 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWS-GRPO: Weakly-Supervised Group-Relative Policy Optimization for Rollout-Efficient Reasoning
Feb 19, 2026Group Relative Policy Optimization (GRPO) is effective for training language models on complex reasoning. However, since the objective is defined relative to a group of sampled trajectories, extended deliberation can create more chances to realize relative gains, leading to inefficient reasoning and overthinking, and complicating the trade-off between correctness and rollout efficiency. Controlling this behavior is difficult in practice, considering (i) Length penalties are hard to calibrate because longer rollouts may reflect harder problems that require longer reasoning, penalizing tokens risks truncating useful reasoning along with redundant continuation; and (ii) supervision that directly indicates when to continue or stop is typically unavailable beyond final answer correctness. We propose Weakly Supervised GRPO (WS-GRPO), which improves rollout efficiency by converting terminal rewards into correctness-aware guidance over partial trajectories. Unlike global length penalties that are hard to calibrate, WS-GRPO trains a preference model from outcome-only correctness to produce prefix-level signals that indicate when additional continuation is beneficial. Thus, WS-GRPO supplies outcome-derived continue/stop guidance, reducing redundant deliberation while maintaining accuracy. We provide theoretical results and empirically show on reasoning benchmarks that WS-GRPO substantially reduces rollout length while remaining competitive with GRPO baselines.
AMPS: Adaptive Modality Preference Steering via Functional Entropy
Feb 13, 2026Multimodal Large Language Models (MLLMs) often exhibit significant modality preference, which is a tendency to favor one modality over another. Depending on the input, they may over-rely on linguistic priors relative to visual evidence, or conversely over-attend to visually salient but facts in textual contexts. Prior work has applied a uniform steering intensity to adjust the modality preference of MLLMs. However, strong steering can impair standard inference and increase error rates, whereas weak steering is often ineffective. In addition, because steering sensitivity varies substantially across multimodal instances, a single global strength is difficult to calibrate. To address this limitation with minimal disruption to inference, we introduce an instance-aware diagnostic metric that quantifies each modality's information contribution and reveals sample-specific susceptibility to steering. Building on these insights, we propose a scaling strategy that reduces steering for sensitive samples and a learnable module that infers scaling patterns, enabling instance-aware control of modality preference. Experimental results show that our instance-aware steering outperforms conventional steering in modulating modality preference, achieving effective adjustment while keeping generation error rates low.
Evaluation on Entity Matching in Recommender Systems
Jan 23, 2026Entity matching is a crucial component in various recommender systems, including conversational recommender systems (CRS) and knowledge-based recommender systems. However, the lack of rigorous evaluation frameworks for cross-dataset entity matching impedes progress in areas such as LLM-driven conversational recommendations and knowledge-grounded dataset construction. In this paper, we introduce Reddit-Amazon-EM, a novel dataset comprising naturally occurring items from Reddit and the Amazon '23 dataset. Through careful manual annotation, we identify corresponding movies across Reddit-Movies and Amazon'23, two existing recommender system datasets with inherently overlapping catalogs. Leveraging Reddit-Amazon-EM, we conduct a comprehensive evaluation of state-of-the-art entity matching methods, including rule-based, graph-based, lexical-based, embedding-based, and LLM-based approaches. For reproducible research, we release our manually annotated entity matching gold set and provide the mapping between the two datasets using the best-performing method from our experiments. This serves as a valuable resource for advancing future work on entity matching in recommender systems.
SceneAlign: Aligning Multimodal Reasoning to Scene Graphs in Complex Visual Scenes
Jan 09, 2026Multimodal large language models often struggle with faithful reasoning in complex visual scenes, where intricate entities and relations require precise visual grounding at each step. This reasoning unfaithfulness frequently manifests as hallucinated entities, mis-grounded relations, skipped steps, and over-specified reasoning. Existing preference-based approaches, typically relying on textual perturbations or answer-conditioned rationales, fail to address this challenge as they allow models to exploit language priors to bypass visual grounding. To address this, we propose SceneAlign, a framework that leverages scene graphs as structured visual information to perform controllable structural interventions. By identifying reasoning-critical nodes and perturbing them through four targeted strategies that mimic typical grounding failures, SceneAlign constructs hard negative rationales that remain linguistically plausible but are grounded in inaccurate visual facts. These contrastive pairs are used in Direct Preference Optimization to steer models toward fine-grained, structure-faithful reasoning. Across seven visual reasoning benchmarks, SceneAlign consistently improves answer accuracy and reasoning faithfulness, highlighting the effectiveness of grounding-aware alignment for multimodal reasoning.
