 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastKernels: Benchmarking GPU Kernel Generation in Production
May 22, 2026LLM-based agents for GPU kernel generation are advancing rapidly, yet their progress is fundamentally constrained by the benchmarks they optimize against. Existing benchmarks are poorly aligned with production inference frameworks: they evaluate kernels on a single GPU with synthetic inputs, ignore the surrounding compilation stack, and reward replicating known optimizations rather than discovering new ones. The resulting reward signals are misleading: agents learn to generate kernels that score well in sandboxes but introduce interface incompatibilities, compilation-stack conflicts, and silent correctness degradation when integrated into real systems. We introduce FastKernels, a kernel benchmark built around a minimal set of 46 representative architectures spanning 8 categories, whose kernels collectively subsume those of 96.2% (409/425) of HuggingFace Transformers architectures. FastKernels doubles as a minimalistic, production-grade inference framework that runs at parity with hardened systems such as vLLM and SGLang on mainstream LLM serving and substantially exceeds upstream references on under-served architectures; each task's interface mirrors the corresponding module in the state-of-the-art library for its architecture family, enabling direct deployment of optimized kernels into production codebases. Evaluating state-of-the-art kernel agents on FastKernels, we find that even the strongest agent achieves only 0.94$\times$ aggregate speedup over production baselines, with weaker agents at $0.78\times$ and $0.53\times$ -- confirming that benchmark-production misalignment is a critical bottleneck for the field. We release FastKernels as a stepping stone toward kernel agents whose benchmark gains translate directly into production throughput improvements. Code is available at https://github.com/Snowflake-AI-Research/fastkernels
Internalizing Agency from Reflective Experience
Mar 17, 2026Large language models are increasingly deployed as autonomous agents that must plan, act, and recover from mistakes through long-horizon interaction with environments that provide rich feedback. However, prevailing outcome-driven post-training methods (e.g., RL with verifiable rewards) primarily optimize final success signals, leaving rich environment feedback underutilized. Consequently, they often lead to distribution sharpening: the policy becomes better at reproducing a narrow set of already-successful behaviors, while failing to improve the feedback-grounded agency needed to expand problem-solving capacity (e.g., Pass@k) in long-horizon settings. To address this, we propose LEAFE (Learning Feedback-Grounded Agency from Reflective Experience), a framework that internalizes recovery agency from reflective experience. Specifically, during exploration, the agent summarizes environment feedback into actionable experience, backtracks to earlier decision points, and explores alternative branches with revised actions. We then distill these experience-guided corrections into the model through supervised fine-tuning, enabling the policy to recover more effectively in future interactions. Across a diverse set of interactive coding and agentic tasks under fixed interaction budgets, LEAFE consistently improves Pass@1 over the base model and achieves higher Pass@k than outcome-driven baselines (GRPO) and experience-based methods such as Early Experience, with gains of up to 14% on Pass@128.
When Drafts Evolve: Speculative Decoding Meets Online Learning
Mar 13, 2026Speculative decoding has emerged as a widely adopted paradigm for accelerating large language model inference, where a lightweight draft model rapidly generates candidate tokens that are then verified in parallel by a larger target model. However, due to limited model capacity, drafts often struggle to approximate the target distribution, resulting in shorter acceptance lengths and diminished speedup. A key yet under-explored observation is that speculative decoding inherently provides verification feedback that quantifies the deviation between the draft and target models at no additional cost. This process naturally forms an iterative "draft commits-feedback provides-draft adapts" evolving loop, which precisely matches the online learning paradigm. Motivated by this connection, we propose OnlineSpec, a unified framework that systematically leverages interactive feedback to continuously evolve draft models. Grounded in dynamic regret minimization, we establish a formal link between online learning performance and speculative system's acceleration rate, and develop novel algorithms via modern online learning techniques, including optimistic online learning that adaptively reuses historical gradients as predictive update hints, and online ensemble learning that dynamically maintains multiple draft models. Our algorithms are equipped with theoretical justifications and improved acceleration rates, achieving up to 24% speedup over seven benchmarks and three foundation models.
Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
Scaling Speculative Decoding with Lookahead Reasoning
Jun 24, 2025Reasoning models excel by generating long chain-of-thoughts, but decoding the resulting thousands of tokens is slow. Token-level speculative decoding (SD) helps, but its benefit is capped, because the chance that an entire $\gamma$-token guess is correct falls exponentially as $\gamma$ grows. This means allocating more compute for longer token drafts faces an algorithmic ceiling -- making the speedup modest and hardware-agnostic. We raise this ceiling with Lookahead Reasoning, which exploits a second, step-level layer of parallelism. Our key insight is that reasoning models generate step-by-step, and each step needs only to be semantically correct, not exact token matching. In Lookahead Reasoning, a lightweight draft model proposes several future steps; the target model expands each proposal in one batched pass, and a verifier keeps semantically correct steps while letting the target regenerate any that fail. Token-level SD still operates within each reasoning step, so the two layers of parallelism multiply. We show Lookahead Reasoning lifts the peak speedup of SD both theoretically and empirically. Across GSM8K, AIME, and other benchmarks, Lookahead Reasoning improves the speedup of SD from 1.4x to 2.1x while preserving answer quality, and its speedup scales better with additional GPU throughput. Our code is available at https://github.com/hao-ai-lab/LookaheadReasoning
Matrix Factorization with Dynamic Multi-view Clustering for Recommender System
Apr 20, 2025Matrix factorization (MF), a cornerstone of recommender systems, decomposes user-item interaction matrices into latent representations. Traditional MF approaches, however, employ a two-stage, non-end-to-end paradigm, sequentially performing recommendation and clustering, resulting in prohibitive computational costs for large-scale applications like e-commerce and IoT, where billions of users interact with trillions of items. To address this, we propose Matrix Factorization with Dynamic Multi-view Clustering (MFDMC), a unified framework that balances efficient end-to-end training with comprehensive utilization of web-scale data and enhances interpretability. MFDMC leverages dynamic multi-view clustering to learn user and item representations, adaptively pruning poorly formed clusters. Each entity's representation is modeled as a weighted projection of robust clusters, capturing its diverse roles across views. This design maximizes representation space utilization, improves interpretability, and ensures resilience for downstream tasks. Extensive experiments demonstrate MFDMC's superior performance in recommender systems and other representation learning domains, such as computer vision, highlighting its scalability and versatility.
Efficiently Serving LLM Reasoning Programs with Certaindex
Dec 30, 2024



