 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Probing the Knowledge Boundary: An Interactive Agentic Framework for Deep Knowledge Extraction
Feb 01, 2026Large Language Models (LLMs) can be seen as compressed knowledge bases, but it remains unclear what knowledge they truly contain and how far their knowledge boundaries extend. Existing benchmarks are mostly static and provide limited support for systematic knowledge probing. In this paper, we propose an interactive agentic framework to systematically extract and quantify the knowledge of LLMs. Our method includes four adaptive exploration policies to probe knowledge at different granularities. To ensure the quality of extracted knowledge, we introduce a three-stage knowledge processing pipeline that combines vector-based filtering to remove exact duplicates, LLM-based adjudication to resolve ambiguous semantic overlaps, and domain-relevance auditing to retain valid knowledge units. Through extensive experiments, we find that recursive taxonomy is the most effective exploration strategy. We also observe a clear knowledge scaling law, where larger models consistently extract more knowledge. In addition, we identify a Pass@1-versus-Pass@k trade-off: domain-specialized models achieve higher initial accuracy but degrade rapidly, while general-purpose models maintain stable performance during extended extraction. Finally, our results show that differences in training data composition lead to distinct and measurable knowledge profiles across model families.
SRT: Accelerating Reinforcement Learning via Speculative Rollout with Tree-Structured Cache
Jan 14, 2026We present Speculative Rollout with Tree-Structured Cache (SRT), a simple, model-free approach to accelerate on-policy reinforcement learning (RL) for language models without sacrificing distributional correctness. SRT exploits the empirical similarity of rollouts for the same prompt across training steps by storing previously generated continuations in a per-prompt tree-structured cache. During generation, the current policy uses this tree as the draft model for performing speculative decoding. To keep the cache fresh and improve draft model quality, SRT updates trees online from ongoing rollouts and proactively performs run-ahead generation during idle GPU bubbles. Integrated into standard RL pipelines (\textit{e.g.}, PPO, GRPO and DAPO) and multi-turn settings, SRT consistently reduces generation and step latency and lowers per-token inference cost, achieving up to 2.08x wall-clock time speedup during rollout.
OpenTinker: Separating Concerns in Agentic Reinforcement Learning
Jan 12, 2026We introduce OpenTinker, an infrastructure for reinforcement learning (RL) of large language model (LLM) agents built around a separation of concerns across algorithm design, execution, and agent-environment interaction. Rather than relying on monolithic, end-to-end RL pipelines, OpenTinker decomposes agentic learning systems into lightweight, composable components with clearly defined abstraction boundaries. Users specify agents, environments, and interaction protocols, while inference and training are delegated to a managed execution runtime. OpenTinker introduces a centralized scheduler for managing training and inference workloads, including LoRA-based and full-parameter RL, supervised fine-tuning, and inference, over shared resources. We further discuss design principles for extending OpenTinker to multi-agent training. Finally, we present a set of RL use cases that demonstrate the effectiveness of the framework in practical agentic learning scenarios.
Federated Learning and Class Imbalances
Jan 09, 2026Federated Learning (FL) enables collaborative model training across decentralized devices while preserving data privacy. However, real-world FL deployments face critical challenges such as data imbalances, including label noise and non-IID distributions. RHFL+, a state-of-the-art method, was proposed to address these challenges in settings with heterogeneous client models. This work investigates the robustness of RHFL+ under class imbalances through three key contributions: (1) reproduction of RHFL+ along with all benchmark algorithms under a unified evaluation framework; (2) extension of RHFL+ to real-world medical imaging datasets, including CBIS-DDSM, BreastMNIST and BHI; (3) a novel implementation using NVFlare, NVIDIA's production-level federated learning framework, enabling a modular, scalable and deployment-ready codebase. To validate effectiveness, extensive ablation studies, algorithmic comparisons under various noise conditions and scalability experiments across increasing numbers of clients are conducted.
Human Motion Estimation with Everyday Wearables
Dec 24, 2025While on-body device-based human motion estimation is crucial for applications such as XR interaction, existing methods often suffer from poor wearability, expensive hardware, and cumbersome calibration, which hinder their adoption in daily life. To address these challenges, we present EveryWear, a lightweight and practical human motion capture approach based entirely on everyday wearables: a smartphone, smartwatch, earbuds, and smart glasses equipped with one forward-facing and two downward-facing cameras, requiring no explicit calibration before use. We introduce Ego-Elec, a 9-hour real-world dataset covering 56 daily activities across 17 diverse indoor and outdoor environments, with ground-truth 3D annotations provided by the motion capture (MoCap), to facilitate robust research and benchmarking in this direction. Our approach employs a multimodal teacher-student framework that integrates visual cues from egocentric cameras with inertial signals from consumer devices. By training directly on real-world data rather than synthetic data, our model effectively eliminates the sim-to-real gap that constrains prior work. Experiments demonstrate that our method outperforms baseline models, validating its effectiveness for practical full-body motion estimation.
Mesh-Attention: A New Communication-Efficient Distributed Attention with Improved Data Locality
Dec 24, 2025Distributed attention is a fundamental problem for scaling context window for Large Language Models (LLMs). The state-of-the-art method, Ring-Attention, suffers from scalability limitations due to its excessive communication traffic. This paper proposes a new distributed attention algorithm, Mesh-Attention, by rethinking the design space of distributed attention with a new matrix-based model. Our method assigns a two-dimensional tile -- rather than one-dimensional row or column -- of computation blocks to each GPU to achieve higher efficiency through lower communication-computation (CommCom) ratio. The general approach covers Ring-Attention as a special case, and allows the tuning of CommCom ratio with different tile shapes. Importantly, we propose a greedy algorithm that can efficiently search the scheduling space within the tile with restrictions that ensure efficient communication among GPUs. The theoretical analysis shows that Mesh-Attention leads to a much lower communication complexity and exhibits good scalability comparing to other current algorithms. Our extensive experiment results show that Mesh-Attention can achieve up to 3.4x speedup (2.9x on average) and reduce the communication volume by up to 85.4% (79.0% on average) on 256 GPUs. Our scalability results further demonstrate that Mesh-Attention sustains superior performance as the system scales, substantially reducing overhead in large-scale deployments. The results convincingly confirm the advantage of Mesh-Attention.
Efficiently Serving LLM Reasoning Programs with Certaindex
Dec 30, 2024



