship Variational Autoencoder (EAVAE), a novel framework that explicitly disentangles style from content through architectural separation-by-design. EAVAE first pretrains style encoders using supervised contrastive learning on diverse authorship data, then finetunes with a Variational Autoencoder (VEA) architecture using separate encoders for style and content representations. Disentanglement is enforced through a novel discriminator that not only distinguishes whether pairs of style/content representations belong to the same or different authors/content sources, but also generates natural language explanation for their decision, simultaneously mitigating confounding information and enhancing interpretability. Extensive experiments demonstrate the effectiveness of EAVAE. On authorship attribution, we achieve state-of-the-art performance on various datasets, including Amazon Reviews, PAN21, and HRS. For AI-generated text detection, EAVAE excels in few-shot learning over the M4 dataset. Code and data repositories are available online\footnote{https://github.com/hieum98/avae} \footnote{https://huggingface.co/collections/Hieuman/document-level-authorship-datasets}.
GloCTM: Cross-Lingual Topic Modeling via a Global Context Space
Jan 17, 2026Cross-lingual topic modeling seeks to uncover coherent and semantically aligned topics across languages - a task central to multilingual understanding. Yet most existing models learn topics in disjoint, language-specific spaces and rely on alignment mechanisms (e.g., bilingual dictionaries) that often fail to capture deep cross-lingual semantics, resulting in loosely connected topic spaces. Moreover, these approaches often overlook the rich semantic signals embedded in multilingual pretrained representations, further limiting their ability to capture fine-grained alignment. We introduce GloCTM (Global Context Space for Cross-Lingual Topic Model), a novel framework that enforces cross-lingual topic alignment through a unified semantic space spanning the entire model pipeline. GloCTM constructs enriched input representations by expanding bag-of-words with cross-lingual lexical neighborhoods, and infers topic proportions using both local and global encoders, with their latent representations aligned through internal regularization. At the output level, the global topic-word distribution, defined over the combined vocabulary, structurally synchronizes topic meanings across languages. To further ground topics in deep semantic space, GloCTM incorporates a Centered Kernel Alignment (CKA) loss that aligns the latent topic space with multilingual contextual embeddings. Experiments across multiple benchmarks demonstrate that GloCTM significantly improves topic coherence and cross-lingual alignment, outperforming strong baselines.
mSCoRe: a $M$ultilingual and Scalable Benchmark for $S$kill-based $Co$mmonsense $Re$asoning
Aug 13, 2025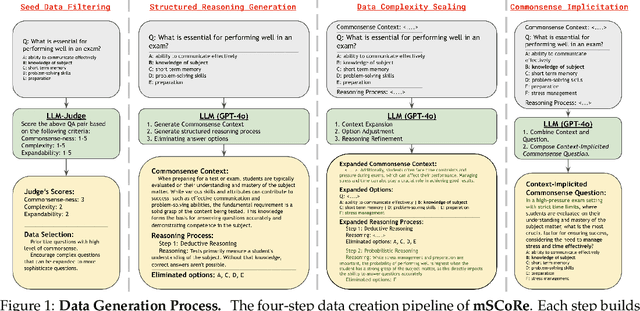
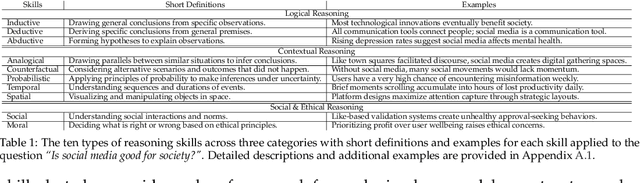
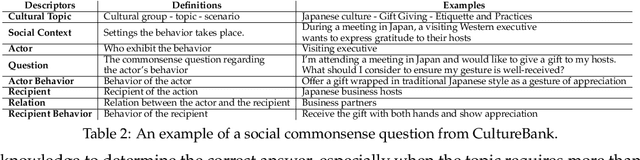

Recent advancements in reasoning-reinforced Large Language Models (LLMs) have shown remarkable capabilities in complex reasoning tasks. However, the mechanism underlying their utilization of different human reasoning skills remains poorly investigated, especially for multilingual commonsense reasoning that involves everyday knowledge across different languages and cultures. To address this gap, we propose a \textbf{M}ultilingual and Scalable Benchmark for \textbf{S}kill-based \textbf{Co}mmonsense \textbf{Re}asoning (\textbf{mSCoRe}). Our benchmark incorporates three key components that are designed to systematically evaluate LLM's reasoning capabilities, including: (1) a novel taxonomy of reasoning skills that enables fine-grained analysis of models' reasoning processes, (2) a robust data synthesis pipeline tailored specifically for commonsense reasoning evaluation, and (3) a complexity scaling framework allowing task difficulty to scale dynamically alongside future improvements in LLM abilities. Extensive experiments on eights state-of-the-art LLMs of varying sizes and training approaches demonstrate that \textbf{mSCoRe} remains significantly challenging for current models, particularly at higher complexity levels. Our results reveal the limitations of such reasoning-reinforced models when confronted with nuanced multilingual general and cultural commonsense. We further provide detailed analysis on the models' reasoning processes, suggesting future directions for improving multilingual commonsense reasoning capabilities.
