 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
UniMatch: A Unified User-Item Matching Framework for the Multi-purpose Merchant Marketing
Jul 19, 2023



When doing private domain marketing with cloud services, the merchants usually have to purchase different machine learning models for the multiple marketing purposes, leading to a very high cost. We present a unified user-item matching framework to simultaneously conduct item recommendation and user targeting with just one model. We empirically demonstrate that the above concurrent modeling is viable via modeling the user-item interaction matrix with the multinomial distribution, and propose a bidirectional bias-corrected NCE loss for the implementation. The proposed loss function guides the model to learn the user-item joint probability $p(u,i)$ instead of the conditional probability $p(i|u)$ or $p(u|i)$ through correcting both the users and items' biases caused by the in-batch negative sampling. In addition, our framework is model-agnostic enabling a flexible adaptation of different model architectures. Extensive experiments demonstrate that our framework results in significant performance gains in comparison with the state-of-the-art methods, with greatly reduced cost on computing resources and daily maintenance.
Uniform Sequence Better: Time Interval Aware Data Augmentation for Sequential Recommendation
Dec 16, 2022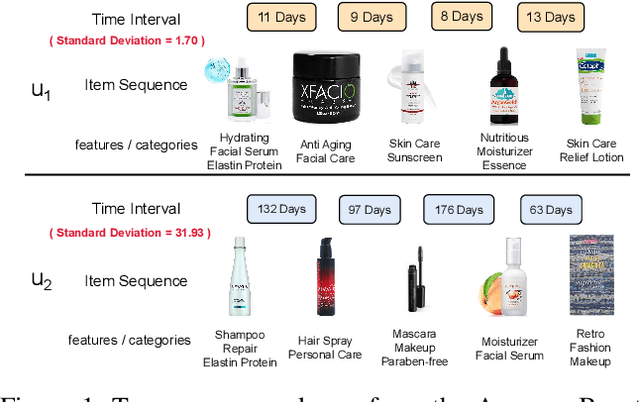
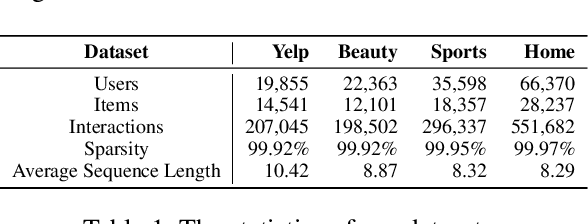
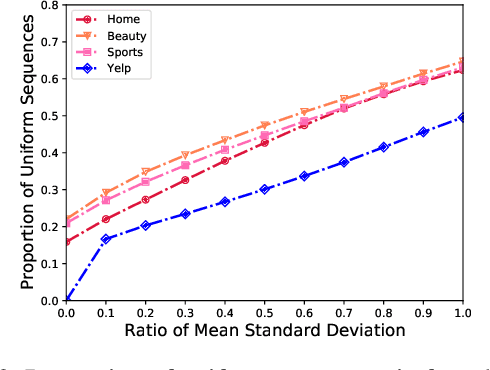
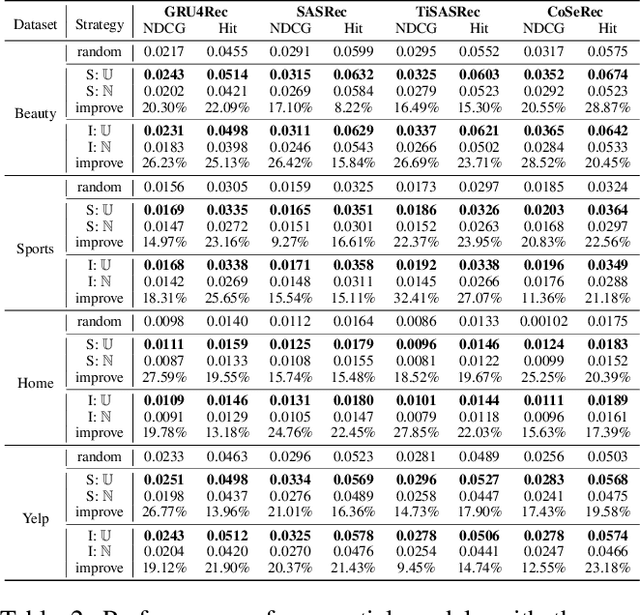
Sequential recommendation is an important task to predict the next-item to access based on a sequence of interacted items. Most existing works learn user preference as the transition pattern from the previous item to the next one, ignoring the time interval between these two items. However, we observe that the time interval in a sequence may vary significantly different, and thus result in the ineffectiveness of user modeling due to the issue of \emph{preference drift}. In fact, we conducted an empirical study to validate this observation, and found that a sequence with