The rapid evolution of large language models (LLMs) has unlocked their capabilities in advanced reasoning tasks like mathematical problem-solving, code generation, and legal analysis. Central to this progress are inference-time reasoning algorithms, which refine outputs by exploring multiple solution paths, at the cost of increasing compute demands and response latencies. Existing serving systems fail to adapt to the scaling behaviors of these algorithms or the varying difficulty of queries, leading to inefficient resource use and unmet latency targets. We present Dynasor, a system that optimizes inference-time compute for LLM reasoning queries. Unlike traditional engines, Dynasor tracks and schedules requests within reasoning queries and uses Certaindex, a proxy that measures statistical reasoning progress based on model certainty, to guide compute allocation dynamically. Dynasor co-adapts scheduling with reasoning progress: it allocates more compute to hard queries, reduces compute for simpler ones, and terminates unpromising queries early, balancing accuracy, latency, and cost. On diverse datasets and algorithms, Dynasor reduces compute by up to 50% in batch processing and sustaining 3.3x higher query rates or 4.7x tighter latency SLOs in online serving.
KA$^2$ER: Knowledge Adaptive Amalgamation of ExpeRts for Medical Images Segmentation
Oct 28, 2024Recently, many foundation models for medical image analysis such as MedSAM, SwinUNETR have been released and proven to be useful in multiple tasks. However, considering the inherent heterogeneity and inhomogeneity of real-world medical data, directly applying these models to specific medical image segmentation tasks often leads to negative domain shift effects, which can severely weaken the model's segmentation capabilities. To this end, we propose an adaptive amalgamation knowledge framework that aims to train a versatile foundation model to handle the joint goals of multiple expert models, each specialized for a distinct task. Specifically, we first train an nnUNet-based expert model for each task, and reuse the pre-trained SwinUNTER as the target foundation model. Then, the input data for all challenging tasks are encoded in the foundation model and the expert models, respectively, and their backbone features are jointly projected into the adaptive amalgamation layer. Within the hidden layer, the hierarchical attention mechanisms are designed to achieve adaptive merging of the target model to the hidden layer feature knowledge of all experts, which significantly reduces the domain shift arising from the inter-task differences. Finally, the gold amalgamated features and the prompt features are fed into the mask decoder to obtain the segmentation results. Extensive experiments conducted in these challenging tasks demonstrate the effectiveness and adaptability of our foundation model for real-world medical image segmentation.
Efficient LLM Scheduling by Learning to Rank
Aug 28, 2024

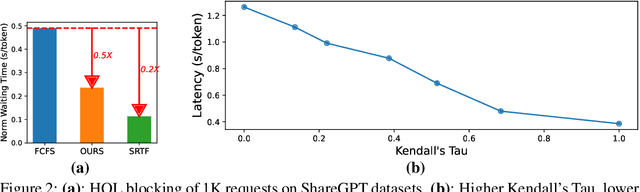

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-Of-Line (HOL) blocking and reduced throughput and service quality. In this paper, we reexamine this assumption -- we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank. The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches. We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation. Our code is available at https://github.com/hao-ai-lab/vllm-ltr.git
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Jun 11, 2024Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$\times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.