 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sequential Recommendations with LLMs
Feb 02, 2024The sequential recommendation problem has attracted considerable research attention in the past few years, leading to the rise of numerous recommendation models. In this work, we explore how Large Language Models (LLMs), which are nowadays introducing disruptive effects in many AI-based applications, can be used to build or improve sequential recommendation approaches. Specifically, we design three orthogonal approaches and hybrids of those to leverage the power of LLMs in different ways. In addition, we investigate the potential of each approach by focusing on its comprising technical aspects and determining an array of alternative choices for each one. We conduct extensive experiments on three datasets and explore a large variety of configurations, including different language models and baseline recommendation models, to obtain a comprehensive picture of the performance of each approach. Among other observations, we highlight that initializing state-of-the-art sequential recommendation models such as BERT4Rec or SASRec with embeddings obtained from an LLM can lead to substantial performance gains in terms of accuracy. Furthermore, we find that fine-tuning an LLM for recommendation tasks enables it to learn not only the tasks, but also concepts of a domain to some extent. We also show that fine-tuning OpenAI GPT leads to considerably better performance than fine-tuning Google PaLM 2. Overall, our extensive experiments indicate a huge potential value of leveraging LLMs in future recommendation approaches. We publicly share the code and data of our experiments to ensure reproducibility.
Leveraging Large Language Models for Sequential Recommendation
Sep 17, 2023



Sequential recommendation problems have received increasing attention in research during the past few years, leading to the inception of a large variety of algorithmic approaches. In this work, we explore how large language models (LLMs), which are nowadays introducing disruptive effects in many AI-based applications, can be used to build or improve sequential recommendation approaches. Specifically, we devise and evaluate three approaches to leverage the power of LLMs in different ways. Our results from experiments on two datasets show that initializing the state-of-the-art sequential recommendation model BERT4Rec with embeddings obtained from an LLM improves NDCG by 15-20% compared to the vanilla BERT4Rec model. Furthermore, we find that a simple approach that leverages LLM embeddings for producing recommendations, can provide competitive performance by highlighting semantically related items. We publicly share the code and data of our experiments to ensure reproducibility.
A Greek Parliament Proceedings Dataset for Computational Linguistics and Political Analysis
Oct 23, 2022



Large, diachronic datasets of political discourse are hard to come across, especially for resource-lean languages such as Greek. In this paper, we introduce a curated dataset of the Greek Parliament Proceedings that extends chronologically from 1989 up to 2020. It consists of more than 1 million speeches with extensive metadata, extracted from 5,355 parliamentary record files. We explain how it was constructed and the challenges that we had to overcome. The dataset can be used for both computational linguistics and political analysis-ideally, combining the two. We present such an application, showing (i) how the dataset can be used to study the change of word usage through time, (ii) between significant historical events and political parties, (iii) by evaluating and employing algorithms for detecting semantic shifts.
Search Engine Similarity Analysis: A Combined Content and Rankings Approach
Nov 06, 2020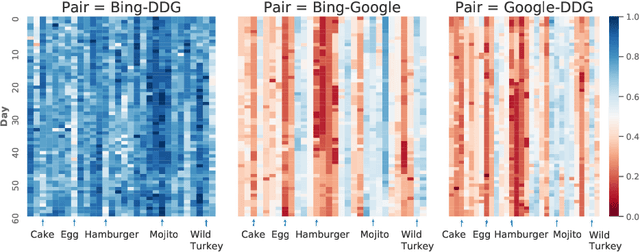
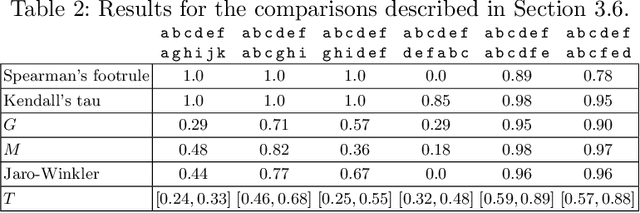
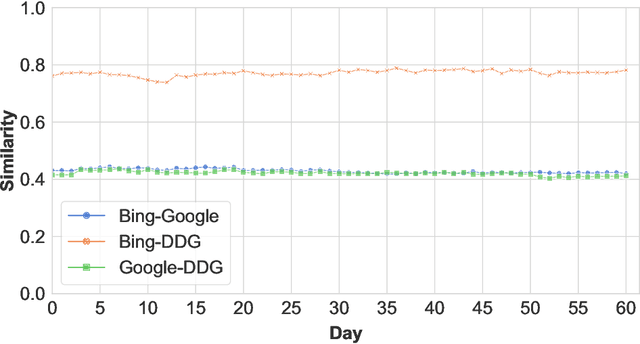
How different are search engines? The search engine wars are a favorite topic of on-line analysts, as two of the biggest companies in the world, Google and Microsoft, battle for prevalence of the web search space. Differences in search engine popularity can be explained by their effectiveness or other factors, such as familiarity with the most popular first engine, peer imitation, or force of habit. In this work we present a thorough analysis of the affinity of the two major search engines, Google and Bing, along with DuckDuckGo, which goes to great lengths to emphasize its privacy-friendly credentials. To do so, we collected search results using a comprehensive set of 300 unique queries for two time periods in 2016 and 2019, and developed a new similarity metric that leverages both the content and the ranking of search responses. We evaluated the characteristics of the metric against other metrics and approaches that have been proposed in the literature, and used it to (1) investigate the similarities of search engine results, (2) the evolution of their affinity over time, (3) what aspects of the results influence similarity, and (4) how the metric differs over different kinds of search services. We found that Google stands apart, but Bing and DuckDuckGo are largely indistinguishable from each other.