 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealing Machine-assisted Learning of Graph Neural Network for Combinatorial Optimization
Jan 10, 2025



While Annealing Machines (AM) have shown increasing capabilities in solving complex combinatorial problems, positioning themselves as a more immediate alternative to the expected advances of future fully quantum solutions, there are still scaling limitations. In parallel, Graph Neural Networks (GNN) have been recently adapted to solve combinatorial problems, showing competitive results and potentially high scalability due to their distributed nature. We propose a merging approach that aims at retaining both the accuracy exhibited by AMs and the representational flexibility and scalability of GNNs. Our model considers a compression step, followed by a supervised interaction where partial solutions obtained from the AM are used to guide local GNNs from where node feature representations are obtained and combined to initialize an additional GNN-based solver that handles the original graph's target problem. Intuitively, the AM can solve the combinatorial problem indirectly by infusing its knowledge into the GNN. Experiments on canonical optimization problems show that the idea is feasible, effectively allowing the AM to solve size problems beyond its original limits.
Perceptual Structure in the Absence of Grounding for LLMs: The Impact of Abstractedness and Subjectivity in Color Language
Nov 22, 2023



The need for grounding in language understanding is an active research topic. Previous work has suggested that color perception and color language appear as a suitable test bed to empirically study the problem, given its cognitive significance and showing that there is considerable alignment between a defined color space and the feature space defined by a language model. To further study this issue, we collect a large scale source of colors and their descriptions, containing almost a 1 million examples , and perform an empirical analysis to compare two kinds of alignments: (i) inter-space, by learning a mapping between embedding space and color space, and (ii) intra-space, by means of prompting comparatives between color descriptions. Our results show that while color space alignment holds for monolexemic, highly pragmatic color descriptions, this alignment drops considerably in the presence of examples that exhibit elements of real linguistic usage such as subjectivity and abstractedness, suggesting that grounding may be required in such cases.
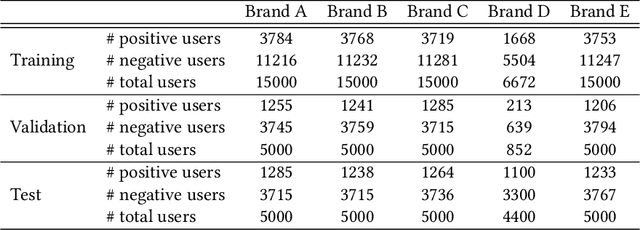
Exploring 360-Degree View of Customers for Lookalike Modeling
Apr 17, 2023Lookalike models are based on the assumption that user similarity plays an important role towards product selling and enhancing the existing advertising campaigns from a very large user base. Challenges associated to these models reside on the heterogeneity of the user base and its sparsity. In this work, we propose a novel framework that unifies the customers different behaviors or features such as demographics, buying behaviors on different platforms, customer loyalty behaviors and build a lookalike model to improve customer targeting for Rakuten Group, Inc. Extensive experiments on real e-commerce and travel datasets demonstrate the effectiveness of our proposed lookalike model for user targeting task.
KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation
May 23, 2022
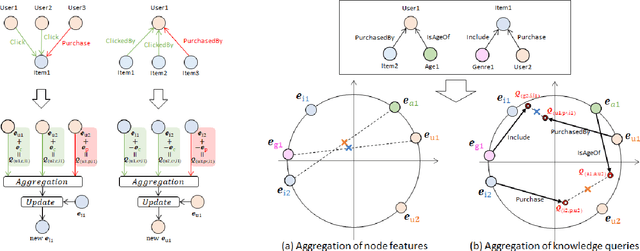
Leveraging graphs on recommender systems has gained popularity with the development of graph representation learning (GRL). In particular, knowledge graph embedding (KGE) and graph neural networks (GNNs) are representative GRL approaches, which have achieved the state-of-the-art performance on several recommendation tasks. Furthermore, combination of KGE and GNNs (KG-GNNs) has been explored and found effective in many academic literatures. One of the main characteristics of GNNs is their ability to retain structural properties among neighbors in the resulting dense representation, which is usually coined as smoothing. The smoothing is specially desired in the presence of homophilic graphs, such as the ones we find on recommender systems. In this paper, we propose a new model for recommender systems named Knowledge Query-based Graph Convolution (KQGC). In contrast to exisiting KG-GNNs, KQGC focuses on the smoothing, and leverages a simple linear graph convolution for smoothing KGE. A pre-trained KGE is fed into KQGC, and it is smoothed by aggregating neighbor knowledge queries, which allow entity-embeddings to be aligned on appropriate vector points for smoothing KGE effectively. We apply the proposed KQGC to a recommendation task that aims prospective users for specific products. Extensive experiments on a real E-commerce dataset demonstrate the effectiveness of KQGC.
Towards Federated Graph Learning for Collaborative Financial Crimes Detection
Oct 02, 2019
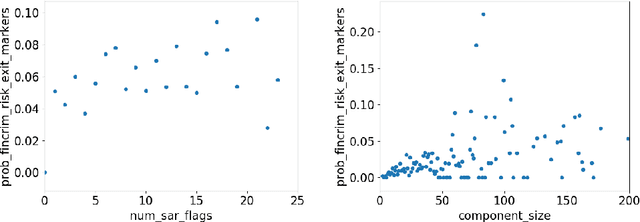
Financial crime is a large and growing problem, in some way touching almost every financial institution. Financial institutions are the front line in the war against financial crime and accordingly, must devote substantial human and technology resources to this effort. Current processes to detect financial misconduct have limitations in their ability to effectively differentiate between malicious behavior and ordinary financial activity. These limitations tend to result in gross over-reporting of suspicious activity that necessitate time-intensive and costly manual review. Advances in technology used in this domain, including machine learning based approaches, can improve upon the effectiveness of financial institutions' existing processes, however, a key challenge that most financial institutions continue to face is that they address financial crimes in isolation without any insight from other firms. Where financial institutions address financial crimes