Few-Shot, No Problem: Descriptive Continual Relation Extraction
Feb 27, 2025Few-shot Continual Relation Extraction is a crucial challenge for enabling AI systems to identify and adapt to evolving relationships in dynamic real-world domains. Traditional memory-based approaches often overfit to limited samples, failing to reinforce old knowledge, with the scarcity of data in few-shot scenarios further exacerbating these issues by hindering effective data augmentation in the latent space. In this paper, we propose a novel retrieval-based solution, starting with a large language model to generate descriptions for each relation. From these descriptions, we introduce a bi-encoder retrieval training paradigm to enrich both sample and class representation learning. Leveraging these enhanced representations, we design a retrieval-based prediction method where each sample "retrieves" the best fitting relation via a reciprocal rank fusion score that integrates both relation description vectors and class prototypes. Extensive experiments on multiple datasets demonstrate that our method significantly advances the state-of-the-art by maintaining robust performance across sequential tasks, effectively addressing catastrophic forgetting.
CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers
Feb 25, 2025



Large Language Models (LLMs) achieve state-of-the-art performance across various NLP tasks but face deployment challenges due to high computational costs and memory constraints. Knowledge distillation (KD) is a promising solution, transferring knowledge from large teacher models to smaller student models. However, existing KD methods often assume shared vocabularies and tokenizers, limiting their flexibility. While approaches like Universal Logit Distillation (ULD) and Dual-Space Knowledge Distillation (DSKD) address vocabulary mismatches, they overlook the critical \textbf{reasoning-aware distillation} aspect. To bridge this gap, we propose CoT2Align a universal KD framework that integrates Chain-of-Thought (CoT) augmentation and introduces Cross-CoT Alignment to enhance reasoning transfer. Additionally, we extend Optimal Transport beyond token-wise alignment to a sequence-level and layer-wise alignment approach that adapts to varying sequence lengths while preserving contextual integrity. Comprehensive experiments demonstrate that CoT2Align outperforms existing KD methods across different vocabulary settings, improving reasoning capabilities and robustness in domain-specific tasks.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
Jan 01, 2025



Recent advancements in large language models (LLMs) based embedding models have established new state-of-the-art benchmarks for text embedding tasks, particularly in dense vector-based retrieval. However, these models predominantly focus on English, leaving multilingual embedding capabilities largely unexplored. To address this limitation, we present LUSIFER, a novel zero-shot approach that adapts LLM-based embedding models for multilingual tasks without requiring multilingual supervision. LUSIFER's architecture combines a multilingual encoder, serving as a language-universal learner, with an LLM-based embedding model optimized for embedding-specific tasks. These components are seamlessly integrated through a minimal set of trainable parameters that act as a connector, effectively transferring the multilingual encoder's language understanding capabilities to the specialized embedding model. Additionally, to comprehensively evaluate multilingual embedding performance, we introduce a new benchmark encompassing 5 primary embedding tasks, 123 diverse datasets, and coverage across 14 languages. Extensive experimental results demonstrate that LUSIFER significantly enhances the multilingual performance across various embedding tasks, particularly for medium and low-resource languages, without requiring explicit multilingual training data.
