 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Empowered Privacy-Protected Framework for PHI Annotation in Clinical Notes
Apr 22, 2025
The de-identification of private information in medical data is a crucial process to mitigate the risk of confidentiality breaches, particularly when patient personal details are not adequately removed before the release of medical records. Although rule-based and learning-based methods have been proposed, they often struggle with limited generalizability and require substantial amounts of annotated data for effective performance. Recent advancements in large language models (LLMs) have shown significant promise in addressing these issues due to their superior language comprehension capabilities. However, LLMs present challenges, including potential privacy risks when using commercial LLM APIs and high computational costs for deploying open-source LLMs locally. In this work, we introduce LPPA, an LLM-empowered Privacy-Protected PHI Annotation framework for clinical notes, targeting the English language. By fine-tuning LLMs locally with synthetic notes, LPPA ensures strong privacy protection and high PHI annotation accuracy. Extensive experiments demonstrate LPPA's effectiveness in accurately de-identifying private information, offering a scalable and efficient solution for enhancing patient privacy protection.
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
Aug 13, 2024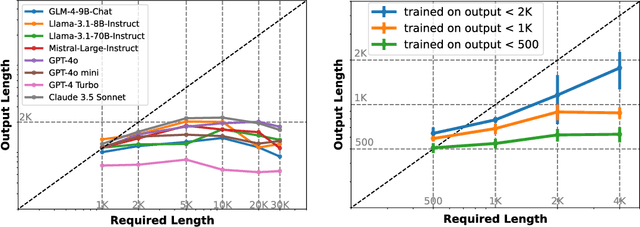


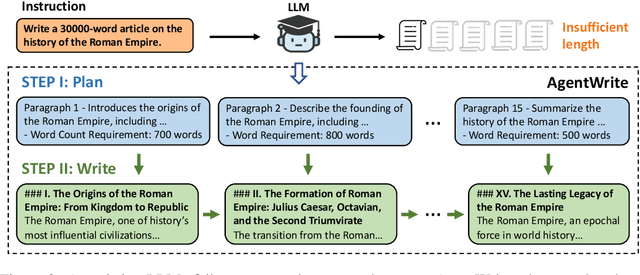
Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words. Through controlled experiments, we find that the model's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning (SFT). In other words, their output limitation is due to the scarcity of long-output examples in existing SFT datasets. To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultra-long generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2k to 32k words. By incorporating this dataset into model training, we successfully scale the output length of existing models to over 10,000 words while maintaining output quality. We also develop LongBench-Write, a comprehensive benchmark for evaluating ultra-long generation capabilities. Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models. In general, our work demonstrates that existing long context LLM already possesses the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability. Our code & models are at: https://github.com/THUDM/LongWriter.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.