 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Composed Image Retrieval Benchmarks Require Multimodal Composition?
May 14, 2026Composed Image Retrieval (CIR) is a multimodal retrieval task where a query consists of a reference image and a textual modification, and the goal is to retrieve a target image satisfying both. In principle, strong performance on CIR benchmarks is assumed to require multimodal composition, i.e., combining complementary information from reference image and textual modification. In this work, we show that this assumption does not always hold. Across four widely used CIR benchmarks and eleven Generalist Multimodal Embedding models, a large fraction of queries can be solved using a single modality (from 32.2% to 83.6%), revealing pervasive unimodal shortcuts. Thus, high CIR performance can arise from unimodal signals rather than true multimodal composition. To better understand this issue, we perform a two-stage audit. First, we identify shortcut-solvable queries through cross-model analysis. Second, we conduct human validation on 4,741 shortcut-free queries, of which only 1,689 are well-formed, with common issues including ambiguous edits and mismatched targets. Re-evaluating models on this validated subset reveals qualitatively different behaviour: queries can no longer be solved with a single modality, and successful retrieval requires combining both inputs. While accuracy decreases, reliance on multimodal information increases. Overall, current CIR benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries, leading to an overestimation of model capability in multimodal composition.
Calibrated Recommendations: Survey and Future Directions
Jul 03, 2025The idea of calibrated recommendations is that the properties of the items that are suggested to users should match the distribution of their individual past preferences. Calibration techniques are therefore helpful to ensure that the recommendations provided to a user are not limited to a certain subset of the user's interests. Over the past few years, we have observed an increasing number of research works that use calibration for different purposes, including questions of diversity, biases, and fairness. In this work, we provide a survey on the recent developments in the area of calibrated recommendations. We both review existing technical approaches for calibration and provide an overview on empirical and analytical studies on the effectiveness of calibration for different use cases. Furthermore, we discuss limitations and common challenges when implementing calibration in practice.
Diffusion Recommender Models and the Illusion of Progress: A Concerning Study of Reproducibility and a Conceptual Mismatch
May 14, 2025Countless new machine learning models are published every year and are reported to significantly advance the state-of-the-art in \emph{top-n} recommendation. However, earlier reproducibility studies indicate that progress in this area may be quite limited. Specifically, various widespread methodological issues, e.g., comparisons with untuned baseline models, have led to an \emph{illusion of progress}. In this work, our goal is to examine whether these problems persist in today's research. To this end, we aim to reproduce the latest advancements reported from applying modern Denoising Diffusion Probabilistic Models to recommender systems, focusing on four models published at the top-ranked SIGIR conference in 2023 and 2024. Our findings are concerning, revealing persistent methodological problems. Alarmingly, through experiments, we find that the latest recommendation techniques based on diffusion models, despite their computational complexity and substantial carbon footprint, are consistently outperformed by simpler existing models. Furthermore, we identify key mismatches between the characteristics of diffusion models and those of the traditional \emph{top-n} recommendation task, raising doubts about their suitability for recommendation. We also note that, in the papers we analyze, the generative capabilities of these models are constrained to a minimum. Overall, our results and continued methodological issues call for greater scientific rigor and a disruptive change in the research and publication culture in this area.