The rapid evolution of large language models (LLMs) has unlocked their capabilities in advanced reasoning tasks like mathematical problem-solving, code generation, and legal analysis. Central to this progress are inference-time reasoning algorithms, which refine outputs by exploring multiple solution paths, at the cost of increasing compute demands and response latencies. Existing serving systems fail to adapt to the scaling behaviors of these algorithms or the varying difficulty of queries, leading to inefficient resource use and unmet latency targets. We present Dynasor, a system that optimizes inference-time compute for LLM reasoning queries. Unlike traditional engines, Dynasor tracks and schedules requests within reasoning queries and uses Certaindex, a proxy that measures statistical reasoning progress based on model certainty, to guide compute allocation dynamically. Dynasor co-adapts scheduling with reasoning progress: it allocates more compute to hard queries, reduces compute for simpler ones, and terminates unpromising queries early, balancing accuracy, latency, and cost. On diverse datasets and algorithms, Dynasor reduces compute by up to 50% in batch processing and sustaining 3.3x higher query rates or 4.7x tighter latency SLOs in online serving.
Efficient LLM Scheduling by Learning to Rank
Aug 28, 2024

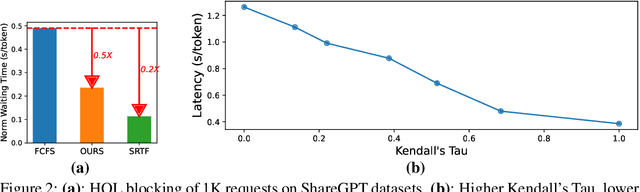

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-Of-Line (HOL) blocking and reduced throughput and service quality. In this paper, we reexamine this assumption -- we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank. The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches. We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation. Our code is available at https://github.com/hao-ai-lab/vllm-ltr.git
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
Aug 13, 2024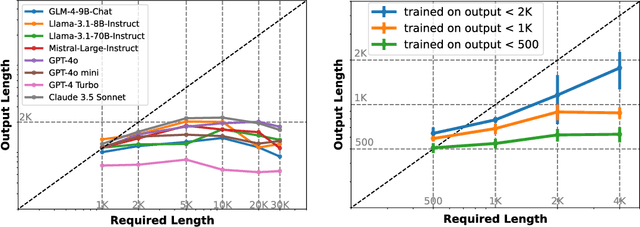


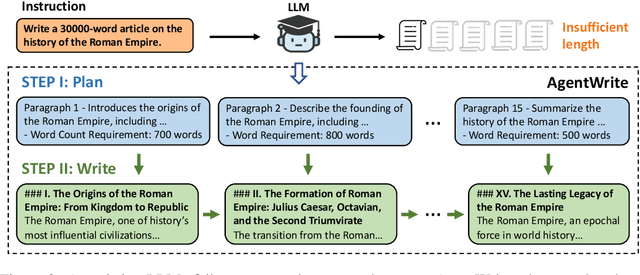
Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words. Through controlled experiments, we find that the model's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning (SFT). In other words, their output limitation is due to the scarcity of long-output examples in existing SFT datasets. To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultra-long generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2k to 32k words. By incorporating this dataset into model training, we successfully scale the output length of existing models to over 10,000 words while maintaining output quality. We also develop LongBench-Write, a comprehensive benchmark for evaluating ultra-long generation capabilities. Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models. In general, our work demonstrates that existing long context LLM already possesses the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability. Our code & models are at: https://github.com/THUDM/LongWriter.