 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal Approach to Fine-grained Opinion Mining on Video Reviews
May 28, 2020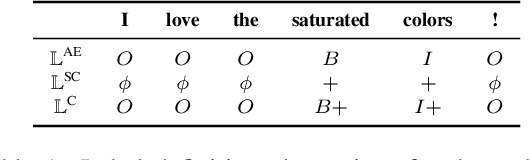
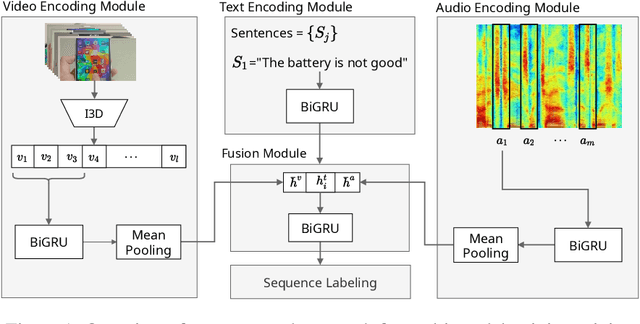
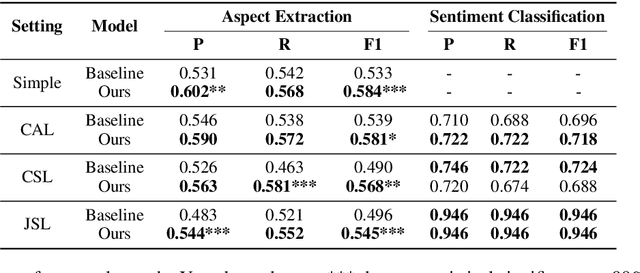
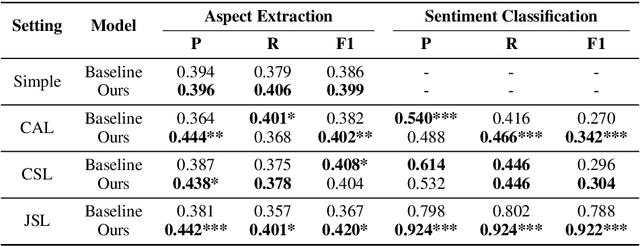
Despite the recent advances in opinion mining for written reviews, few works have tackled the problem on other sources of reviews. In light of this issue, we propose a multi-modal approach for mining fine-grained opinions from video reviews that is able to determine the aspects of the item under review that are being discussed and the sentiment orientation towards them. Our approach works at the sentence level without the need for time annotations and uses features derived from the audio, video and language transcriptions of its contents. We evaluate our approach on two datasets and show that leveraging the video and audio modalities consistently provides increased performance over text-only baselines, providing evidence these extra modalities are key in better understanding video reviews.
Gating Mechanisms for Combining Character and Word-level Word Representations: An Empirical Study
Apr 11, 2019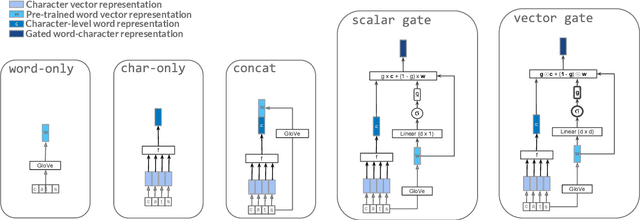
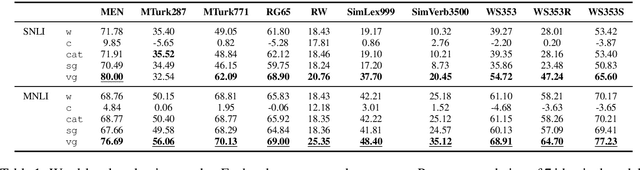
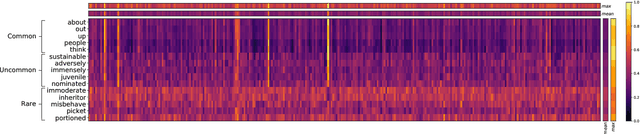
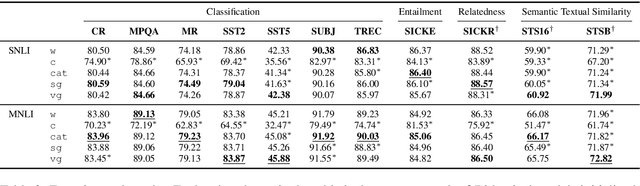