through the lens of their own firm, perpetrators may devise sophisticated strategies that may span across institutions and geographies. Financial institutions continue to work relentlessly to advance their capabilities, forming partnerships across institutions to share insights, patterns and capabilities. These public-private partnerships are subject to stringent regulatory and data privacy requirements, thereby making it difficult to rely on traditional technology solutions. In this paper, we propose a methodology to share key information across institutions by using a federated graph learning platform that enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. We demonstrated that our federated model outperforms local model by 20% with the UK FCA TechSprint data set. This new platform opens up a door to efficiently detecting global money laundering activity.
An Edit-centric Approach for Wikipedia Article Quality Assessment
Sep 19, 2019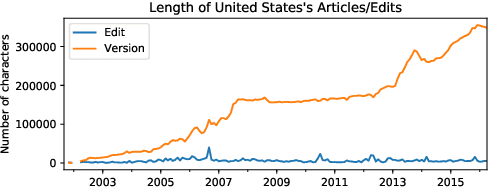
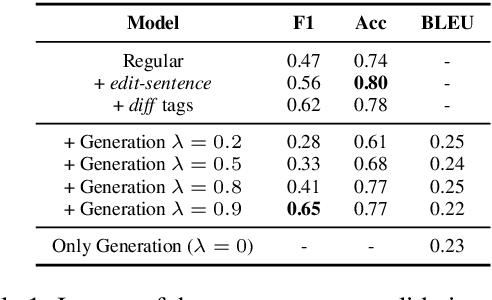
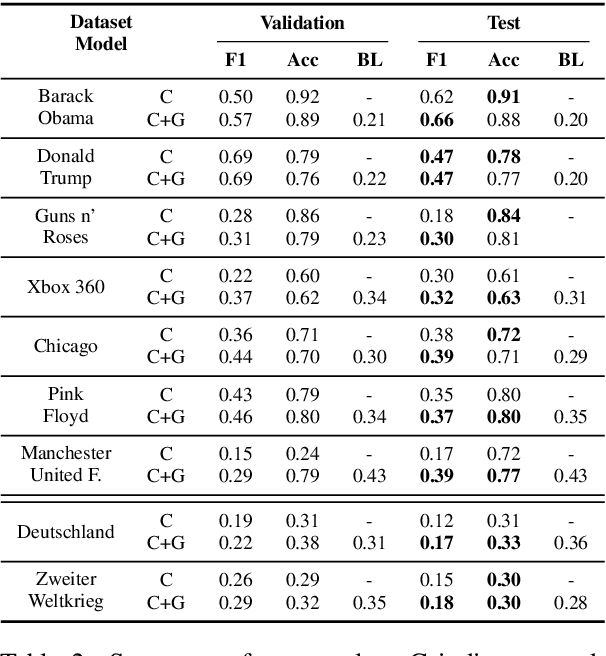
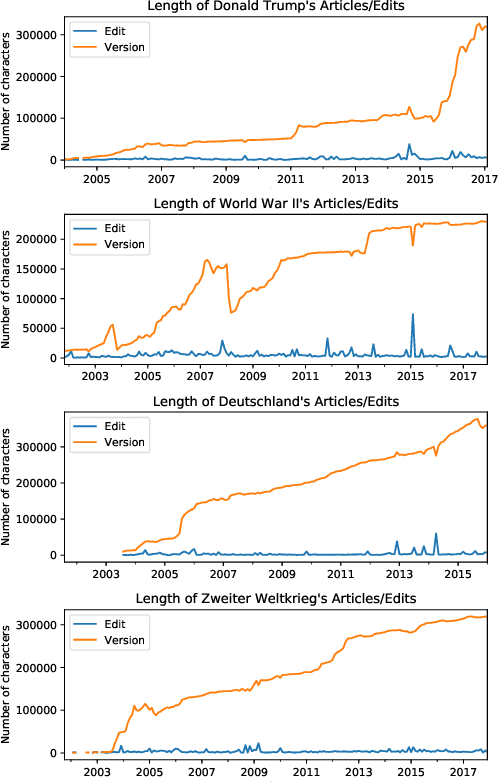
We propose an edit-centric approach to assess Wikipedia article quality as a complementary alternative to current full document-based techniques. Our model consists of a main classifier equipped with an auxiliary generative module which, for a given edit, jointly provides an estimation of its quality and generates a description in natural language. We performed an empirical study to assess the feasibility of the proposed model and its cost-effectiveness in terms of data and quality requirements.
Refining Raw Sentence Representations for Textual Entailment Recognition via Attention
Jul 12, 2017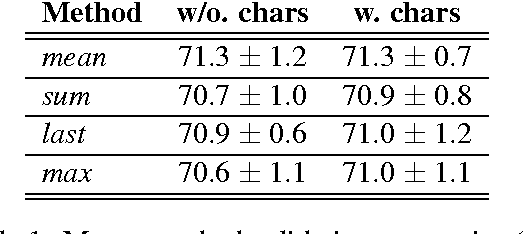


In this paper we present the model used by the team Rivercorners for the 2017 RepEval shared task. First, our model separately encodes a pair of sentences into variable-length representations by using a bidirectional LSTM. Later, it creates fixed-length raw representations by means of simple aggregation functions, which are then refined using an attention mechanism. Finally it combines the refined representations of both sentences into a single vector to be used for classification. With this model we obtained test accuracies of 72.057% and 72.055% in the matched and mismatched evaluation tracks respectively, outperforming the LSTM baseline, and obtaining performances similar to a model that relies on shared information between sentences (ESIM). When using an ensemble both accuracies increased to 72.247% and 72.827% respectively.