 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR$^{2}$Seg: Training-Free OOD Medical Tumor Segmentation via Anatomical Reasoning and Statistical Rejection
Nov 16, 2025Foundation models for medical image segmentation struggle under out-of-distribution (OOD) shifts, often producing fragmented false positives on OOD tumors. We introduce R$^{2}$Seg, a training-free framework for robust OOD tumor segmentation that operates via a two-stage Reason-and-Reject process. First, the Reason step employs an LLM-guided anatomical reasoning planner to localize organ anchors and generate multi-scale ROIs. Second, the Reject step applies two-sample statistical testing to candidates generated by a frozen foundation model (BiomedParse) within these ROIs. This statistical rejection filter retains only candidates significantly different from normal tissue, effectively suppressing false positives. Our framework requires no parameter updates, making it compatible with zero-update test-time augmentation and avoiding catastrophic forgetting. On multi-center and multi-modal tumor segmentation benchmarks, R$^{2}$Seg substantially improves Dice, specificity, and sensitivity over strong baselines and the original foundation models. Code are available at https://github.com/Eurekashen/R2Seg.
Enhancing Demand-Oriented Regionalization with Agentic AI and Local Heterogeneous Data for Adaptation Planning
Nov 13, 2025Conventional planning units or urban regions, such as census tracts, zip codes, or neighborhoods, often do not capture the specific demands of local communities and lack the flexibility to implement effective strategies for hazard prevention or response. To support the creation of dynamic planning units, we introduce a planning support system with agentic AI that enables users to generate demand-oriented regions for disaster planning, integrating the human-in-the-loop principle for transparency and adaptability. The platform is built on a representative initialized spatially constrained self-organizing map (RepSC-SOM), extending traditional SOM with adaptive geographic filtering and region-growing refinement, while AI agents can reason, plan, and act to guide the process by suggesting input features, guiding spatial constraints, and supporting interactive exploration. We demonstrate the capabilities of the platform through a case study on the flooding-related risk in Jacksonville, Florida, showing how it allows users to explore, generate, and evaluate regionalization interactively, combining computational rigor with user-driven decision making.
Uncertainty-Aware Multi-Expert Knowledge Distillation for Imbalanced Disease Grading
May 01, 2025Automatic disease image grading is a significant application of artificial intelligence for healthcare, enabling faster and more accurate patient assessments. However, domain shifts, which are exacerbated by data imbalance, introduce bias into the model, posing deployment difficulties in clinical applications. To address the problem, we propose a novel \textbf{U}ncertainty-aware \textbf{M}ulti-experts \textbf{K}nowledge \textbf{D}istillation (UMKD) framework to transfer knowledge from multiple expert models to a single student model. Specifically, to extract discriminative features, UMKD decouples task-agnostic and task-specific features with shallow and compact feature alignment in the feature space. At the output space, an uncertainty-aware decoupled distillation (UDD) mechanism dynamically adjusts knowledge transfer weights based on expert model uncertainties, ensuring robust and reliable distillation. Additionally, UMKD also tackles the problems of model architecture heterogeneity and distribution discrepancies between source and target domains, which are inadequately tackled by previous KD approaches. Extensive experiments on histology prostate grading (\textit{SICAPv2}) and fundus image grading (\textit{APTOS}) demonstrate that UMKD achieves a new state-of-the-art in both source-imbalanced and target-imbalanced scenarios, offering a robust and practical solution for real-world disease image grading.
Matrix Factorization with Dynamic Multi-view Clustering for Recommender System
Apr 20, 2025Matrix factorization (MF), a cornerstone of recommender systems, decomposes user-item interaction matrices into latent representations. Traditional MF approaches, however, employ a two-stage, non-end-to-end paradigm, sequentially performing recommendation and clustering, resulting in prohibitive computational costs for large-scale applications like e-commerce and IoT, where billions of users interact with trillions of items. To address this, we propose Matrix Factorization with Dynamic Multi-view Clustering (MFDMC), a unified framework that balances efficient end-to-end training with comprehensive utilization of web-scale data and enhances interpretability. MFDMC leverages dynamic multi-view clustering to learn user and item representations, adaptively pruning poorly formed clusters. Each entity's representation is modeled as a weighted projection of robust clusters, capturing its diverse roles across views. This design maximizes representation space utilization, improves interpretability, and ensures resilience for downstream tasks. Extensive experiments demonstrate MFDMC's superior performance in recommender systems and other representation learning domains, such as computer vision, highlighting its scalability and versatility.
