 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring 360-Degree View of Customers for Lookalike Modeling
Apr 17, 2023Lookalike models are based on the assumption that user similarity plays an important role towards product selling and enhancing the existing advertising campaigns from a very large user base. Challenges associated to these models reside on the heterogeneity of the user base and its sparsity. In this work, we propose a novel framework that unifies the customers different behaviors or features such as demographics, buying behaviors on different platforms, customer loyalty behaviors and build a lookalike model to improve customer targeting for Rakuten Group, Inc. Extensive experiments on real e-commerce and travel datasets demonstrate the effectiveness of our proposed lookalike model for user targeting task.
KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation
May 23, 2022
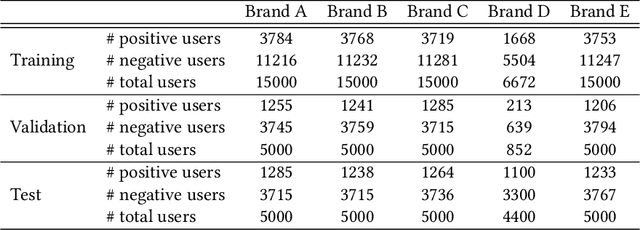
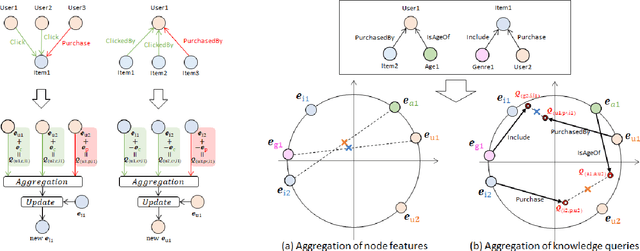
Leveraging graphs on recommender systems has gained popularity with the development of graph representation learning (GRL). In particular, knowledge graph embedding (KGE) and graph neural networks (GNNs) are representative GRL approaches, which have achieved the state-of-the-art performance on several recommendation tasks. Furthermore, combination of KGE and GNNs (KG-GNNs) has been explored and found effective in many academic literatures. One of the main characteristics of GNNs is their ability to retain structural properties among neighbors in the resulting dense representation, which is usually coined as smoothing. The smoothing is specially desired in the presence of homophilic graphs, such as the ones we find on recommender systems. In this paper, we propose a new model for recommender systems named Knowledge Query-based Graph Convolution (KQGC). In contrast to exisiting KG-GNNs, KQGC focuses on the smoothing, and leverages a simple linear graph convolution for smoothing KGE. A pre-trained KGE is fed into KQGC, and it is smoothed by aggregating neighbor knowledge queries, which allow entity-embeddings to be aligned on appropriate vector points for smoothing KGE effectively. We apply the proposed KQGC to a recommendation task that aims prospective users for specific products. Extensive experiments on a real E-commerce dataset demonstrate the effectiveness of KQGC.
Combination of Unified Embedding Model and Observed Features for Knowledge Graph Completion
Sep 10, 2019
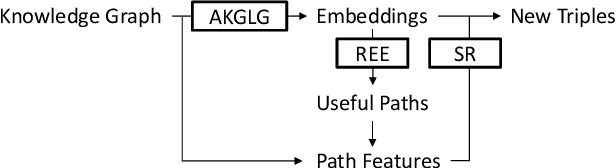
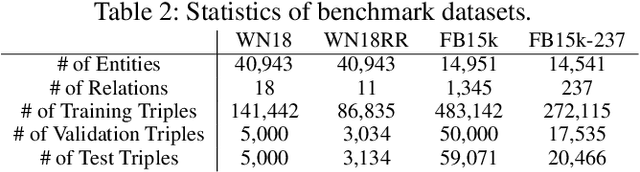
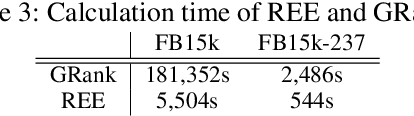
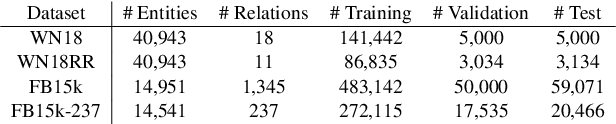
Knowledge graphs are useful for many artificial intelligence tasks but often have missing data. Hence, a method for completing knowledge graphs is required. Existing approaches include embedding models, the Path Ranking Algorithm, and rule evaluation models. However, these approaches have limitations. For example, all the information is mixed and difficult to interpret in embedding models, and traditional rule evaluation models are basically slow. In this paper, we provide an integrated view of various approaches and combine them to compensate for their limitations. We first unify state-of-the-art embedding models, such as ComplEx and TorusE, reinterpreting them as a variant of translation-based models. Then, we show that these models utilize paths for link prediction and propose a method for evaluating rules based on this idea. Finally, we combine an embedding model and observed feature models to predict missing triples. This is possible because all of these models utilize paths. We also conduct experiments, including link prediction tasks, with standard datasets to evaluate our method and framework. The experiments show that our method can evaluate rules faster than traditional methods and that our framework outperforms state-of-the-art models in terms of link prediction.