MuseCPBench: an Empirical Study of Music Editing Methods through Music Context Preservation
Dec 16, 2025Music editing plays a vital role in modern music production, with applications in film, broadcasting, and game development. Recent advances in music generation models have enabled diverse editing tasks such as timbre transfer, instrument substitution, and genre transformation. However, many existing works overlook the evaluation of their ability to preserve musical facets that should remain unchanged during editing a property we define as Music Context Preservation (MCP). While some studies do consider MCP, they adopt inconsistent evaluation protocols and metrics, leading to unreliable and unfair comparisons. To address this gap, we introduce the first MCP evaluation benchmark, MuseCPBench, which covers four categories of musical facets and enables comprehensive comparisons across five representative music editing baselines. Through systematic analysis along musical facets, methods, and models, we identify consistent preservation gaps in current music editing methods and provide insightful explanations. We hope our findings offer practical guidance for developing more effective and reliable music editing strategies with strong MCP capability
WildScore: Benchmarking MLLMs in-the-Wild Symbolic Music Reasoning
Sep 05, 2025Recent advances in Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, their reasoning abilities in the multimodal symbolic music domain remain largely unexplored. We introduce WildScore, the first in-the-wild multimodal symbolic music reasoning and analysis benchmark, designed to evaluate MLLMs' capacity to interpret real-world music scores and answer complex musicological queries. Each instance in WildScore is sourced from genuine musical compositions and accompanied by authentic user-generated questions and discussions, capturing the intricacies of practical music analysis. To facilitate systematic evaluation, we propose a systematic taxonomy, comprising both high-level and fine-grained musicological ontologies. Furthermore, we frame complex music reasoning as multiple-choice question answering, enabling controlled and scalable assessment of MLLMs' symbolic music understanding. Empirical benchmarking of state-of-the-art MLLMs on WildScore reveals intriguing patterns in their visual-symbolic reasoning, uncovering both promising directions and persistent challenges for MLLMs in symbolic music reasoning and analysis. We release the dataset and code.
SAND: Boosting LLM Agents with Self-Taught Action Deliberation