KA$^2$ER: Knowledge Adaptive Amalgamation of ExpeRts for Medical Images Segmentation
Oct 28, 2024Recently, many foundation models for medical image analysis such as MedSAM, SwinUNETR have been released and proven to be useful in multiple tasks. However, considering the inherent heterogeneity and inhomogeneity of real-world medical data, directly applying these models to specific medical image segmentation tasks often leads to negative domain shift effects, which can severely weaken the model's segmentation capabilities. To this end, we propose an adaptive amalgamation knowledge framework that aims to train a versatile foundation model to handle the joint goals of multiple expert models, each specialized for a distinct task. Specifically, we first train an nnUNet-based expert model for each task, and reuse the pre-trained SwinUNTER as the target foundation model. Then, the input data for all challenging tasks are encoded in the foundation model and the expert models, respectively, and their backbone features are jointly projected into the adaptive amalgamation layer. Within the hidden layer, the hierarchical attention mechanisms are designed to achieve adaptive merging of the target model to the hidden layer feature knowledge of all experts, which significantly reduces the domain shift arising from the inter-task differences. Finally, the gold amalgamated features and the prompt features are fed into the mask decoder to obtain the segmentation results. Extensive experiments conducted in these challenging tasks demonstrate the effectiveness and adaptability of our foundation model for real-world medical image segmentation.
Unified Matrix Factorization with Dynamic Multi-view Clustering
Aug 13, 2023



Matrix factorization (MF) is a classical collaborative filtering algorithm for recommender systems. It decomposes the user-item interaction matrix into a product of low-dimensional user representation matrix and item representation matrix. In typical recommendation scenarios, the user-item interaction paradigm is usually a two-stage process and requires static clustering analysis of the obtained user and item representations. The above process, however, is time and computationally intensive, making it difficult to apply in real-time to e-commerce or Internet of Things environments with billions of users and trillions of items. To address this, we propose a unified matrix factorization method based on dynamic multi-view clustering (MFDMC) that employs an end-to-end training paradigm. Specifically, in each view, a user/item representation is regarded as a weighted projection of all clusters. The representation of each cluster is learnable, enabling the dynamic discarding of bad clusters. Furthermore, we employ multi-view clustering to represent multiple roles of users/items, effectively utilizing the representation space and improving the interpretability of the user/item representations for downstream tasks. Extensive experiments show that our proposed MFDMC achieves state-of-the-art performance on real-world recommendation datasets. Additionally, comprehensive visualization and ablation studies interpretably confirm that our method provides meaningful representations for downstream tasks of users/items.
Contrastive Knowledge Amalgamation for Unsupervised Image Classification
Jul 27, 2023Knowledge amalgamation (KA) aims to learn a compact student model to handle the joint objective from multiple teacher models that are are specialized for their own tasks respectively. Current methods focus on coarsely aligning teachers and students in the common representation space, making it difficult for the student to learn the proper decision boundaries from a set of heterogeneous teachers. Besides, the KL divergence in previous works only minimizes the probability distribution difference between teachers and the student, ignoring the intrinsic characteristics of teachers. Therefore, we propose a novel Contrastive Knowledge Amalgamation (CKA) framework, which introduces contrastive losses and an alignment loss to achieve intra-class cohesion and inter-class separation.Contrastive losses intra- and inter- models are designed to widen the distance between representations of different classes. The alignment loss is introduced to minimize the sample-level distribution differences of teacher-student models in the common representation space.Furthermore, the student learns heterogeneous unsupervised classification tasks through soft targets efficiently and flexibly in the task-level amalgamation. Extensive experiments on benchmarks demonstrate the generalization capability of CKA in the amalgamation of specific task as well as multiple tasks. Comprehensive ablation studies provide a further insight into our CKA.
Interest-oriented Universal User Representation via Contrastive Learning
Sep 18, 2021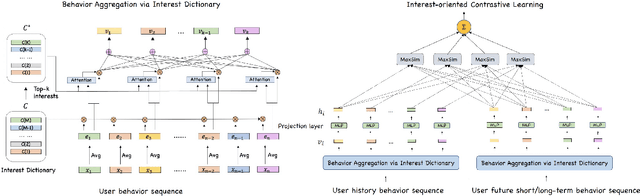
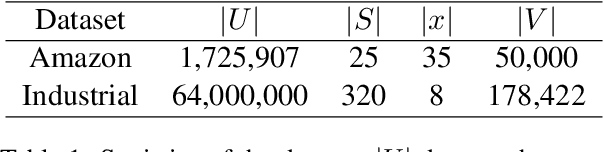
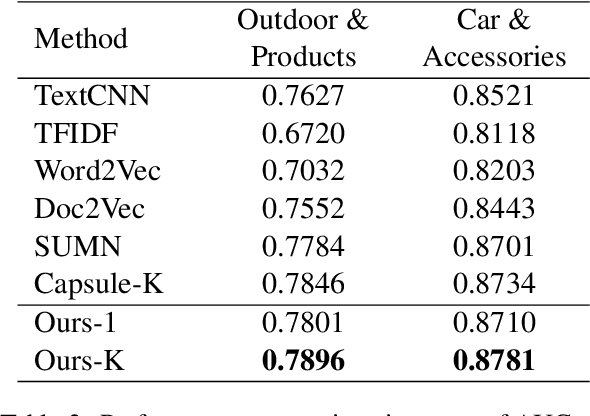
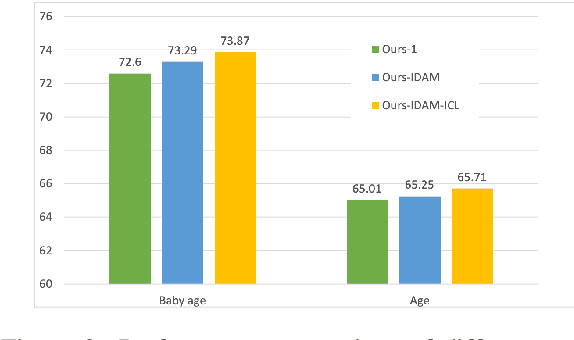
User representation is essential for providing high-quality commercial services in industry. Universal user representation has received many interests recently, with which we can be free from the cumbersome work of training a specific model for each downstream application. In this paper, we attempt to improve universal user representation from two points of views. First, a contrastive self-supervised learning paradigm is presented to guide the representation model training. It provides a unified framework that allows for long-term or short-term interest representation learning in a data-driven manner. Moreover, a novel multi-interest extraction module is presented. The module introduces an interest dictionary to capture principal interests of the given user, and then generate his/her interest-oriented representations via behavior aggregation. Experimental results demonstrate the effectiveness and applicability of the learned user representations.
