 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRakuten Data Release: A Large-Scale and Long-Term Reviews Corpus for Hotel Domain
Dec 18, 2025This paper presents a large-scale corpus of Rakuten Travel Reviews. Our collection contains 7.3 million customer reviews for 16 years, ranging from 2009 to 2024. Each record in the dataset contains the review text, its response from an accommodation, an anonymized reviewer ID, review date, accommodation ID, plan ID, plan title, room type, room name, purpose, accompanying group, and user ratings from different aspect categories, as well as an overall score. We present statistical information about our corpus and provide insights into factors driving data drift between 2019 and 2024 using statistical approaches.
LLM-Augmented Graph Neural Recommenders: Integrating User Reviews
Apr 03, 2025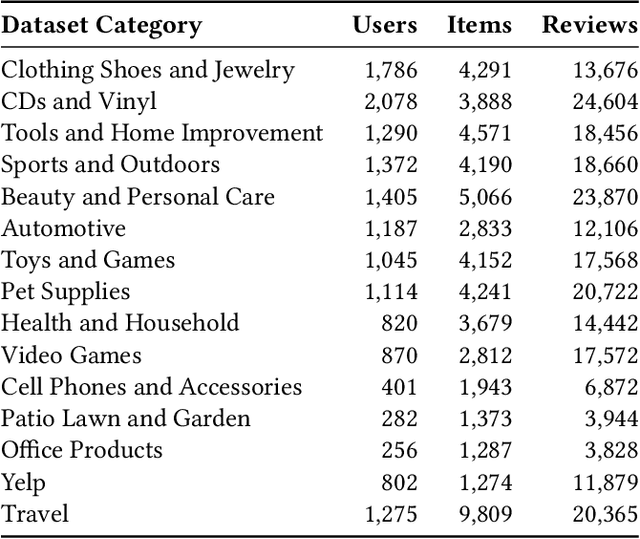
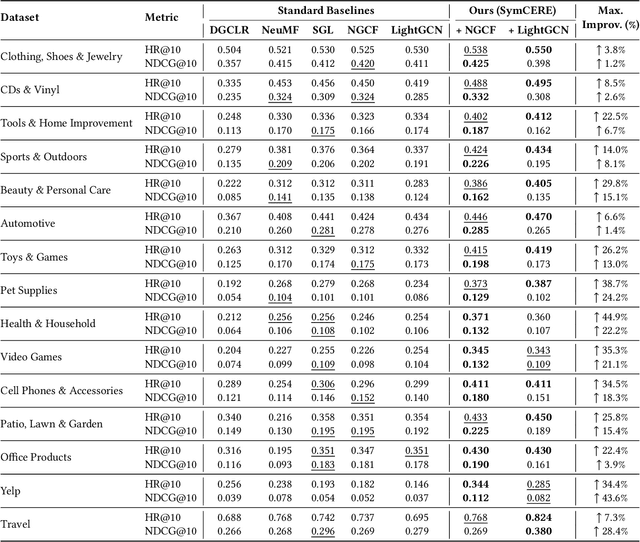
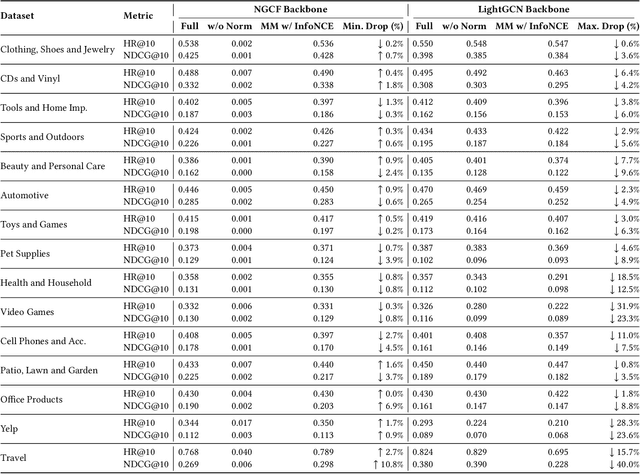

Recommender systems increasingly aim to combine signals from both user reviews and purchase (or other interaction) behaviors. While user-written comments provide explicit insights about preferences, merging these textual representations from large language models (LLMs) with graph-based embeddings of user actions remains a challenging task. In this work, we propose a framework that employs both a Graph Neural Network (GNN)-based model and an LLM to produce review-aware representations, preserving review semantics while mitigating textual noise. Our approach utilizes a hybrid objective that balances user-item interactions against text-derived features, ensuring that user's both behavioral and linguistic signals are effectively captured. We evaluate this method on multiple datasets from diverse application domains, demonstrating consistent improvements over a baseline GNN-based recommender model. Notably, our model achieves significant gains in recommendation accuracy when review data is sparse or unevenly distributed. These findings highlight the importance of integrating LLM-driven textual feedback with GNN-derived user behavioral patterns to develop robust, context-aware recommender systems.