A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms
Apr 23, 2025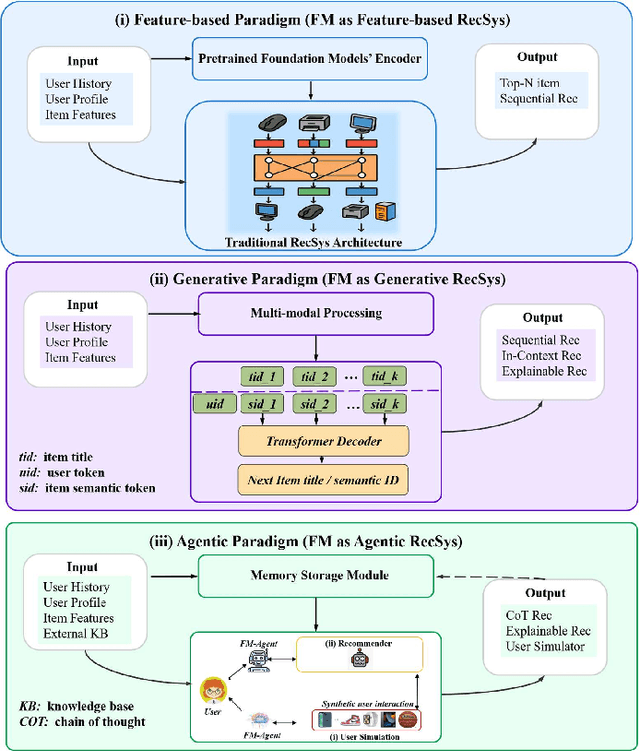
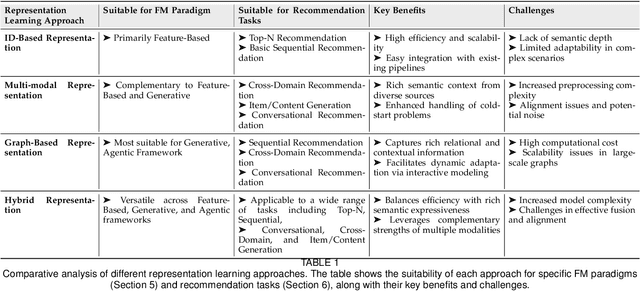
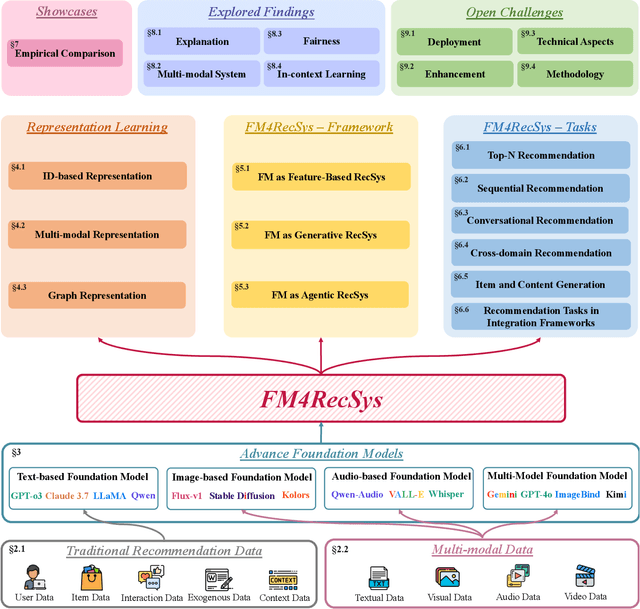
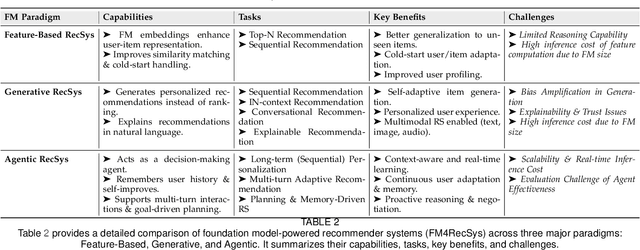
Recommender systems (RS) have become essential in filtering information and personalizing content for users. RS techniques have traditionally relied on modeling interactions between users and items as well as the features of content using models specific to each task. The emergence of foundation models (FMs), large scale models trained on vast amounts of data such as GPT, LLaMA and CLIP, is reshaping the recommendation paradigm. This survey provides a comprehensive overview of the Foundation Models for Recommender Systems (FM4RecSys), covering their integration in three paradigms: (1) Feature-Based augmentation of representations, (2) Generative recommendation approaches, and (3) Agentic interactive systems. We first review the data foundations of RS, from traditional explicit or implicit feedback to multimodal content sources. We then introduce FMs and their capabilities for representation learning, natural language understanding, and multi-modal reasoning in RS contexts. The core of the survey discusses how FMs enhance RS under different paradigms. Afterward, we examine FM applications in various recommendation tasks. Through an analysis of recent research, we highlight key opportunities that have been realized as well as challenges encountered. Finally, we outline open research directions and technical challenges for next-generation FM4RecSys. This survey not only reviews the state-of-the-art methods but also provides a critical analysis of the trade-offs among the feature-based, the generative, and the agentic paradigms, outlining key open issues and future research directions.
