 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPrep: Closing the Feature Engineering Gap in Tabular Benchmarks
Jun 01, 2026Progress in tabular machine learning has largely focused on increasingly sophisticated model architectures. At the same time, feature engineering remains a critical yet underexplored component of real-world modeling pipelines that is entirely absent from modern benchmarks, which creates an unquantified evaluation gap. In this work, we introduce TabPrep, a lightweight preprocessing pipeline composed of feature generators that are carefully designed to target three specific structural data patterns. We show that many widely used model classes exhibit predictable blind spots to these patterns and that systematic feature engineering alone can establish new peak performance. Across the TabArena benchmark, integrating TabPrep into model training and tuning consistently improves performance for tree-based, neural, linear, and foundation models, often surpassing gains achieved by model-centric innovations alone. TabPrep outperforms previous automated feature engineering approaches in performance, efficiency, and applicability across datasets, enabling integration into large-scale benchmarks. By releasing TabPrep (see https://github.com/atschalz/tabprep), we enable researchers to integrate feature engineering into their benchmarking setup, filling a longstanding gap in tabular evaluations.
Scalable Prompt Routing via Fine-Grained Latent Task Discovery
Mar 23, 2026Prompt routing dynamically selects the most appropriate large language model from a pool of candidates for each query, optimizing performance while managing costs. As model pools scale to include dozens of frontier models with narrow performance gaps, existing approaches face significant challenges: manually defined task taxonomies cannot capture fine-grained capability distinctions, while monolithic routers struggle to differentiate subtle differences across diverse tasks. We propose a two-stage routing architecture that addresses these limitations through automated fine-grained task discovery and task-aware quality estimation. Our first stage employs graph-based clustering to discover latent task types and trains a classifier to assign prompts to discovered tasks. The second stage uses a mixture-of-experts architecture with task-specific prediction heads for specialized quality estimates. At inference, we aggregate predictions from both stages to balance task-level stability with prompt-specific adaptability. Evaluated on 10 benchmarks with 11 frontier models, our method consistently outperforms existing baselines and surpasses the strongest individual model while incurring less than half its cost.
Relatron: Automating Relational Machine Learning over Relational Databases
Feb 26, 2026Predictive modeling over relational databases (RDBs) powers applications, yet remains challenging due to capturing both cross-table dependencies and complex feature interactions. Relational Deep Learning (RDL) methods automate feature engineering via message passing, while classical approaches like Deep Feature Synthesis (DFS) rely on predefined non-parametric aggregators. Despite performance gains, the comparative advantages of RDL over DFS and the design principles for selecting effective architectures remain poorly understood. We present a comprehensive study that unifies RDL and DFS in a shared design space and conducts architecture-centric searches across diverse RDB tasks. Our analysis yields three key findings: (1) RDL does not consistently outperform DFS, with performance being highly task-dependent; (2) no single architecture dominates across tasks, underscoring the need for task-aware model selection; and (3) validation accuracy is an unreliable guide for architecture choice. This search yields a model performance bank that links architecture configurations to their performance; leveraging this bank, we analyze the drivers of the RDL-DFS performance gap and introduce two task signals -- RDB task homophily and an affinity embedding that captures size, path, feature, and temporal structure -- whose correlation with the gap enables principled routing. Guided by these signals, we propose Relatron, a task embedding-based meta-selector that chooses between RDL and DFS and prunes the within-family search. Lightweight loss-landscape metrics further guard against brittle checkpoints by preferring flatter optima. In experiments, Relatron resolves the "more tuning, worse performance" effect and, in joint hyperparameter-architecture optimization, achieves up to 18.5% improvement over strong baselines with 10x lower cost than Fisher information-based alternatives.
ReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models
Feb 23, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising approach for training reasoning language models (RLMs) by leveraging supervision from verifiers. Although verifier implementation is easier than solution annotation for many tasks, existing synthetic data generation methods remain largely solution-centric, while verifier-based methods rely on a few hand-crafted procedural environments. In this work, we scale RLVR by introducing ReSyn, a pipeline that generates diverse reasoning environments equipped with instance generators and verifiers, covering tasks such as constraint satisfaction, algorithmic puzzles, and spatial reasoning. A Qwen2.5-7B-Instruct model trained with RL on ReSyn data achieves consistent gains across reasoning benchmarks and out-of-domain math benchmarks, including a 27\% relative improvement on the challenging BBEH benchmark. Ablations show that verifier-based supervision and increased task diversity both contribute significantly, providing empirical evidence that generating reasoning environments at scale can enhance reasoning abilities in RLMs
Train Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
Generating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modeling
Feb 06, 2026An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or "rubrics", demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models' task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure.
SQL-Trail: Multi-Turn Reinforcement Learning with Interleaved Feedback for Text-to-SQL
Jan 25, 2026While large language models (LLMs) have substantially improved Text-to-SQL generation, a pronounced gap remains between AI systems and human experts on challenging benchmarks such as BIRD-SQL. We argue this gap stems largely from the prevailing single-pass paradigm, which lacks the iterative reasoning, schema exploration, and error-correction behaviors that humans naturally employ. To address this limitation, we introduce SQL-Trail, a multi-turn reinforcement learning (RL) agentic framework for Text-to-SQL. Rather than producing a query in one shot, SQL-Trail interacts with the database environment and uses execution feedback to iteratively refine its predictions. Our approach centers on two key ideas: (i) an adaptive turn-budget allocation mechanism that scales the agent's interaction depth to match question difficulty, and (ii) a composite reward panel that jointly incentivizes SQL correctness and efficient exploration. Across benchmarks, SQL-Trail sets a new state of the art and delivers strong data efficiency--up to 18x higher than prior single-pass RL state-of-the-art methods. Notably, our 7B and 14B models outperform substantially larger proprietary systems by 5% on average, underscoring the effectiveness of interactive, agentic workflows for robust Text-to-SQL generation.