Annealing Machine-assisted Learning of Graph Neural Network for Combinatorial Optimization
Jan 10, 2025



While Annealing Machines (AM) have shown increasing capabilities in solving complex combinatorial problems, positioning themselves as a more immediate alternative to the expected advances of future fully quantum solutions, there are still scaling limitations. In parallel, Graph Neural Networks (GNN) have been recently adapted to solve combinatorial problems, showing competitive results and potentially high scalability due to their distributed nature. We propose a merging approach that aims at retaining both the accuracy exhibited by AMs and the representational flexibility and scalability of GNNs. Our model considers a compression step, followed by a supervised interaction where partial solutions obtained from the AM are used to guide local GNNs from where node feature representations are obtained and combined to initialize an additional GNN-based solver that handles the original graph's target problem. Intuitively, the AM can solve the combinatorial problem indirectly by infusing its knowledge into the GNN. Experiments on canonical optimization problems show that the idea is feasible, effectively allowing the AM to solve size problems beyond its original limits.
Improving position bias estimation against sparse and skewed dataset with item embedding
May 10, 2023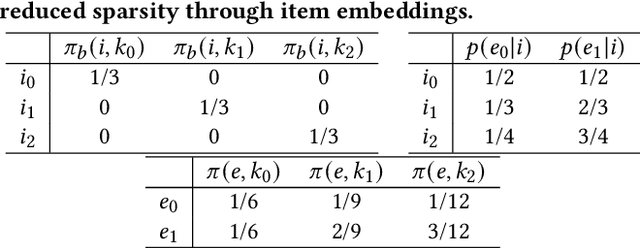
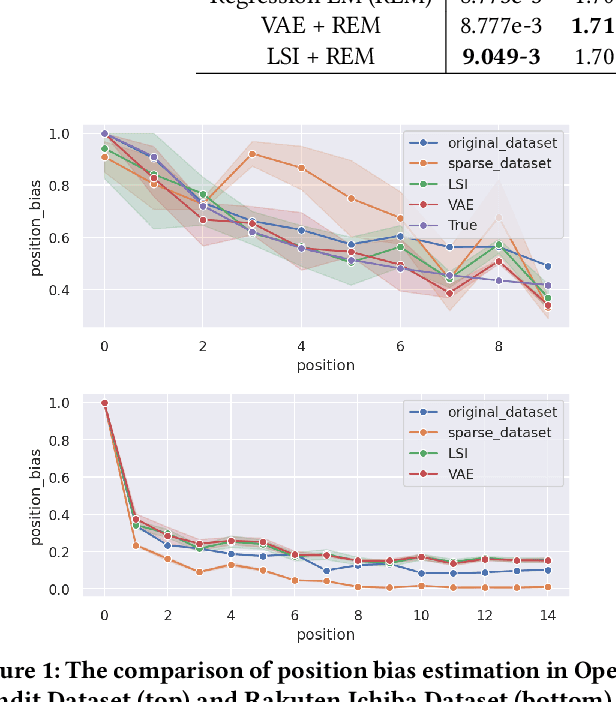
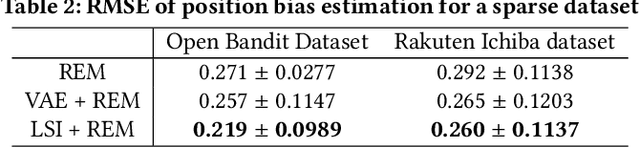
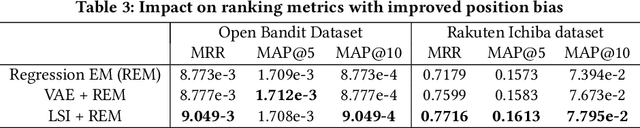
Estimating position bias is a well-known challenge in Learning to rank (L2R). Click data in e-commerce applications, such as advertisement targeting and search engines, provides implicit but abundant feedback to improve personalized rankings. However, click data inherently include various biases like position bias. Click modeling is aimed at denoising biases in click data and extracting reliable signals. Result Randomization and Regression Expectation-maximization algorithm have been proposed to solve position bias. Both methods require various pairs of observations (item, position). However, in real cases of advertising, marketers frequently display advertisements in a fixed pre-determined order, and estimation suffers from it. We propose this sparsity of (item, position) in position bias estimation as a novel problem, and we propose a variant of the Regression EM algorithm which utilizes item embeddings to alleviate the issue of the sparsity. With a synthetic dataset, we first evaluate how the position bias estimation suffers from the sparsity and skewness of the logging dataset. Next, with a real-world dataset, we empirically show that item embedding with Latent Semantic Indexing (LSI) and Variational autoencoder (VAE) improves the estimation of position bias. Our result shows that the Regression EM algorithm with VAE improves RMSE relatively by 10.3% and EM with LSI improves RMSE relatively by 33.4%.