GUI Agents: A Survey
Dec 18, 2024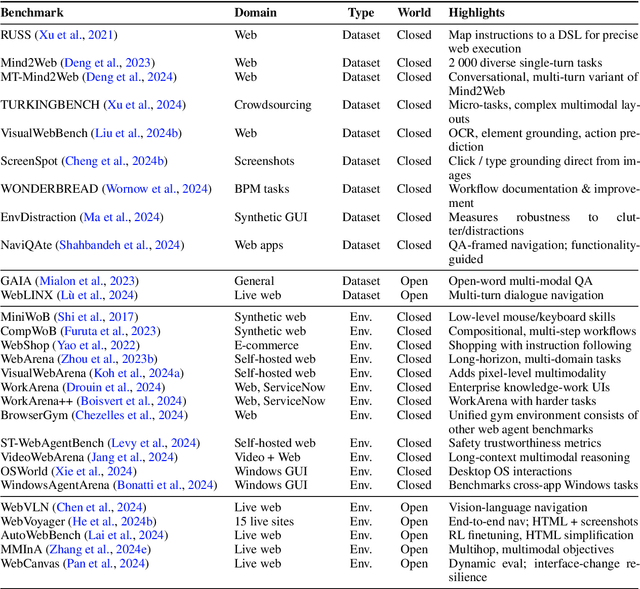
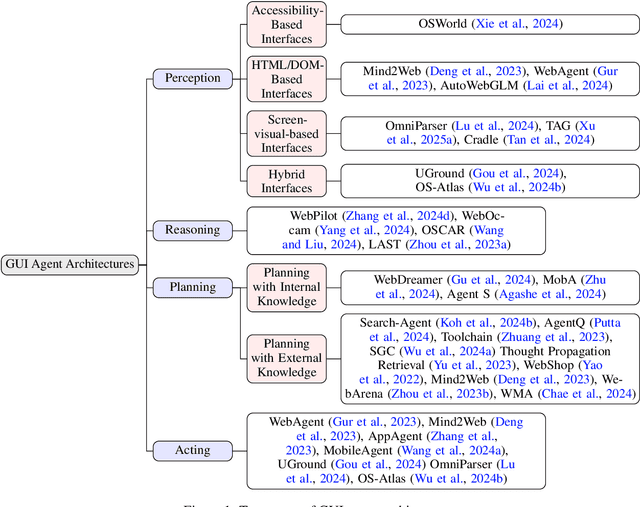

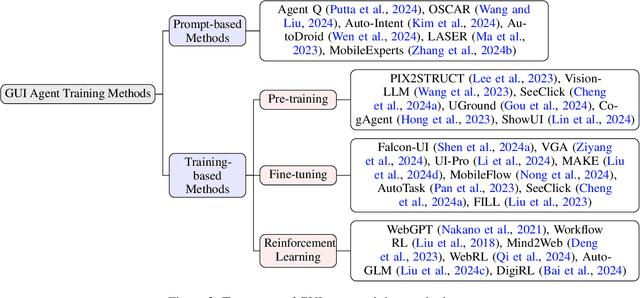
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Adaptive Prompting for Continual Relation Extraction: A Within-Task Variance Perspective
Dec 12, 2024



To address catastrophic forgetting in Continual Relation Extraction (CRE), many current approaches rely on memory buffers to rehearse previously learned knowledge while acquiring new tasks. Recently, prompt-based methods have emerged as potent alternatives to rehearsal-based strategies, demonstrating strong empirical performance. However, upon analyzing existing prompt-based approaches for CRE, we identified several critical limitations, such as inaccurate prompt selection, inadequate mechanisms for mitigating forgetting in shared parameters, and suboptimal handling of cross-task and within-task variances. To overcome these challenges, we draw inspiration from the relationship between prefix-tuning and mixture of experts, proposing a novel approach that employs a prompt pool for each task, capturing variations within each task while enhancing cross-task variances. Furthermore, we incorporate a generative model to consolidate prior knowledge within shared parameters, eliminating the need for explicit data storage. Extensive experiments validate the efficacy of our approach, demonstrating superior performance over state-of-the-art prompt-based and rehearsal-free methods in continual relation extraction.
