 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback Control for Multi-Objective Graph Self-Supervision
Feb 04, 2026Can multi-task self-supervised learning on graphs be coordinated without the usual tug-of-war between objectives? Graph self-supervised learning (SSL) offers a growing toolbox of pretext objectives: mutual information, reconstruction, contrastive learning; yet combining them reliably remains a challenge due to objective interference and training instability. Most multi-pretext pipelines use per-update mixing, forcing every parameter update to be a compromise, leading to three failure modes: Disagreement (conflict-induced negative transfer), Drift (nonstationary objective utility), and Drought (hidden starvation of underserved objectives). We argue that coordination is fundamentally a temporal allocation problem: deciding when each objective receives optimization budget, not merely how to weigh them. We introduce ControlG, a control-theoretic framework that recasts multi-objective graph SSL as feedback-controlled temporal allocation by estimating per-objective difficulty and pairwise antagonism, planning target budgets via a Pareto-aware log-hypervolume planner, and scheduling with a Proportional-Integral-Derivative (PID) controller. Across 9 datasets, ControlG consistently outperforms state-of-the-art baselines, while producing an auditable schedule that reveals which objectives drove learning.
Dynamic Mixture-of-Experts for Incremental Graph Learning
Aug 13, 2025Graph incremental learning is a learning paradigm that aims to adapt trained models to continuously incremented graphs and data over time without the need for retraining on the full dataset. However, regular graph machine learning methods suffer from catastrophic forgetting when applied to incremental learning settings, where previously learned knowledge is overridden by new knowledge. Previous approaches have tried to address this by treating the previously trained model as an inseparable unit and using techniques to maintain old behaviors while learning new knowledge. These approaches, however, do not account for the fact that previously acquired knowledge at different timestamps contributes differently to learning new tasks. Some prior patterns can be transferred to help learn new data, while others may deviate from the new data distribution and be detrimental. To address this, we propose a dynamic mixture-of-experts (DyMoE) approach for incremental learning. Specifically, a DyMoE GNN layer adds new expert networks specialized in modeling the incoming data blocks. We design a customized regularization loss that utilizes data sequence information so existing experts can maintain their ability to solve old tasks while helping the new expert learn the new data effectively. As the number of data blocks grows over time, the computational cost of the full mixture-of-experts (MoE) model increases. To address this, we introduce a sparse MoE approach, where only the top-$k$ most relevant experts make predictions, significantly reducing the computation time. Our model achieved 4.92\% relative accuracy increase compared to the best baselines on class incremental learning, showing the model's exceptional power.
Large Language Model Empowered Privacy-Protected Framework for PHI Annotation in Clinical Notes
Apr 22, 2025
The de-identification of private information in medical data is a crucial process to mitigate the risk of confidentiality breaches, particularly when patient personal details are not adequately removed before the release of medical records. Although rule-based and learning-based methods have been proposed, they often struggle with limited generalizability and require substantial amounts of annotated data for effective performance. Recent advancements in large language models (LLMs) have shown significant promise in addressing these issues due to their superior language comprehension capabilities. However, LLMs present challenges, including potential privacy risks when using commercial LLM APIs and high computational costs for deploying open-source LLMs locally. In this work, we introduce LPPA, an LLM-empowered Privacy-Protected PHI Annotation framework for clinical notes, targeting the English language. By fine-tuning LLMs locally with synthetic notes, LPPA ensures strong privacy protection and high PHI annotation accuracy. Extensive experiments demonstrate LPPA's effectiveness in accurately de-identifying private information, offering a scalable and efficient solution for enhancing patient privacy protection.