A Worrying Reproducibility Study of Intent-Aware Recommendation Models
Jan 17, 2025



Lately, we have observed a growing interest in intent-aware recommender systems (IARS). The promise of such systems is that they are capable of generating better recommendations by predicting and considering the underlying motivations and short-term goals of consumers. From a technical perspective, various sophisticated neural models were recently proposed in this emerging and promising area. In the broader context of complex neural recommendation models, a growing number of research works unfortunately indicates that (i) reproducing such works is often difficult and (ii) that the true benefits of such models may be limited in reality, e.g., because the reported improvements were obtained through comparisons with untuned or weak baselines. In this work, we investigate if recent research in IARS is similarly affected by such problems. Specifically, we tried to reproduce five contemporary IARS models that were published in top-level outlets, and we benchmarked them against a number of traditional non-neural recommendation models. In two of the cases, running the provided code with the optimal hyperparameters reported in the paper did not yield the results reported in the paper. Worryingly, we find that all examined IARS approaches are consistently outperformed by at least one traditional model. These findings point to sustained methodological issues and to a pressing need for more rigorous scholarly practices.
Recommender Systems for Good (RS4Good): Survey of Use Cases and a Call to Action for Research that Matters
Nov 25, 2024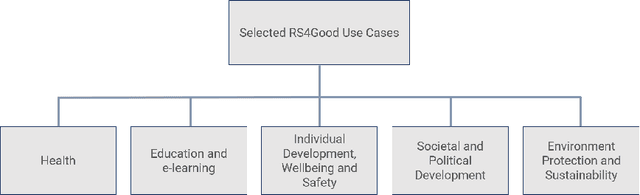

In the area of recommender systems, the vast majority of research efforts is spent on developing increasingly sophisticated recommendation models, also using increasingly more computational resources. Unfortunately, most of these research efforts target a very small set of application domains, mostly e-commerce and media recommendation. Furthermore, many of these models are never evaluated with users, let alone put into practice. The scientific, economic and societal value of much of these efforts by scholars therefore remains largely unclear. To achieve a stronger positive impact resulting from these efforts, we posit that we as a research community should more often address use cases where recommender systems contribute to societal good (RS4Good). In this opinion piece, we first discuss a number of examples where the use of recommender systems for problems of societal concern has been successfully explored in the literature. We then proceed by outlining a paradigmatic shift that is needed to conduct successful RS4Good research, where the key ingredients are interdisciplinary collaborations and longitudinal evaluation approaches with humans in the loop.
Fashion Image-to-Image Translation for Complementary Item Retrieval
Aug 19, 2024



The increasing demand for online fashion retail has boosted research in fashion compatibility modeling and item retrieval, focusing on matching user queries (textual descriptions or reference images) with compatible fashion items. A key challenge is top-bottom retrieval, where precise compatibility modeling is essential. Traditional methods, often based on Bayesian Personalized Ranking (BPR), have shown limited performance. Recent efforts have explored using generative models in compatibility modeling and item retrieval, where generated images serve as additional inputs. However, these approaches often overlook the quality of generated images, which could be crucial for model performance. Additionally, generative models typically require large datasets, posing challenges when such data is scarce. To address these issues, we introduce the Generative Compatibility Model (GeCo), a two-stage approach that improves fashion image retrieval through paired image-to-image translation. First, the Complementary Item Generation Model (CIGM), built on Conditional Generative Adversarial Networks (GANs), generates target item images (e.g., bottoms) from seed items (e.g., tops), offering conditioning signals for retrieval. These generated samples are then integrated into GeCo, enhancing compatibility modeling and retrieval accuracy. Evaluations on three datasets show that GeCo outperforms state-of-the-art baselines. Key contributions include: (i) the GeCo model utilizing paired image-to-image translation within the Composed Image Retrieval framework, (ii) comprehensive evaluations on benchmark datasets, and (iii) the release of a new Fashion Taobao dataset designed for top-bottom retrieval, promoting further research.