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks
Nov 06, 2025



LLMs can perform multi-step reasoning through Chain-of-Thought (CoT), but they cannot reliably verify their own logic. Even when they reach correct answers, the underlying reasoning may be flawed, undermining trust in high-stakes scenarios. To mitigate this issue, we introduce VeriCoT, a neuro-symbolic method that extracts and verifies formal logical arguments from CoT reasoning. VeriCoT formalizes each CoT reasoning step into first-order logic and identifies premises that ground the argument in source context, commonsense knowledge, or prior reasoning steps. The symbolic representation enables automated solvers to verify logical validity while the NL premises allow humans and systems to identify ungrounded or fallacious reasoning steps. Experiments on the ProofWriter, LegalBench, and BioASQ datasets show VeriCoT effectively identifies flawed reasoning, and serves as a strong predictor of final answer correctness. We also leverage VeriCoT's verification signal for (1) inference-time self-reflection, (2) supervised fine-tuning (SFT) on VeriCoT-distilled datasets and (3) preference fine-tuning (PFT) with direct preference optimization (DPO) using verification-based pairwise rewards, further improving reasoning validity and accuracy.
Hierarchical Lexical Graph for Enhanced Multi-Hop Retrieval
Jun 09, 2025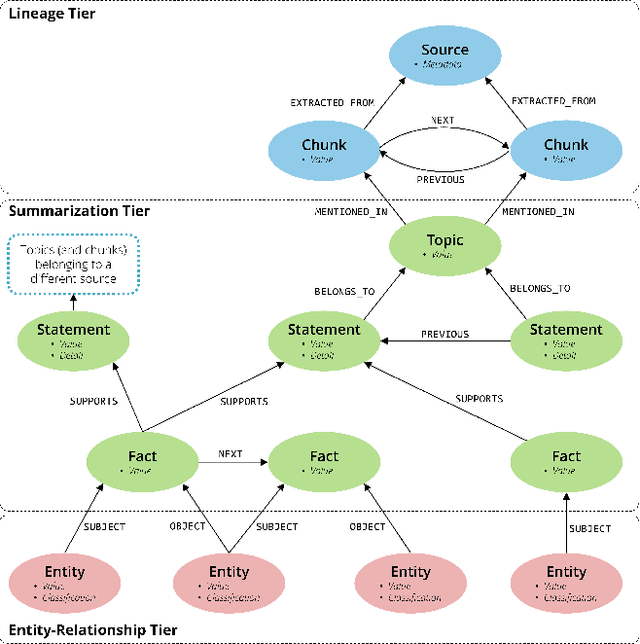

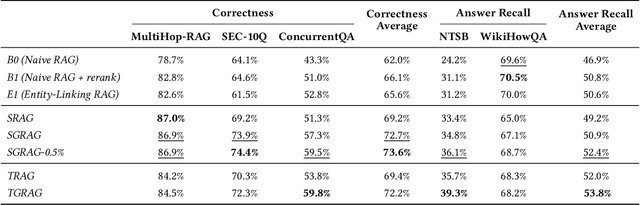
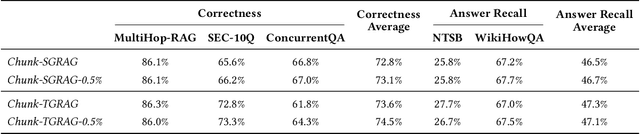
Retrieval-Augmented Generation (RAG) grounds large language models in external evidence, yet it still falters when answers must be pieced together across semantically distant documents. We close this gap with the Hierarchical Lexical Graph (HLG), a three-tier index that (i) traces every atomic proposition to its source, (ii) clusters propositions into latent topics, and (iii) links entities and relations to expose cross-document paths. On top of HLG we build two complementary, plug-and-play retrievers: StatementGraphRAG, which performs fine-grained entity-aware beam search over propositions for high-precision factoid questions, and TopicGraphRAG, which selects coarse topics before expanding along entity links to supply broad yet relevant context for exploratory queries. Additionally, existing benchmarks lack the complexity required to rigorously evaluate multi-hop summarization systems, often focusing on single-document queries or limited datasets. To address this, we introduce a synthetic dataset generation pipeline that curates realistic, multi-document question-answer pairs, enabling robust evaluation of multi-hop retrieval systems. Extensive experiments across five datasets demonstrate that our methods outperform naive chunk-based RAG achieving an average relative improvement of 23.1% in retrieval recall and correctness. Open-source Python library is available at https://github.com/awslabs/graphrag-toolkit.
MLZero: A Multi-Agent System for End-to-end Machine Learning Automation
May 20, 2025Existing AutoML systems have advanced the automation of machine learning (ML); however, they still require substantial manual configuration and expert input, particularly when handling multimodal data. We introduce MLZero, a novel multi-agent framework powered by Large Language Models (LLMs) that enables end-to-end ML automation across diverse data modalities with minimal human intervention. A cognitive perception module is first employed, transforming raw multimodal inputs into perceptual context that effectively guides the subsequent workflow. To address key limitations of LLMs, such as hallucinated code generation and outdated API knowledge, we enhance the iterative code generation process with semantic and episodic memory. MLZero demonstrates superior performance on MLE-Bench Lite, outperforming all competitors in both success rate and solution quality, securing six gold medals. Additionally, when evaluated on our Multimodal AutoML Agent Benchmark, which includes 25 more challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6\%) and an average rank of 2.28. Our approach maintains its robust effectiveness even with a compact 8B LLM, outperforming full-size systems from existing solutions.