Exploring 360-Degree View of Customers for Lookalike Modeling
Apr 17, 2023Lookalike models are based on the assumption that user similarity plays an important role towards product selling and enhancing the existing advertising campaigns from a very large user base. Challenges associated to these models reside on the heterogeneity of the user base and its sparsity. In this work, we propose a novel framework that unifies the customers different behaviors or features such as demographics, buying behaviors on different platforms, customer loyalty behaviors and build a lookalike model to improve customer targeting for Rakuten Group, Inc. Extensive experiments on real e-commerce and travel datasets demonstrate the effectiveness of our proposed lookalike model for user targeting task.
Dynamic collaborative filtering Thompson Sampling for cross-domain advertisements recommendation
Aug 25, 2022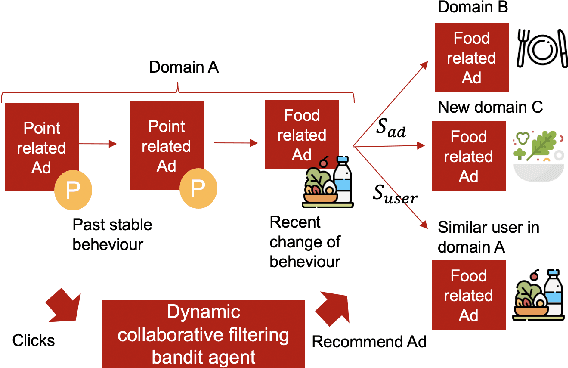
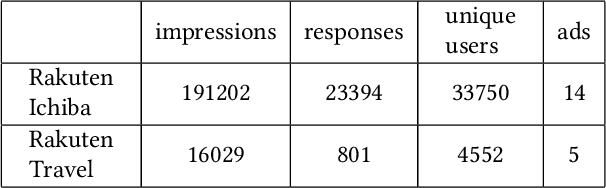


Recently online advertisers utilize Recommender systems (RSs) for display advertising to improve users' engagement. The contextual bandit model is a widely used RS to exploit and explore users' engagement and maximize the long-term rewards such as clicks or conversions. However, the current models aim to optimize a set of ads only in a specific domain and do not share information with other models in multiple domains. In this paper, we propose dynamic collaborative filtering Thompson Sampling (DCTS), the novel yet simple model to transfer knowledge among multiple bandit models. DCTS exploits similarities between users and between ads to estimate a prior distribution of Thompson sampling. Such similarities are obtained based on contextual features of users and ads. Similarities enable models in a domain that didn't have much data to converge more quickly by transferring knowledge. Moreover, DCTS incorporates temporal dynamics of users to track the user's recent change of preference. We first show transferring knowledge and incorporating temporal dynamics improve the performance of the baseline models on a synthetic dataset. Then we conduct an empirical analysis on a real-world dataset and the result showed that DCTS improves click-through rate by 9.7% than the state-of-the-art models. We also analyze hyper-parameters that adjust temporal dynamics and similarities and show the best parameter which maximizes CTR.
KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation
May 23, 2022
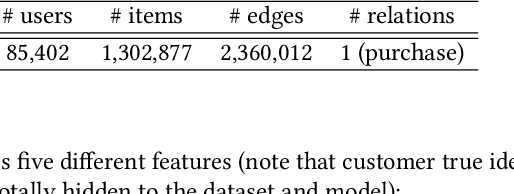
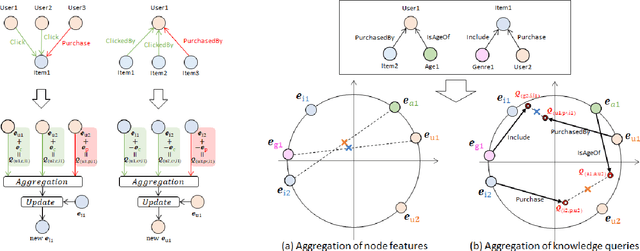
Leveraging graphs on recommender systems has gained popularity with the development of graph representation learning (GRL). In particular, knowledge graph embedding (KGE) and graph neural networks (GNNs) are representative GRL approaches, which have achieved the state-of-the-art performance on several recommendation tasks. Furthermore, combination of KGE and GNNs (KG-GNNs) has been explored and found effective in many academic literatures. One of the main characteristics of GNNs is their ability to retain structural properties among neighbors in the resulting dense representation, which is usually coined as smoothing. The smoothing is specially desired in the presence of homophilic graphs, such as the ones we find on recommender systems. In this paper, we propose a new model for recommender systems named Knowledge Query-based Graph Convolution (KQGC). In contrast to exisiting KG-GNNs, KQGC focuses on the smoothing, and leverages a simple linear graph convolution for smoothing KGE. A pre-trained KGE is fed into KQGC, and it is smoothed by aggregating neighbor knowledge queries, which allow entity-embeddings to be aligned on appropriate vector points for smoothing KGE effectively. We apply the proposed KQGC to a recommendation task that aims prospective users for specific products. Extensive experiments on a real E-commerce dataset demonstrate the effectiveness of KQGC.
Learning Classifiers on Positive and Unlabeled Data with Policy Gradient
Oct 15, 2019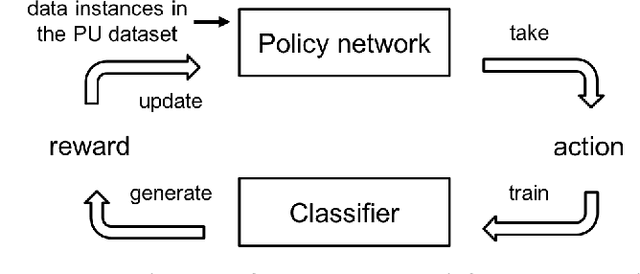
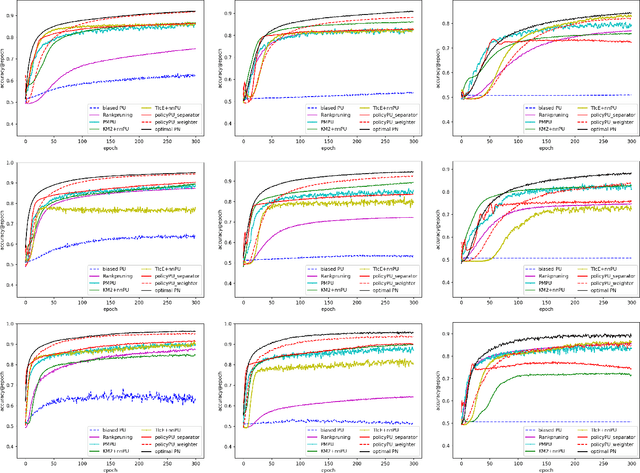
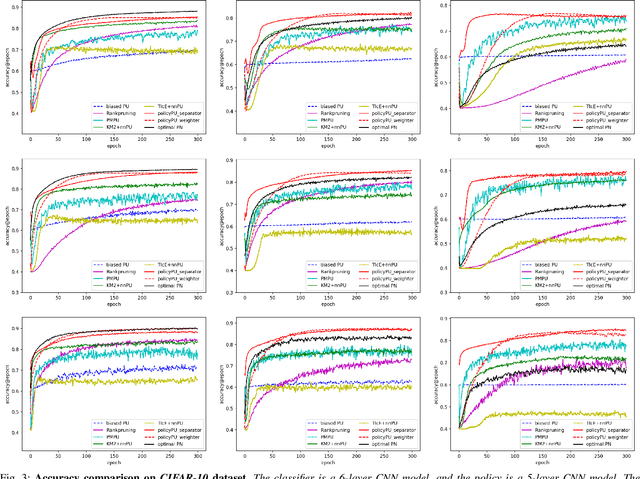
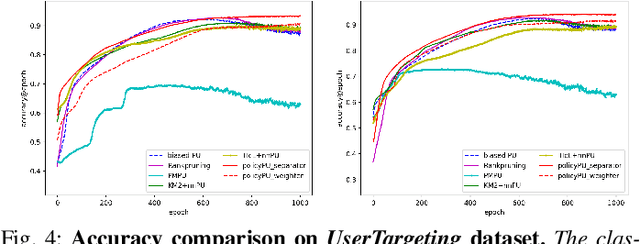
