Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep contextualized word representations for detecting sarcasm and irony
Paper and Code
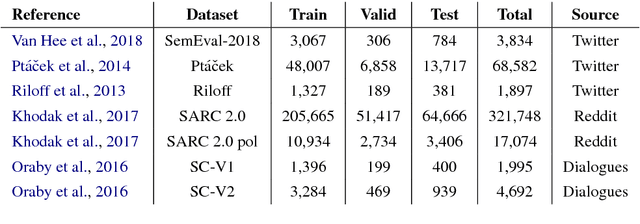
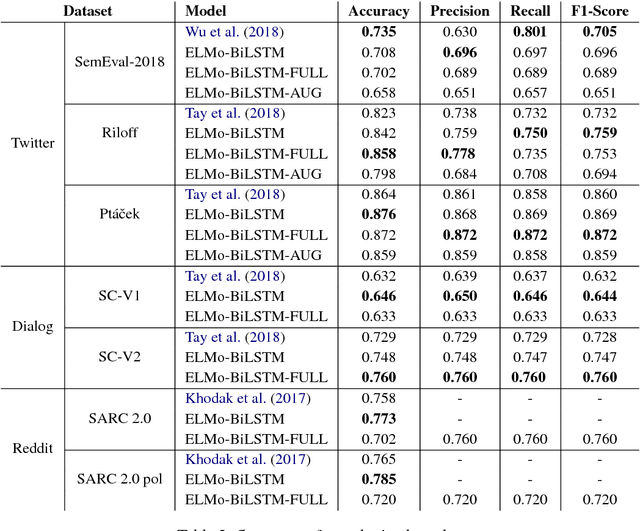
Predicting context-dependent and non-literal utterances like sarcastic and ironic expressions still remains a challenging task in NLP, as it goes beyond linguistic patterns, encompassing common sense and shared knowledge as crucial components. To capture complex morpho-syntactic features that can usually serve as indicators for irony or sarcasm across dynamic contexts, we propose a model that uses character-level vector representations of words, based on ELMo. We test our model on 7 different datasets derived from 3 different data sources, providing state-of-the-art performance in 6 of them, and otherwise offering competitive results.
* To appear in WASSA 2018
View paper on