uniformly distributed time interval (denoted as uniform sequence) is more beneficial for performance improvement than that with greatly varying time interval. Therefore, we propose to augment sequence data from the perspective of time interval, which is not studied in the literature. Specifically, we design five operators (Ti-Crop, Ti-Reorder, Ti-Mask, Ti-Substitute, Ti-Insert) to transform the original non-uniform sequence to uniform sequence with the consideration of variance of time intervals. Then, we devise a control strategy to execute data augmentation on item sequences in different lengths. Finally, we implement these improvements on a state-of-the-art model CoSeRec and validate our approach on four real datasets. The experimental results show that our approach reaches significantly better performance than the other 11 competing methods. Our implementation is available: https://github.com/KingGugu/TiCoSeRec.
Interest-oriented Universal User Representation via Contrastive Learning
Sep 18, 2021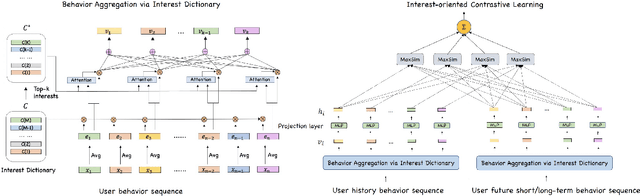
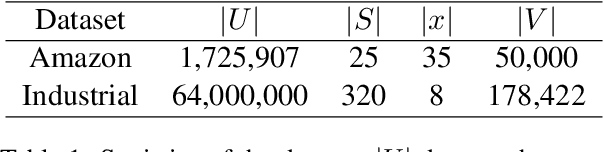
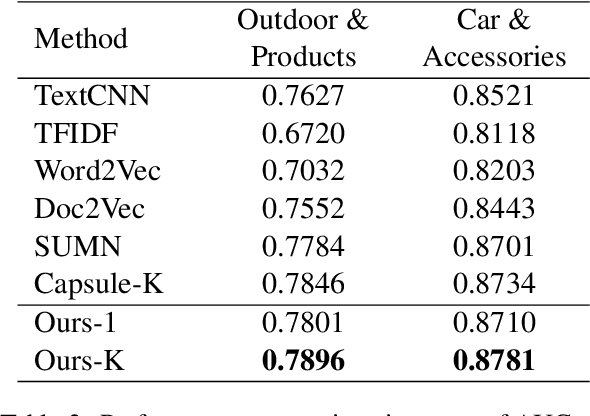
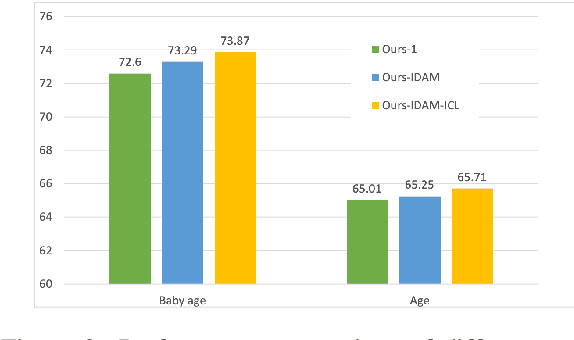
User representation is essential for providing high-quality commercial services in industry. Universal user representation has received many interests recently, with which we can be free from the cumbersome work of training a specific model for each downstream application. In this paper, we attempt to improve universal user representation from two points of views. First, a contrastive self-supervised learning paradigm is presented to guide the representation model training. It provides a unified framework that allows for long-term or short-term interest representation learning in a data-driven manner. Moreover, a novel multi-interest extraction module is presented. The module introduces an interest dictionary to capture principal interests of the given user, and then generate his/her interest-oriented representations via behavior aggregation. Experimental results demonstrate the effectiveness and applicability of the learned user representations.