AutoG: Towards automatic graph construction from tabular data
Jan 25, 2025



Recent years have witnessed significant advancements in graph machine learning (GML), with its applications spanning numerous domains. However, the focus of GML has predominantly been on developing powerful models, often overlooking a crucial initial step: constructing suitable graphs from common data formats, such as tabular data. This construction process is fundamental to applying graphbased models, yet it remains largely understudied and lacks formalization. Our research aims to address this gap by formalizing the graph construction problem and proposing an effective solution. We identify two critical challenges to achieve this goal: 1. The absence of dedicated datasets to formalize and evaluate the effectiveness of graph construction methods, and 2. Existing automatic construction methods can only be applied to some specific cases, while tedious human engineering is required to generate high-quality graphs. To tackle these challenges, we present a two-fold contribution. First, we introduce a set of datasets to formalize and evaluate graph construction methods. Second, we propose an LLM-based solution, AutoG, automatically generating high-quality graph schemas without human intervention. The experimental results demonstrate that the quality of constructed graphs is critical to downstream task performance, and AutoG can generate high-quality graphs that rival those produced by human experts.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023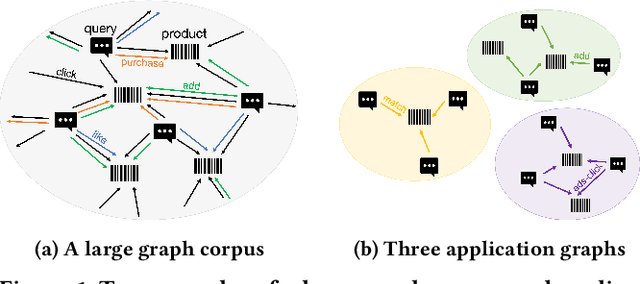
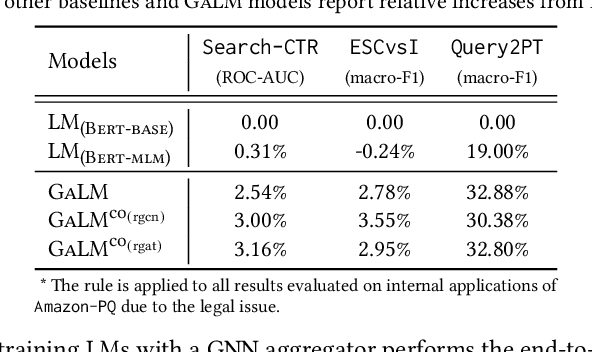
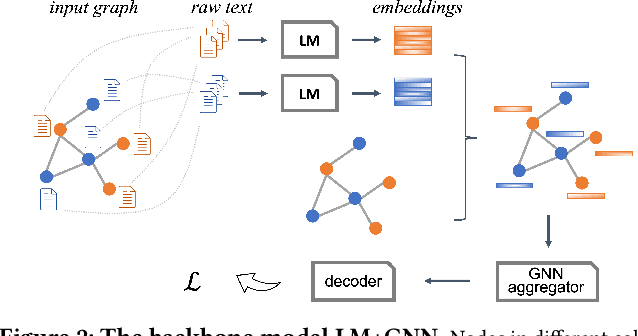
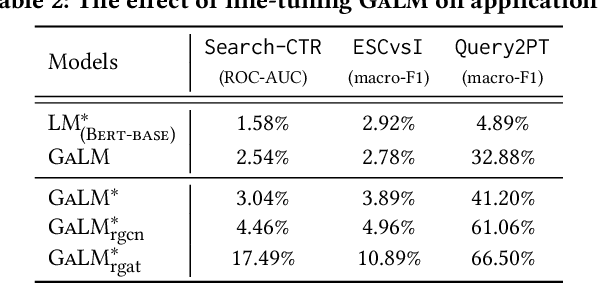
Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.