In this paper we study how different ways of combining character and word-level representations affect the quality of both final word and sentence representations. We provide strong empirical evidence that modeling characters improves the learned representations at the word and sentence levels, and that doing so is particularly useful when representing less frequent words. We further show that a feature-wise sigmoid gating mechanism is a robust method for creating representations that encode semantic similarity, as it performed reasonably well in several word similarity datasets. Finally, our findings suggest that properly capturing semantic similarity at the word level does not consistently yield improved performance in downstream sentence-level tasks. Our code is available at https://github.com/jabalazs/gating
Deep contextualized word representations for detecting sarcasm and irony
Sep 26, 2018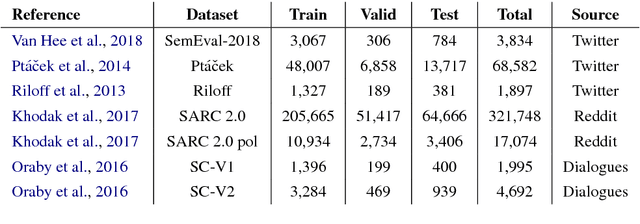
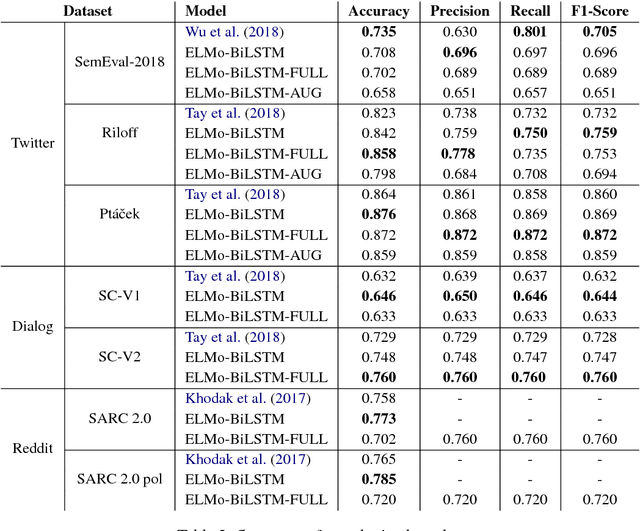
Predicting context-dependent and non-literal utterances like sarcastic and ironic expressions still remains a challenging task in NLP, as it goes beyond linguistic patterns, encompassing common sense and shared knowledge as crucial components. To capture complex morpho-syntactic features that can usually serve as indicators for irony or sarcasm across dynamic contexts, we propose a model that uses character-level vector representations of words, based on ELMo. We test our model on 7 different datasets derived from 3 different data sources, providing state-of-the-art performance in 6 of them, and otherwise offering competitive results.
