 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-PQA: LLM-enhanced Prediction Query Answering
Sep 02, 2024



The advent of Large Language Models (LLMs) provides an opportunity to change the way queries are processed, moving beyond the constraints of conventional SQL-based database systems. However, using an LLM to answer a prediction query is still challenging, since an external ML model has to be employed and inference has to be performed in order to provide an answer. This paper introduces LLM-PQA, a novel tool that addresses prediction queries formulated in natural language. LLM-PQA is the first to combine the capabilities of LLMs and retrieval-augmented mechanism for the needs of prediction queries by integrating data lakes and model zoos. This integration provides users with access to a vast spectrum of heterogeneous data and diverse ML models, facilitating dynamic prediction query answering. In addition, LLM-PQA can dynamically train models on demand, based on specific query requirements, ensuring reliable and relevant results even when no pre-trained model in a model zoo, available for the task.
FeatNavigator: Automatic Feature Augmentation on Tabular Data
Jun 13, 2024Data-centric AI focuses on understanding and utilizing high-quality, relevant data in training machine learning (ML) models, thereby increasing the likelihood of producing accurate and useful results. Automatic feature augmentation, aiming to augment the initial base table with useful features from other tables, is critical in data preparation as it improves model performance, robustness, and generalizability. While recent works have investigated automatic feature augmentation, most of them have limited capabilities in utilizing all useful features as many of them are in candidate tables not directly joinable with the base table. Worse yet, with numerous join paths leading to these distant features, existing solutions fail to fully exploit them within a reasonable compute budget. We present FeatNavigator, an effective and efficient framework that explores and integrates high-quality features in relational tables for ML models. FeatNavigator evaluates a feature from two aspects: (1) the intrinsic value of a feature towards an ML task (i.e., feature importance) and (2) the efficacy of a join path connecting the feature to the base table (i.e., integration quality). FeatNavigator strategically selects a small set of available features and their corresponding join paths to train a feature importance estimation model and an integration quality prediction model. Furthermore, FeatNavigator's search algorithm exploits both estimated feature importance and integration quality to identify the optimized feature augmentation plan. Our experimental results show that FeatNavigator outperforms state-of-the-art solutions on five public datasets by up to 40.1% in ML model performance.
Leveraging Large Language Models for Sequential Recommendation
Sep 17, 2023



Sequential recommendation problems have received increasing attention in research during the past few years, leading to the inception of a large variety of algorithmic approaches. In this work, we explore how large language models (LLMs), which are nowadays introducing disruptive effects in many AI-based applications, can be used to build or improve sequential recommendation approaches. Specifically, we devise and evaluate three approaches to leverage the power of LLMs in different ways. Our results from experiments on two datasets show that initializing the state-of-the-art sequential recommendation model BERT4Rec with embeddings obtained from an LLM improves NDCG by 15-20% compared to the vanilla BERT4Rec model. Furthermore, we find that a simple approach that leverages LLM embeddings for producing recommendations, can provide competitive performance by highlighting semantically related items. We publicly share the code and data of our experiments to ensure reproducibility.