Exploiting Behavioral Consistence for Universal User Representation
Dec 11, 2020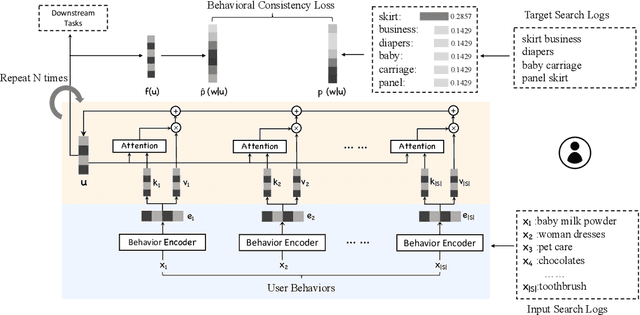
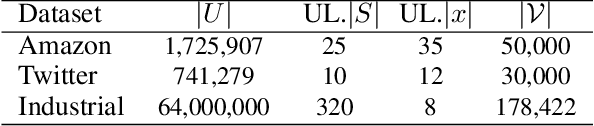
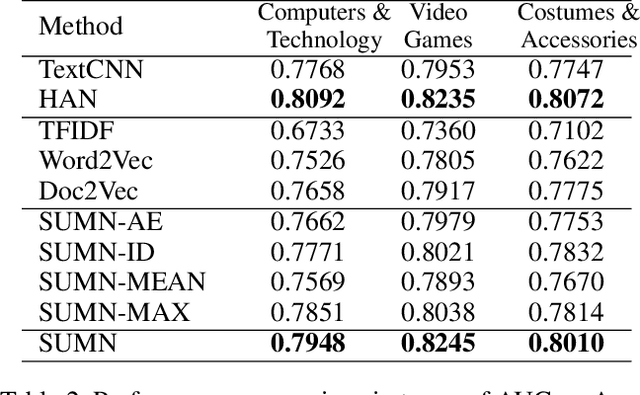
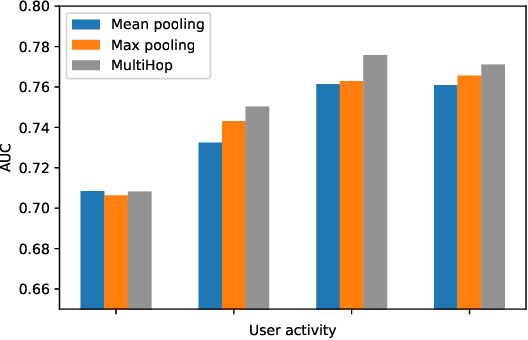
User modeling is critical for developing personalized services in industry. A common way for user modeling is to learn user representations that can be distinguished by their interests or preferences. In this work, we focus on developing universal user representation model. The obtained universal representations are expected to contain rich information, and be applicable to various downstream applications without further modifications (e.g., user preference prediction and user profiling). Accordingly, we can be free from the heavy work of training task-specific models for every downstream task as in previous works. In specific, we propose Self-supervised User Modeling Network (SUMN) to encode behavior data into the universal representation. It includes two key components. The first one is a new learning objective, which guides the model to fully identify and preserve valuable user information under a self-supervised learning framework. The other one is a multi-hop aggregation layer, which benefits the model capacity in aggregating diverse behaviors. Extensive experiments on benchmark datasets show that our approach can outperform state-of-the-art unsupervised representation methods, and even compete with supervised ones.