A Survey on Intent-aware Recommender Systems
Jun 24, 2024Many modern online services feature personalized recommendations. A central challenge when providing such recommendations is that the reason why an individual user accesses the service may change from visit to visit or even during an ongoing usage session. To be effective, a recommender system should therefore aim to take the users' probable intent of using the service at a certain point in time into account. In recent years, researchers have thus started to address this challenge by incorporating intent-awareness into recommender systems. Correspondingly, a number of technical approaches were put forward, including diversification techniques, intent prediction models or latent intent modeling approaches. In this paper, we survey and categorize existing approaches to building the next generation of Intent-Aware Recommender Systems (IARS). Based on an analysis of current evaluation practices, we outline open gaps and possible future directions in this area, which in particular include the consideration of additional interaction signals and contextual information to further improve the effectiveness of such systems.
Causal Learning for Trustworthy Recommender Systems: A Survey
Feb 13, 2024



Recommender Systems (RS) have significantly advanced online content discovery and personalized decision-making. However, emerging vulnerabilities in RS have catalyzed a paradigm shift towards Trustworthy RS (TRS). Despite numerous progress on TRS, most of them focus on data correlations while overlooking the fundamental causal nature in recommendation. This drawback hinders TRS from identifying the cause in addressing trustworthiness issues, leading to limited fairness, robustness, and explainability. To bridge this gap, causal learning emerges as a class of promising methods to augment TRS. These methods, grounded in reliable causality, excel in mitigating various biases and noises while offering insightful explanations for TRS. However, there lacks a timely survey in this vibrant area. This paper creates an overview of TRS from the perspective of causal learning. We begin by presenting the advantages and common procedures of Causality-oriented TRS (CTRS). Then, we identify potential trustworthiness challenges at each stage and link them to viable causal solutions, followed by a classification of CTRS methods. Finally, we discuss several future directions for advancing this field.
Investigating Reproducibility in Deep Learning-Based Software Fault Prediction
Feb 08, 2024Over the past few years, deep learning methods have been applied for a wide range of Software Engineering (SE) tasks, including in particular for the important task of automatically predicting and localizing faults in software. With the rapid adoption of increasingly complex machine learning models, it however becomes more and more difficult for scholars to reproduce the results that are reported in the literature. This is in particular the case when the applied deep learning models and the evaluation methodology are not properly documented and when code and data are not shared. Given some recent -- and very worrying -- findings regarding reproducibility and progress in other areas of applied machine learning, the goal of this work is to analyze to what extent the field of software engineering, in particular in the area of software fault prediction, is plagued by similar problems. We have therefore conducted a systematic review of the current literature and examined the level of reproducibility of 56 research articles that were published between 2019 and 2022 in top-tier software engineering conferences. Our analysis revealed that scholars are apparently largely aware of the reproducibility problem, and about two thirds of the papers provide code for their proposed deep learning models. However, it turned out that in the vast majority of cases, crucial elements for reproducibility are missing, such as the code of the compared baselines, code for data pre-processing or code for hyperparameter tuning. In these cases, it therefore remains challenging to exactly reproduce the results in the current research literature. Overall, our meta-analysis therefore calls for improved research practices to ensure the reproducibility of machine-learning based research.