Metadata Representations for Queryable ML Model Zoos
Jul 19, 2022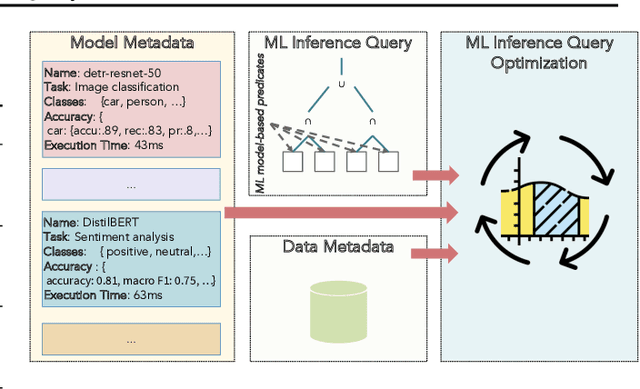
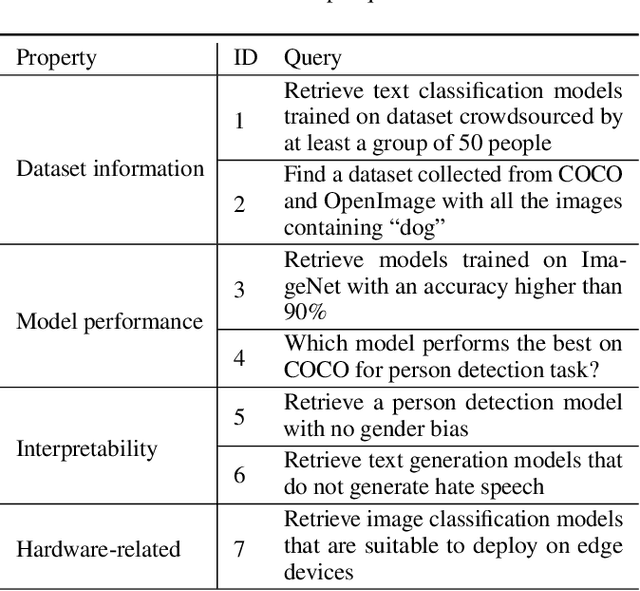
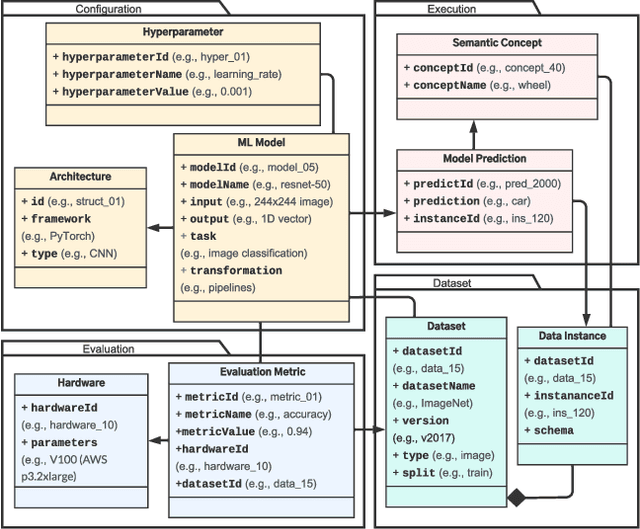
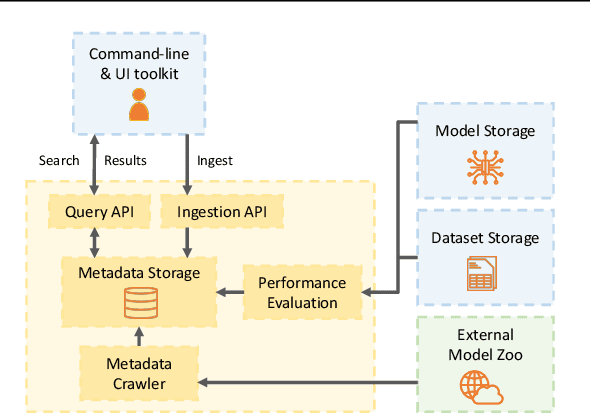
Machine learning (ML) practitioners and organizations are building model zoos of pre-trained models, containing metadata describing properties of the ML models and datasets that are useful for reporting, auditing, reproducibility, and interpretability purposes. The metatada is currently not standardised; its expressivity is limited; and there is no interoperable way to store and query it. Consequently, model search, reuse, comparison, and composition are hindered. In this paper, we advocate for standardized ML model meta-data representation and management, proposing a toolkit supported to help practitioners manage and query that metadata.