Jul 10, 2025Large Language Model (LLM) agents are commonly tuned with supervised finetuning on ReAct-style expert trajectories or preference optimization over pairwise rollouts. Most of these methods focus on imitating specific expert behaviors or promoting chosen reasoning thoughts and actions over rejected ones. However, without reasoning and comparing over alternatives actions, LLM agents finetuned with these methods may over-commit towards seemingly plausible but suboptimal actions due to limited action space exploration. To address this, in this paper we propose Self-taught ActioN Deliberation (SAND) framework, enabling LLM agents to explicitly deliberate over candidate actions before committing to one. To tackle the challenges of when and what to deliberate given large action space and step-level action evaluation, we incorporate self-consistency action sampling and execution-guided action critique to help synthesize step-wise action deliberation thoughts using the base model of the LLM agent. In an iterative manner, the deliberation trajectories are then used to finetune the LLM agent itself. Evaluating on two representative interactive agent tasks, SAND achieves an average 20% improvement over initial supervised finetuning and also outperforms state-of-the-art agent tuning approaches.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025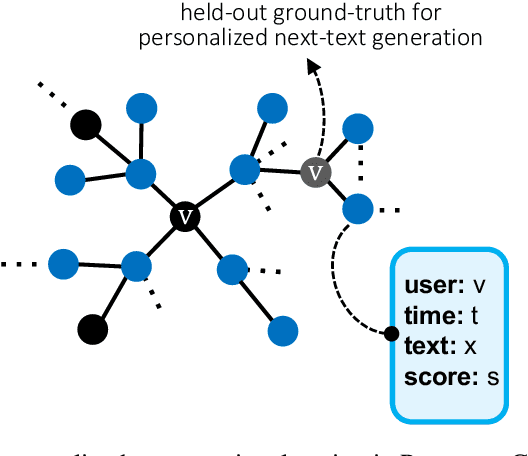
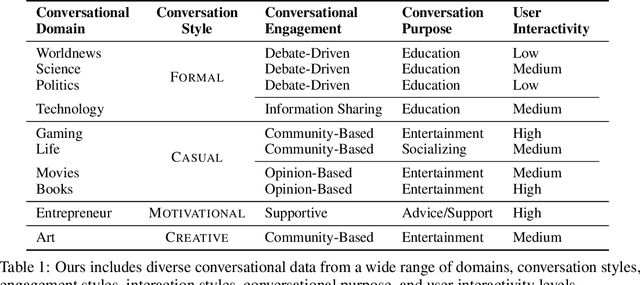
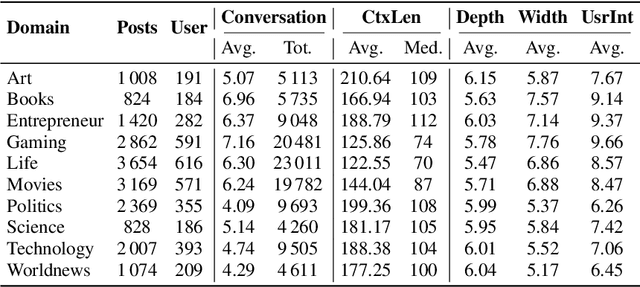
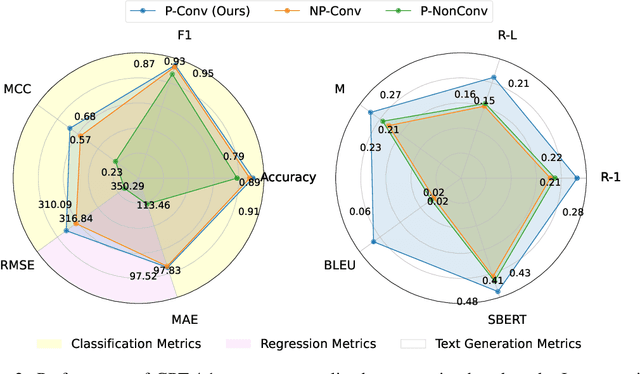
We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
CachePrune: Neural-Based Attribution Defense Against Indirect Prompt Injection Attacks
Apr 29, 2025Large Language Models (LLMs) are identified as being susceptible to indirect prompt injection attack, where the model undesirably deviates from user-provided instructions by executing tasks injected in the prompt context. This vulnerability stems from LLMs' inability to distinguish between data and instructions within a prompt. In this paper, we propose CachePrune that defends against this attack by identifying and pruning task-triggering neurons from the KV cache of the input prompt context. By pruning such neurons, we encourage the LLM to treat the text spans of input prompt context as only pure data, instead of any indicator of instruction following. These neurons are identified via feature attribution with a loss function induced from an upperbound of the Direct Preference Optimization (DPO) objective. We show that such a loss function enables effective feature attribution with only a few samples. We further improve on the quality of feature attribution, by exploiting an observed triggering effect in instruction following. Our approach does not impose any formatting on the original prompt or introduce extra test-time LLM calls. Experiments show that CachePrune significantly reduces attack success rates without compromising the response quality. Note: This paper aims to defend against indirect prompt injection attacks, with the goal of developing more secure and robust AI systems.