Graph Pattern Entity Ranking Model for Knowledge Graph Completion
Apr 05, 2019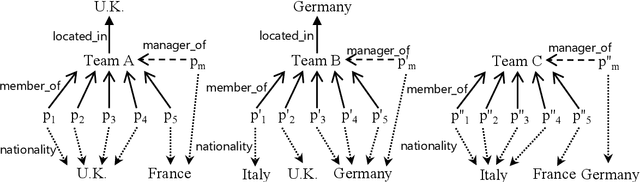
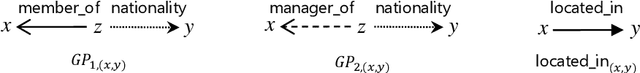
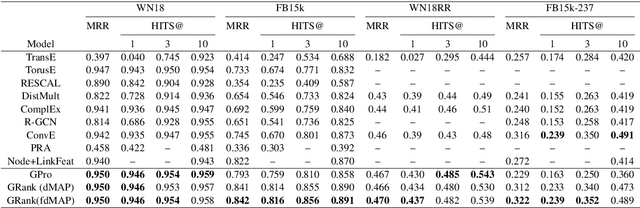
Knowledge graphs have evolved rapidly in recent years and their usefulness has been demonstrated in many artificial intelligence tasks. However, knowledge graphs often have lots of missing facts. To solve this problem, many knowledge graph embedding models have been developed to populate knowledge graphs and these have shown outstanding performance. However, knowledge graph embedding models are so-called black boxes, and the user does not know how the information in a knowledge graph is processed and the models can be difficult to interpret. In this paper, we utilize graph patterns in a knowledge graph to overcome such problems. Our proposed model, the {\it graph pattern entity ranking model} (GRank), constructs an entity ranking system for each graph pattern and evaluates them using a ranking measure. By doing so, we can find graph patterns which are useful for predicting facts. Then, we perform link prediction tasks on standard datasets to evaluate our GRank method. We show that our approach outperforms other state-of-the-art approaches such as ComplEx and TorusE for standard metrics such as HITS@{\it n} and MRR. Moreover, our model is easily interpretable because the output facts are described by graph patterns.
TorusE: Knowledge Graph Embedding on a Lie Group
Nov 15, 2017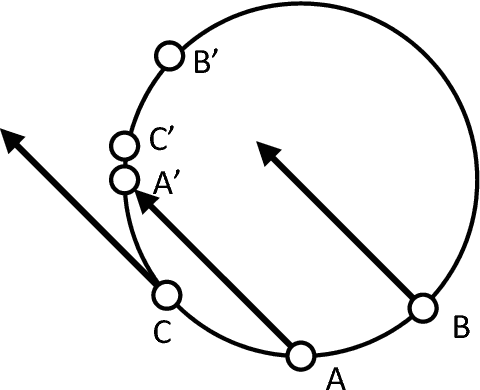
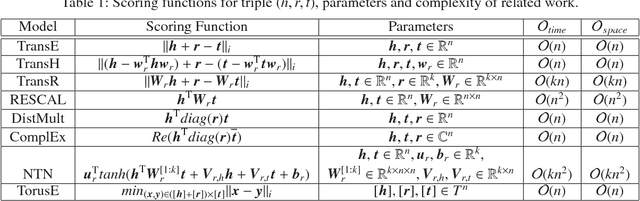
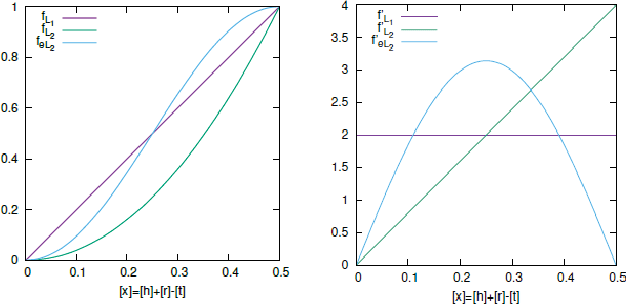
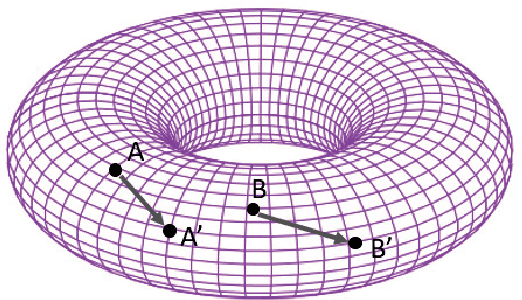
Knowledge graphs are useful for many artificial intelligence (AI) tasks. However, knowledge graphs often have missing facts. To populate the graphs, knowledge graph embedding models have been developed. Knowledge graph embedding models map entities and relations in a knowledge graph to a vector space and predict unknown triples by scoring candidate triples. TransE is the first translation-based method and it is well known because of its simplicity and efficiency for knowledge graph completion. It employs the principle that the differences between entity embeddings represent their relations. The principle seems very simple, but it can effectively capture the rules of a knowledge graph. However, TransE has a problem with its regularization. TransE forces entity embeddings to be on a sphere in the embedding vector space. This regularization warps the embeddings and makes it difficult for them to fulfill the abovementioned principle. The regularization also affects adversely the accuracies of the link predictions. On the other hand, regularization is important because entity embeddings diverge by negative sampling without it. This paper proposes a novel embedding model, TorusE, to solve the regularization problem. The principle of TransE can be defined on any Lie group. A torus, which is one of the compact Lie groups, can be chosen for the embedding space to avoid regularization. To the best of our knowledge, TorusE is the first model that embeds objects on other than a real or complex vector space, and this paper is the first to formally discuss the problem of regularization of TransE. Our approach outperforms other state-of-the-art approaches such as TransE, DistMult and ComplEx on a standard link prediction task. We show that TorusE is scalable to large-size knowledge graphs and is faster than the original TransE.