Existing algorithms aiming to learn a binary classifier from positive (P) and unlabeled (U) data generally require estimating the class prior or label noises ahead of building a classification model. However, the estimation and classifier learning are normally conducted in a pipeline instead of being jointly optimized. In this paper, we propose to alternatively train the two steps using reinforcement learning. Our proposal adopts a policy network to adaptively make assumptions on the labels of unlabeled data, while a classifier is built upon the output of the policy network and provides rewards to learn a better strategy. The dynamic and interactive training between the policy maker and the classifier can exploit the unlabeled data in a more effective manner and yield a significant improvement on the classification performance. Furthermore, we present two different approaches to represent the actions sampled from the policy. The first approach considers continuous actions as soft labels, while the other uses discrete actions as hard assignment of labels for unlabeled examples.We validate the effectiveness of the proposed method on two benchmark datasets as well as one e-commerce dataset. The result shows the proposed method is able to consistently outperform state-of-the-art methods in various settings.
Deep Heterogeneous Autoencoders for Collaborative Filtering
Dec 17, 2018
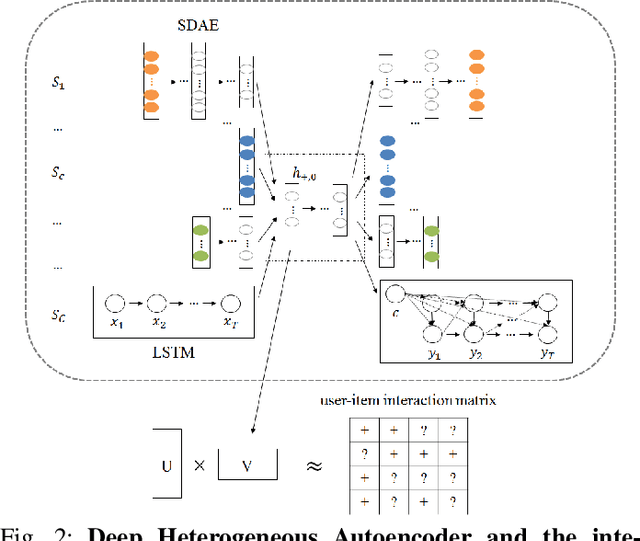
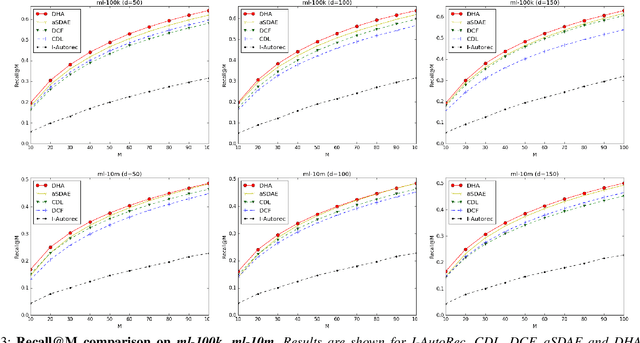
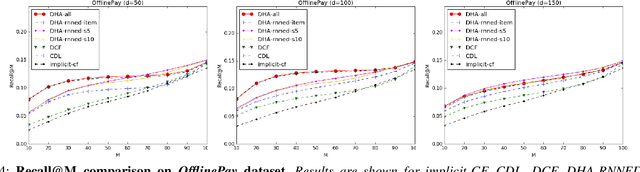
This paper leverages heterogeneous auxiliary information to address the data sparsity problem of recommender systems. We propose a model that learns a shared feature space from heterogeneous data, such as item descriptions, product tags and online purchase history, to obtain better predictions. Our model consists of autoencoders, not only for numerical and categorical data, but also for sequential data, which enables capturing user tastes, item characteristics and the recent dynamics of user preference. We learn the autoencoder architecture for each data source independently in order to better model their statistical properties. Our evaluation on two MovieLens datasets and an e-commerce dataset shows that mean average precision and recall improve over state-of-the-art methods.