 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
May 28, 2026Reinforcement learning (RL) can be used to improve the policy (denoiser) of diffusion large language models (dLLMs), while being hindered by the intractability of the policy likelihood. A dominant and efficient family of methods replaces the likelihood in standard RL with its evidence lower bound (ELBO), estimated from randomly masked sequences. Despite being well aligned with pre-training, these approaches introduce bias through training--inference mismatch by using the ELBO as a likelihood surrogate, which can degrade performance. In this work, we propose Guided Denoiser Self-Distillation (GDSD) to directly distill the denoiser of dLLMs from an advantage-guided self-teacher, derived from the closed-form optimum of reverse-KL regularized RL. GDSD matches the dLLM's denoiser logits to the teacher's via a normalization-free objective, which reduces RL to likelihood-free self-distillation and thus bypasses the TIM biases. Recent ELBO-based methods emerge as instances of applying different distillation divergences, but with diagnosable pathologies that GDSD avoids. On planning, math, and coding benchmarks with LLaDA-8B and Dream-7B, GDSD consistently outperforms prior state-of-the-art ELBO-based methods with a more stable training reward dynamics, achieving test-accuracy improvements of up to $+19.6\%$. These results suggest that direct denoiser self-distillation, without relying on an ELBO likelihood surrogate, can provide a more stable and effective RL procedure for dLLMs. Code is available at https://github.com/GaryBall/GDSD.
On the Trainability of Masked Diffusion Language Models via Blockwise Locality
Apr 27, 2026Masked diffusion language models (MDMs) have recently emerged as a promising alternative to standard autoregressive large language models (AR-LLMs), yet their optimization can be substantially less stable. We study blockwise MDMs and compare them with AR-LLMs on three controlled tasks that stress different aspects of structured generation: in-context linear regression, graph path-finding, and Sudoku solving. We find that standard random-masking MDMs fail to reliably learn linear regression, exhibit high variance training dynamics on graph path-finding, while outperforming AR-LLMs on Sudoku. To mitigate these instabilities, we propose two locality aware blockwise models, namely Jigsaw and Scatter, that inject left-to-right inductive bias by enforcing autoregressive locality within blocks while preserving iterative refinement at the block level. Empirically, Jigsaw matches AR-LLM stability on linear regression and remains strong on Sudoku, while Scatter retains diffusion's planning advantage on path-finding. Our results indicate that standard random-masking MDMs, even with blockwise variants, may be a suboptimal instantiation of diffusion LMs for ordered generation, motivating models beyond random masking.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
GraphGPT: Graph Learning with Generative Pre-trained Transformers
Dec 31, 2023



We introduce \textit{GraphGPT}, a novel model for Graph learning by self-supervised Generative Pre-training Transformers. Our model transforms each graph or sampled subgraph into a sequence of tokens representing the node, edge and attributes reversibly using the Eulerian path first. Then we feed the tokens into a standard transformer decoder and pre-train it with the next-token-prediction (NTP) task. Lastly, we fine-tune the GraphGPT model with the supervised tasks. This intuitive, yet effective model achieves superior or close results to the state-of-the-art methods for the graph-, edge- and node-level tasks on the large scale molecular dataset PCQM4Mv2, the protein-protein association dataset ogbl-ppa and the ogbn-proteins dataset from the Open Graph Benchmark (OGB). Furthermore, the generative pre-training enables us to train GraphGPT up to 400M+ parameters with consistently increasing performance, which is beyond the capability of GNNs and previous graph transformers. The source code and pre-trained checkpoints will be released soon\footnote{\url{https://github.com/alibaba/graph-gpt}} to pave the way for the graph foundation model research, and also to assist the scientific discovery in pharmaceutical, chemistry, material and bio-informatics domains, etc.