IIIDYT at IEST 2018: Implicit Emotion Classification With Deep Contextualized Word Representations
Sep 01, 2018
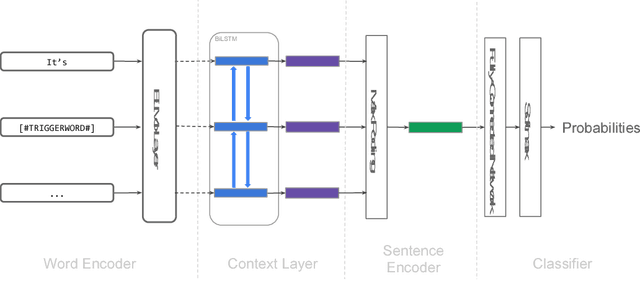

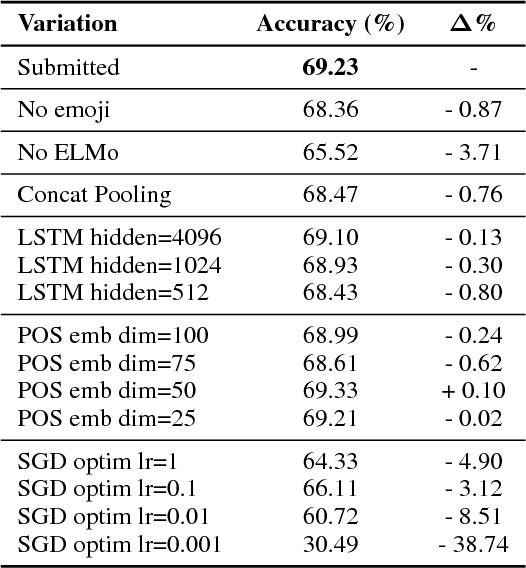
In this paper we describe our system designed for the WASSA 2018 Implicit Emotion Shared Task (IEST), which obtained 2$^{\text{nd}}$ place out of 26 teams with a test macro F1 score of $0.710$. The system is composed of a single pre-trained ELMo layer for encoding words, a Bidirectional Long-Short Memory Network BiLSTM for enriching word representations with context, a max-pooling operation for creating sentence representations from said word vectors, and a Dense Layer for projecting the sentence representations into label space. Our official submission was obtained by ensembling 6 of these models initialized with different random seeds. The code for replicating this paper is available at https://github.com/jabalazs/implicit_emotion.
IIIDYT at SemEval-2018 Task 3: Irony detection in English tweets
Apr 22, 2018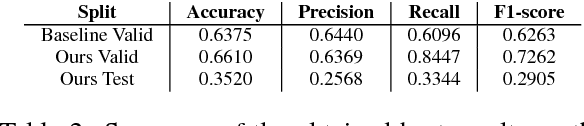
In this paper we introduce our system for the task of Irony detection in English tweets, a part of SemEval 2018. We propose representation learning approach that relies on a multi-layered bidirectional LSTM, without using external features that provide additional semantic information. Although our model is able to outperform the baseline in the validation set, our results show limited generalization power over the test set. Given the limited size of the dataset, we think the usage of more pre-training schemes would greatly improve the obtained results.
Mining fine-grained opinions on closed captions of YouTube videos with an attention-RNN
Aug 08, 2017


Video reviews are the natural evolution of written product reviews. In this paper we target this phenomenon and introduce the first dataset created from closed captions of YouTube product review videos as well as a new attention-RNN model for aspect extraction and joint aspect extraction and sentiment classification. Our model provides state-of-the-art performance on aspect extraction without requiring the usage of hand-crafted features on the SemEval ABSA corpus, while it outperforms the baseline on the joint task. In our dataset, the attention-RNN model outperforms the baseline for both tasks, but we observe important performance drops for all models in comparison to SemEval. These results, as well as further experiments on domain adaptation for aspect extraction, suggest that differences between speech and written text, which have been discussed extensively in the literature, also extend to the domain of product reviews, where they are relevant for fine-grained opinion mining.
Refining Raw Sentence Representations for Textual Entailment Recognition via Attention
Jul 12, 2017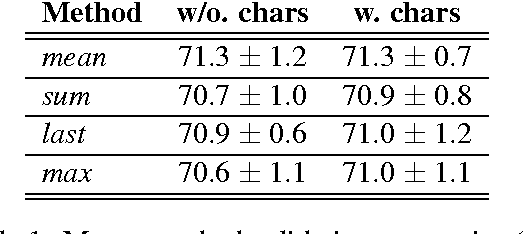


In this paper we present the model used by the team Rivercorners for the 2017 RepEval shared task. First, our model separately encodes a pair of sentences into variable-length representations by using a bidirectional LSTM. Later, it creates fixed-length raw representations by means of simple aggregation functions, which are then refined using an attention mechanism. Finally it combines the refined representations of both sentences into a single vector to be used for classification. With this model we obtained test accuracies of 72.057% and 72.055% in the matched and mismatched evaluation tracks respectively, outperforming the LSTM baseline, and obtaining performances similar to a model that relies on shared information between sentences (ESIM). When using an ensemble both accuracies increased to 72.247% and 72.827% respectively.