 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Graph Neural Recommenders: Integrating User Reviews
Apr 03, 2025
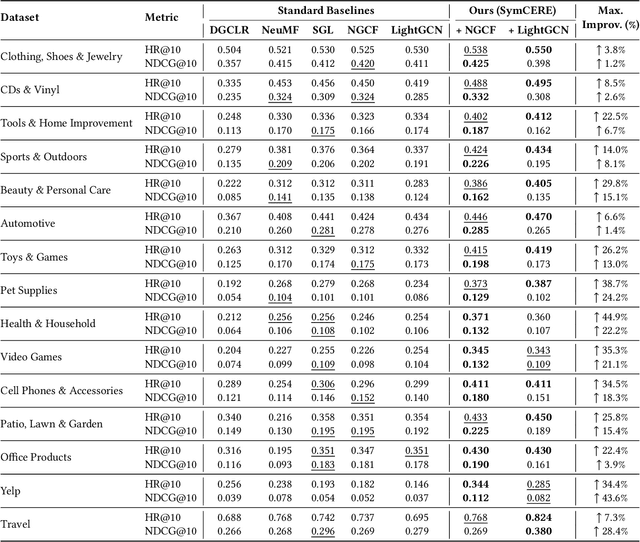
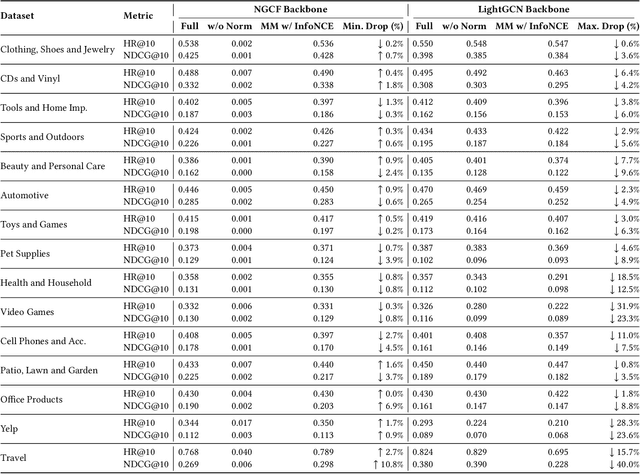

Recommender systems increasingly aim to combine signals from both user reviews and purchase (or other interaction) behaviors. While user-written comments provide explicit insights about preferences, merging these textual representations from large language models (LLMs) with graph-based embeddings of user actions remains a challenging task. In this work, we propose a framework that employs both a Graph Neural Network (GNN)-based model and an LLM to produce review-aware representations, preserving review semantics while mitigating textual noise. Our approach utilizes a hybrid objective that balances user-item interactions against text-derived features, ensuring that user's both behavioral and linguistic signals are effectively captured. We evaluate this method on multiple datasets from diverse application domains, demonstrating consistent improvements over a baseline GNN-based recommender model. Notably, our model achieves significant gains in recommendation accuracy when review data is sparse or unevenly distributed. These findings highlight the importance of integrating LLM-driven textual feedback with GNN-derived user behavioral patterns to develop robust, context-aware recommender systems.
Embedding with Large Language Models for Classification of HIPAA Safeguard Compliance Rules
Oct 28, 2024
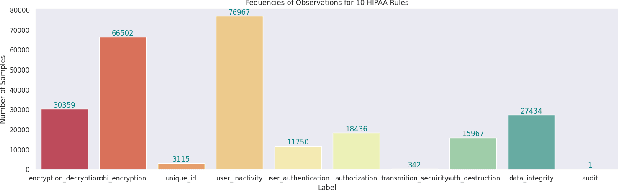
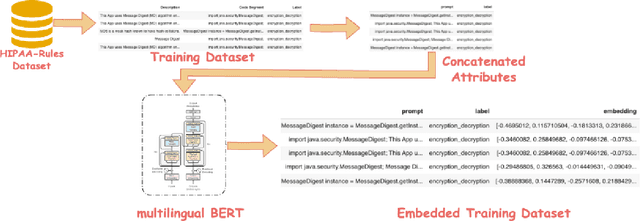
Although software developers of mHealth apps are responsible for protecting patient data and adhering to strict privacy and security requirements, many of them lack awareness of HIPAA regulations and struggle to distinguish between HIPAA rules categories. Therefore, providing guidance of HIPAA rules patterns classification is essential for developing secured applications for Google Play Store. In this work, we identified the limitations of traditional Word2Vec embeddings in processing code patterns. To address this, we adopt multilingual BERT (Bidirectional Encoder Representations from Transformers) which offers contextualized embeddings to the attributes of dataset to overcome the issues. Therefore, we applied this BERT to our dataset for embedding code patterns and then uses these embedded code to various machine learning approaches. Our results demonstrate that the models significantly enhances classification performance, with Logistic Regression achieving a remarkable accuracy of 99.95\%. Additionally, we obtained high accuracy from Support Vector Machine (99.79\%), Random Forest (99.73\%), and Naive Bayes (95.93\%), outperforming existing approaches. This work underscores the effectiveness and showcases its potential for secure application development.