UniMatch: A Unified User-Item Matching Framework for the Multi-purpose Merchant Marketing
Jul 19, 2023



When doing private domain marketing with cloud services, the merchants usually have to purchase different machine learning models for the multiple marketing purposes, leading to a very high cost. We present a unified user-item matching framework to simultaneously conduct item recommendation and user targeting with just one model. We empirically demonstrate that the above concurrent modeling is viable via modeling the user-item interaction matrix with the multinomial distribution, and propose a bidirectional bias-corrected NCE loss for the implementation. The proposed loss function guides the model to learn the user-item joint probability $p(u,i)$ instead of the conditional probability $p(i|u)$ or $p(u|i)$ through correcting both the users and items' biases caused by the in-batch negative sampling. In addition, our framework is model-agnostic enabling a flexible adaptation of different model architectures. Extensive experiments demonstrate that our framework results in significant performance gains in comparison with the state-of-the-art methods, with greatly reduced cost on computing resources and daily maintenance.
Learning to Profile: User Meta-Profile Network for Few-Shot Learning
Aug 21, 2020
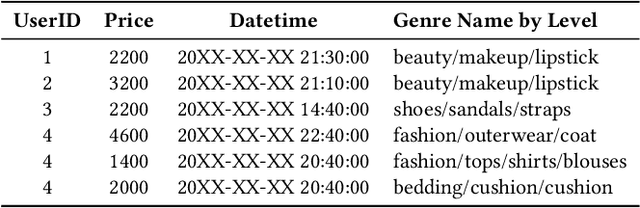
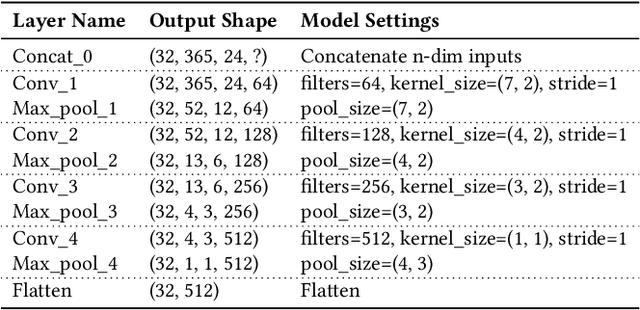
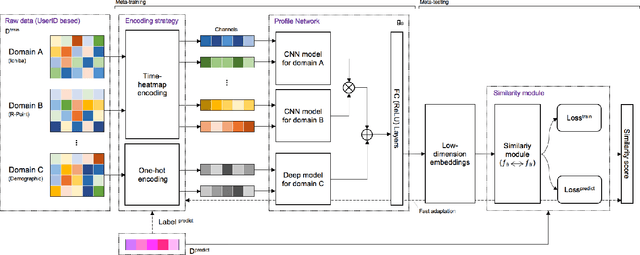
Meta-learning approaches have shown great success in vision and language domains. However, few studies discuss the practice of meta-learning for large-scale industrial applications. Although e-commerce companies have spent many efforts on learning representations to provide a better user experience, we argue that such efforts cannot be stopped at this step. In addition to learning a strong profile, the challenging question about how to effectively transfer the learned representation is raised simultaneously. This paper introduces the contributions that we made to address these challenges from three aspects. 1) Meta-learning model: In the context of representation learning with e-commerce user behavior data, we propose a meta-learning framework called the Meta-Profile Network, which extends the ideas of matching network and relation network for knowledge transfer and fast adaptation; 2) Encoding strategy: To keep high fidelity of large-scale long-term sequential behavior data, we propose a time-heatmap encoding strategy that allows the model to encode data effectively; 3) Deep network architecture: A multi-modal model combined with multi-task learning architecture is utilized to address the cross-domain knowledge learning and insufficient label problems. Moreover, we argue that an industrial model should not only have good performance in terms of accuracy, but also have better robustness and uncertainty performance under extreme conditions. We evaluate the performance of our model with extensive control experiments in various extreme scenarios, i.e. out-of-distribution detection, data insufficiency and class imbalance scenarios. The Meta-Profile Network shows significant improvement in the model performance when compared to baseline models.