A Survey on the Evolution of Stream Processing Systems
Aug 03, 2020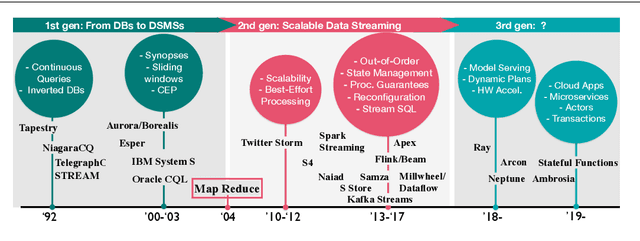
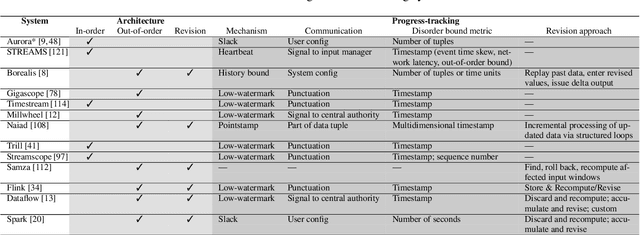
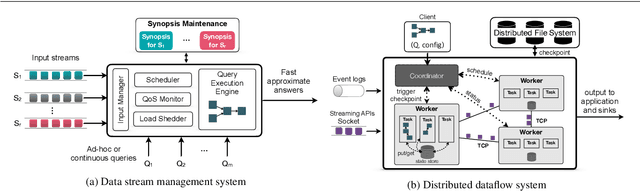
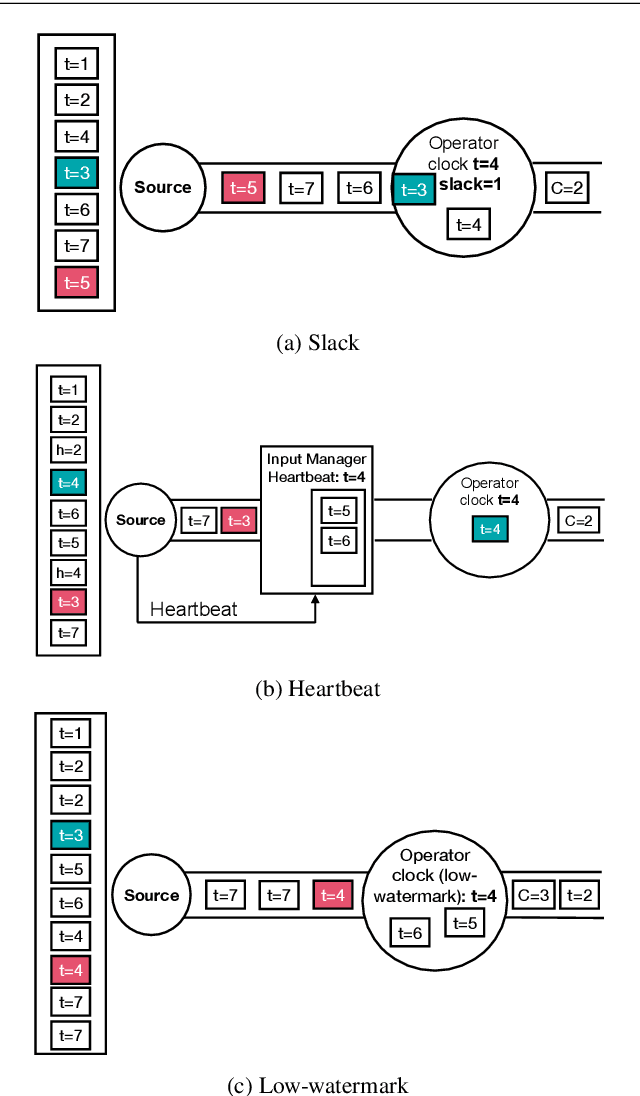
Stream processing has been an active research field for more than 20 years, but it is now witnessing its prime time due to recent successful efforts by the research community and numerous worldwide open-source communities. This survey provides a comprehensive overview of fundamental aspects of stream processing systems and their evolution in the functional areas of out-of-order data management, state management, fault tolerance, high availability, load management, elasticity, and reconfiguration. We review noteworthy past research findings, outline the similarities and differences between early ('00-'10) and modern ('11-'18) streaming systems, and discuss recent trends and open problems.