Exploring 360-Degree View of Customers for Lookalike Modeling
Apr 17, 2023Lookalike models are based on the assumption that user similarity plays an important role towards product selling and enhancing the existing advertising campaigns from a very large user base. Challenges associated to these models reside on the heterogeneity of the user base and its sparsity. In this work, we propose a novel framework that unifies the customers different behaviors or features such as demographics, buying behaviors on different platforms, customer loyalty behaviors and build a lookalike model to improve customer targeting for Rakuten Group, Inc. Extensive experiments on real e-commerce and travel datasets demonstrate the effectiveness of our proposed lookalike model for user targeting task.
KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation
May 23, 2022
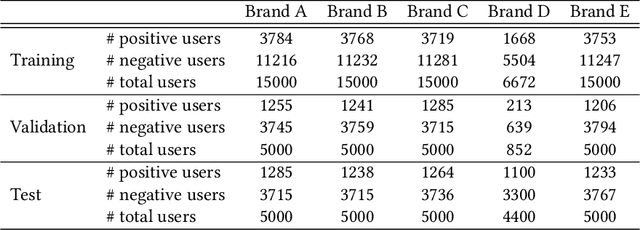
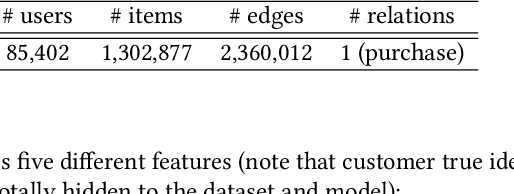
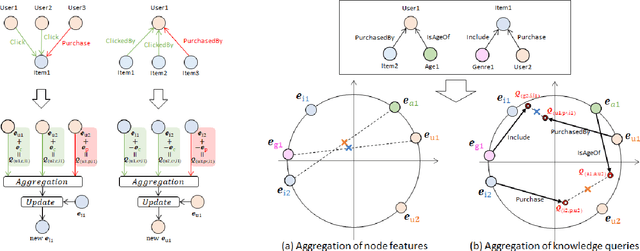
Leveraging graphs on recommender systems has gained popularity with the development of graph representation learning (GRL). In particular, knowledge graph embedding (KGE) and graph neural networks (GNNs) are representative GRL approaches, which have achieved the state-of-the-art performance on several recommendation tasks. Furthermore, combination of KGE and GNNs (KG-GNNs) has been explored and found effective in many academic literatures. One of the main characteristics of GNNs is their ability to retain structural properties among neighbors in the resulting dense representation, which is usually coined as smoothing. The smoothing is specially desired in the presence of homophilic graphs, such as the ones we find on recommender systems. In this paper, we propose a new model for recommender systems named Knowledge Query-based Graph Convolution (KQGC). In contrast to exisiting KG-GNNs, KQGC focuses on the smoothing, and leverages a simple linear graph convolution for smoothing KGE. A pre-trained KGE is fed into KQGC, and it is smoothed by aggregating neighbor knowledge queries, which allow entity-embeddings to be aligned on appropriate vector points for smoothing KGE effectively. We apply the proposed KQGC to a recommendation task that aims prospective users for specific products. Extensive experiments on a real E-commerce dataset demonstrate the effectiveness of KQGC.