Learning Classifiers on Positive and Unlabeled Data with Policy Gradient
Oct 15, 2019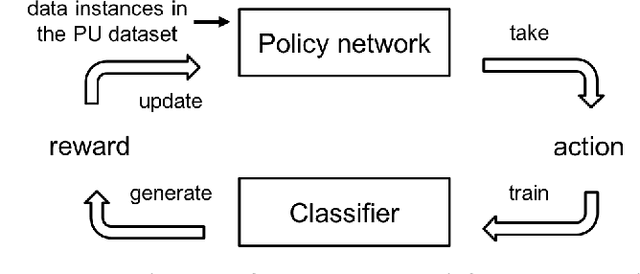
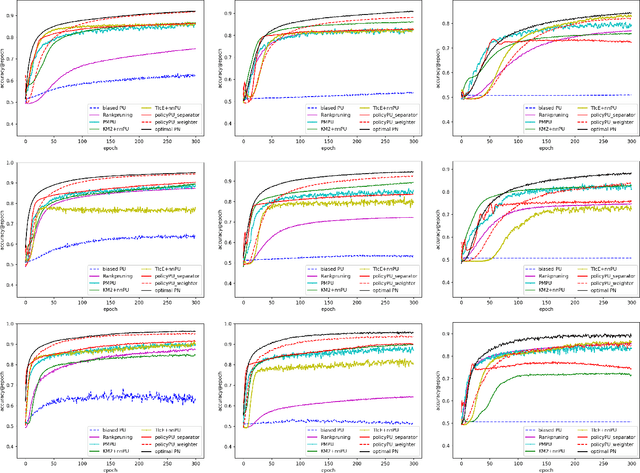
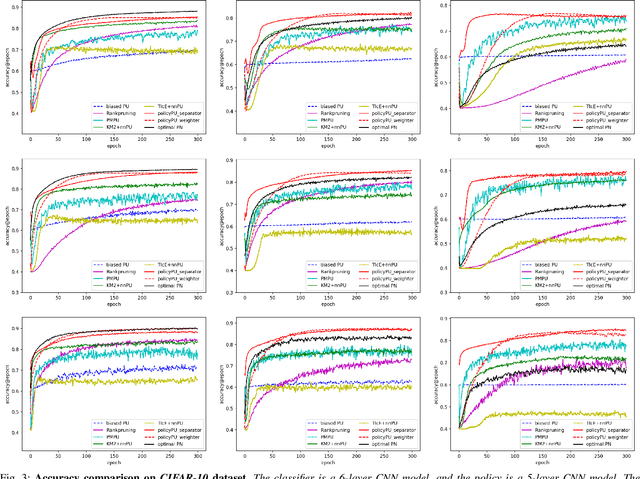
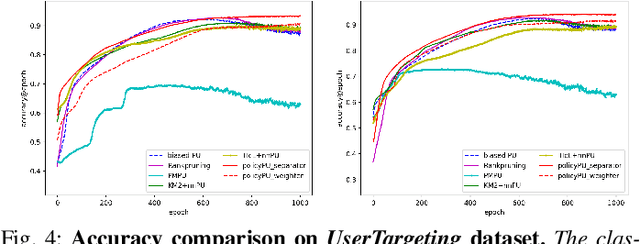
Existing algorithms aiming to learn a binary classifier from positive (P) and unlabeled (U) data generally require estimating the class prior or label noises ahead of building a classification model. However, the estimation and classifier learning are normally conducted in a pipeline instead of being jointly optimized. In this paper, we propose to alternatively train the two steps using reinforcement learning. Our proposal adopts a policy network to adaptively make assumptions on the labels of unlabeled data, while a classifier is built upon the output of the policy network and provides rewards to learn a better strategy. The dynamic and interactive training between the policy maker and the classifier can exploit the unlabeled data in a more effective manner and yield a significant improvement on the classification performance. Furthermore, we present two different approaches to represent the actions sampled from the policy. The first approach considers continuous actions as soft labels, while the other uses discrete actions as hard assignment of labels for unlabeled examples.We validate the effectiveness of the proposed method on two benchmark datasets as well as one e-commerce dataset. The result shows the proposed method is able to consistently outperform state-of-the-art methods in various settings.