GloCOM: A Short Text Neural Topic Model via Global Clustering Context
Nov 30, 2024
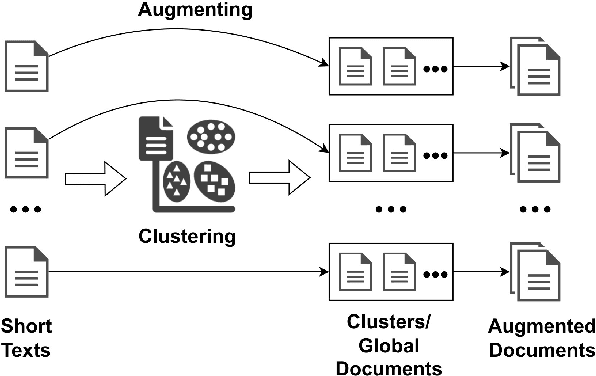
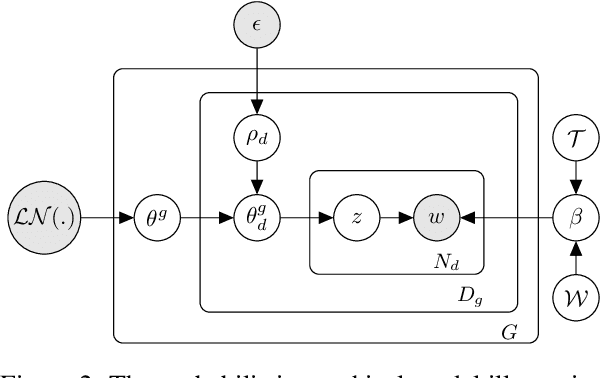
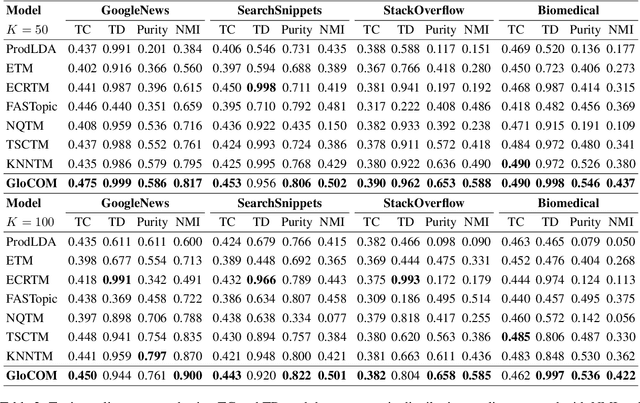
Uncovering hidden topics from short texts is challenging for traditional and neural models due to data sparsity, which limits word co-occurrence patterns, and label sparsity, stemming from incomplete reconstruction targets. Although data aggregation offers a potential solution, existing neural topic models often overlook it due to time complexity, poor aggregation quality, and difficulty in inferring topic proportions for individual documents. In this paper, we propose a novel model, GloCOM (Global Clustering COntexts for Topic Models), which addresses these challenges by constructing aggregated global clustering contexts for short documents, leveraging text embeddings from pre-trained language models. GloCOM can infer both global topic distributions for clustering contexts and local distributions for individual short texts. Additionally, the model incorporates these global contexts to augment the reconstruction loss, effectively handling the label sparsity issue. Extensive experiments on short text datasets show that our approach outperforms other state-of-the-art models in both topic quality and document representations.