A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms
Apr 23, 2025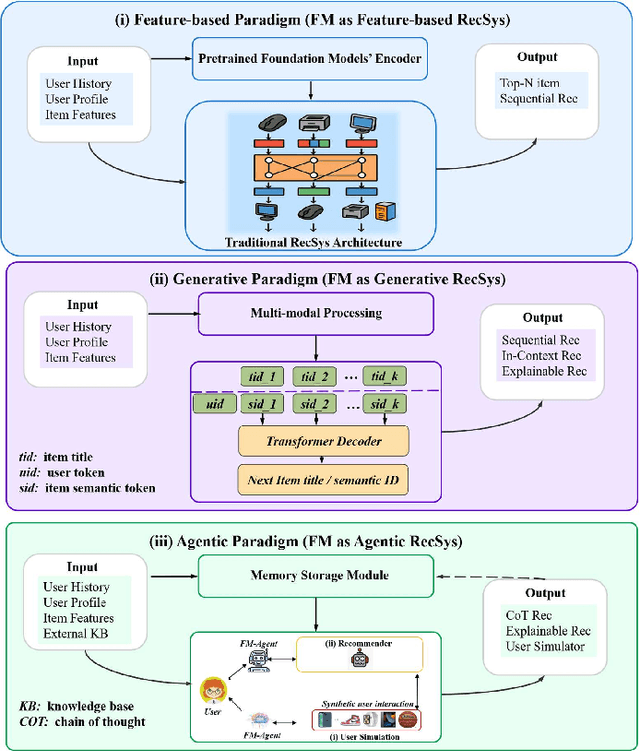
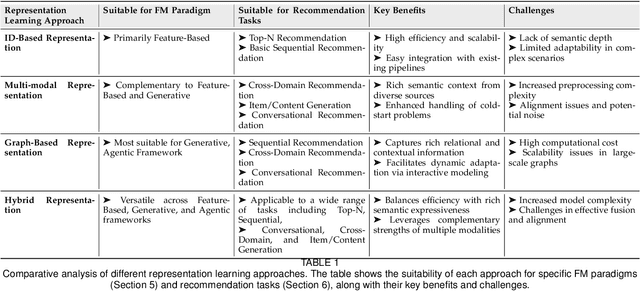
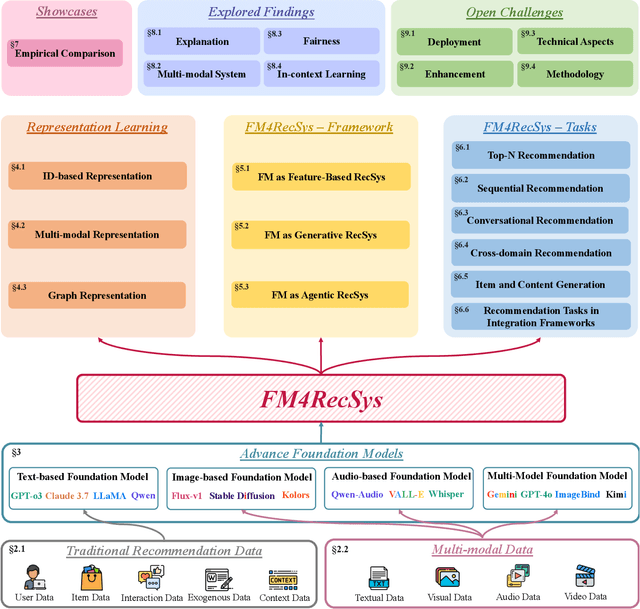
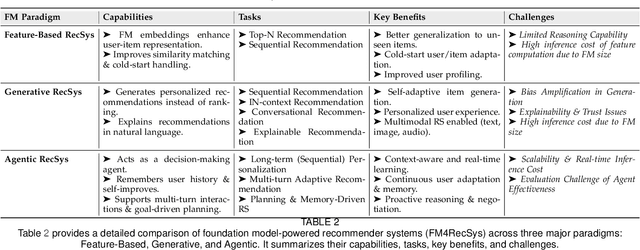
Recommender systems (RS) have become essential in filtering information and personalizing content for users. RS techniques have traditionally relied on modeling interactions between users and items as well as the features of content using models specific to each task. The emergence of foundation models (FMs), large scale models trained on vast amounts of data such as GPT, LLaMA and CLIP, is reshaping the recommendation paradigm. This survey provides a comprehensive overview of the Foundation Models for Recommender Systems (FM4RecSys), covering their integration in three paradigms: (1) Feature-Based augmentation of representations, (2) Generative recommendation approaches, and (3) Agentic interactive systems. We first review the data foundations of RS, from traditional explicit or implicit feedback to multimodal content sources. We then introduce FMs and their capabilities for representation learning, natural language understanding, and multi-modal reasoning in RS contexts. The core of the survey discusses how FMs enhance RS under different paradigms. Afterward, we examine FM applications in various recommendation tasks. Through an analysis of recent research, we highlight key opportunities that have been realized as well as challenges encountered. Finally, we outline open research directions and technical challenges for next-generation FM4RecSys. This survey not only reviews the state-of-the-art methods but also provides a critical analysis of the trade-offs among the feature-based, the generative, and the agentic paradigms, outlining key open issues and future research directions.