Semi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline
Nov 19, 2021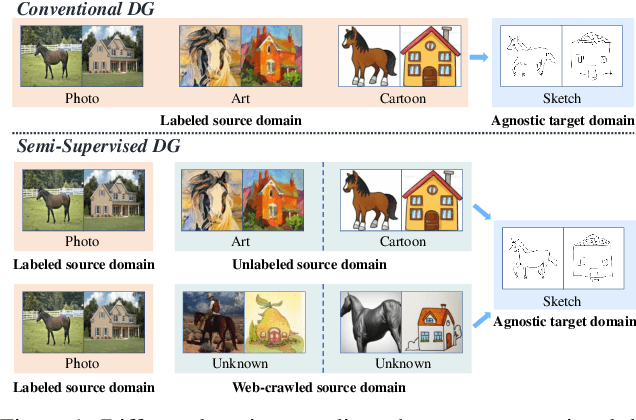
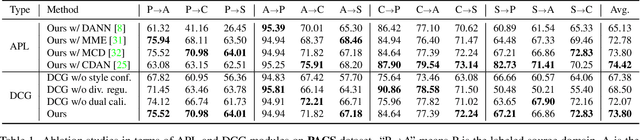
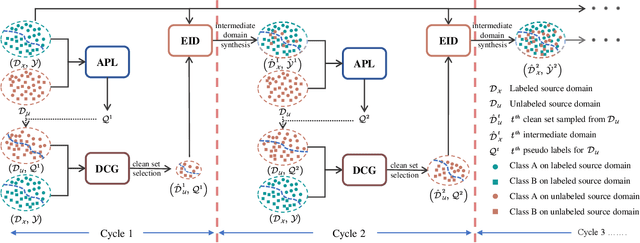
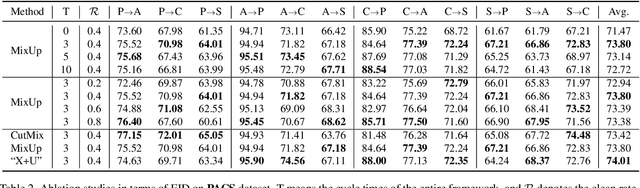
Conventional domain generalization aims to learn domain invariant representation from multiple domains, which requires accurate annotations. In realistic application scenarios, however, it is too cumbersome or even infeasible to collect and annotate the large mass of data. Yet, web data provides a free lunch to access a huge amount of unlabeled data with rich style information that can be harnessed to augment domain generalization ability. In this paper, we introduce a novel task, termed as semi-supervised domain generalization, to study how to interact the labeled and unlabeled domains, and establish two benchmarks including a web-crawled dataset, which poses a novel yet realistic challenge to push the limits of existing technologies. To tackle this task, a straightforward solution is to propagate the class information from the labeled to the unlabeled domains via pseudo labeling in conjunction with domain confusion training. Considering narrowing domain gap can improve the quality of pseudo labels and further advance domain invariant feature learning for generalization, we propose a cycle learning framework to encourage the positive feedback between label propagation and domain generalization, in favor of an evolving intermediate domain bridging the labeled and unlabeled domains in a curriculum learning manner. Experiments are conducted to validate the effectiveness of our framework. It is worth highlighting that web-crawled data benefits domain generalization as demonstrated in our results. Our code will be available later.
Federated Graph Classification over Non-IID Graphs
Jul 23, 2021
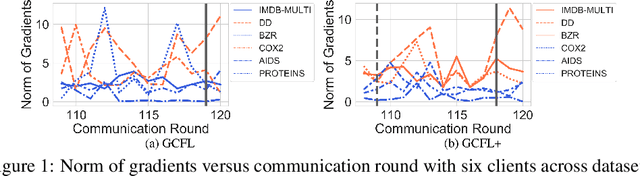

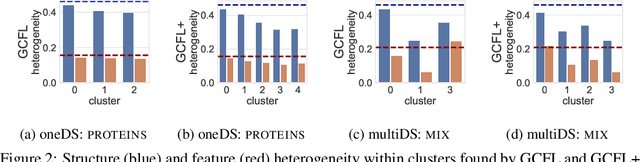
Federated learning has emerged as an important paradigm for training machine learning models in different domains. For graph-level tasks such as graph classification, graphs can also be regarded as a special type of data samples, which can be collected and stored in separate local systems. Similar to other domains, multiple local systems, each holding a small set of graphs, may benefit from collaboratively training a powerful graph mining model, such as the popular graph neural networks (GNNs). To provide more motivation towards such endeavors, we analyze real-world graphs from different domains to confirm that they indeed share certain graph properties that are statistically significant compared with random graphs. However, we also find that different sets of graphs, even from the same domain or same dataset, are non-IID regarding both graph structures and node features. To handle this, we propose a graph clustered federated learning (GCFL) framework that dynamically finds clusters of local systems based on the gradients of GNNs, and theoretically justify that such clusters can reduce the structure and feature heterogeneity among graphs owned by the local systems. Moreover, we observe the gradients of GNNs to be rather fluctuating in GCFL which impedes high-quality clustering, and design a gradient sequence-based clustering mechanism based on dynamic time warping (GCFL+). Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed frameworks.