Can Predominant Credible Information Suppress Misinformation in Crises? Empirical Studies of Tweets Related to Prevention Measures during COVID-19
Feb 01, 2021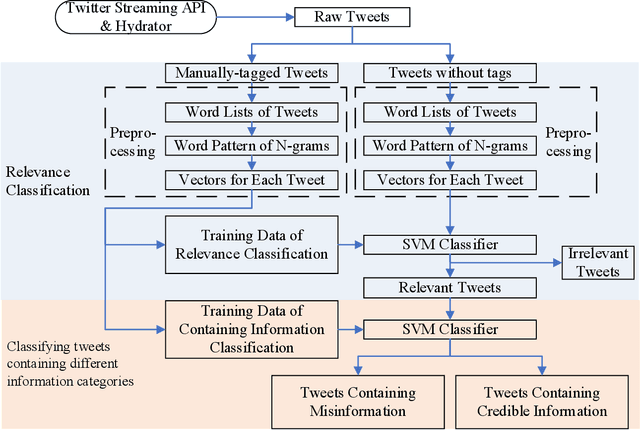
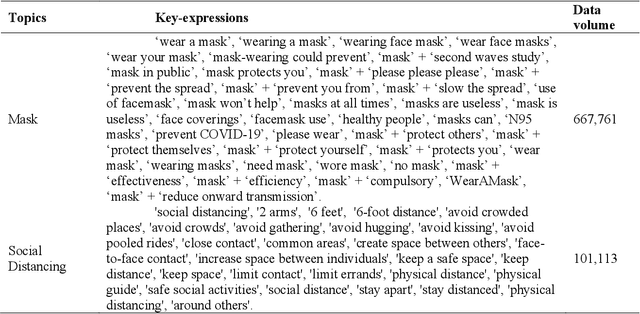
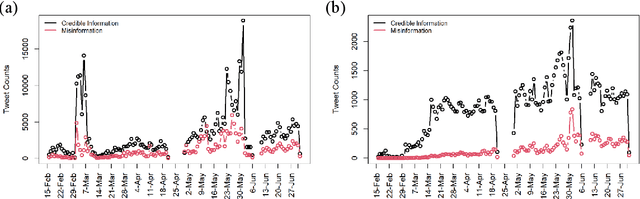
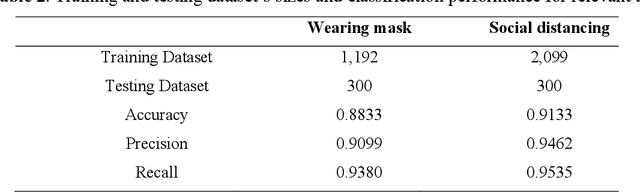
During COVID-19, misinformation on social media affects the adoption of appropriate prevention behaviors. It is urgent to suppress the misinformation to prevent negative public health consequences. Although an array of studies has proposed misinformation suppression strategies, few have investigated the role of predominant credible information during crises. None has examined its effect quantitatively using longitudinal social media data. Therefore, this research investigates the temporal correlations between credible information and misinformation, and whether predominant credible information can suppress misinformation for two prevention measures (i.e. topics), i.e. wearing masks and social distancing using tweets collected from February 15 to June 30, 2020. We trained Support Vector Machine classifiers to retrieve relevant tweets and classify tweets containing credible information and misinformation for each topic. Based on cross-correlation analyses of credible and misinformation time series for both topics, we find that the previously predominant credible information can lead to the decrease of misinformation (i.e. suppression) with a time lag. The research findings provide empirical evidence for suppressing misinformation with credible information in complex online environments and suggest practical strategies for future information management during crises and emergencies.