 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Documenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources
Jan 25, 2022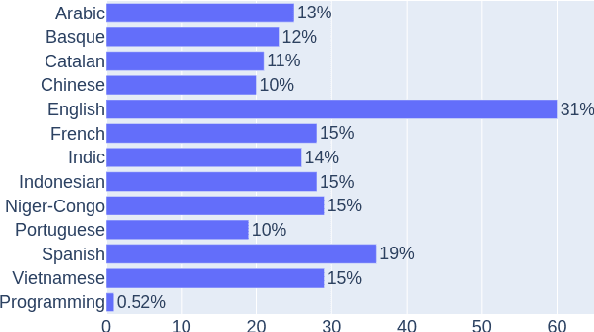
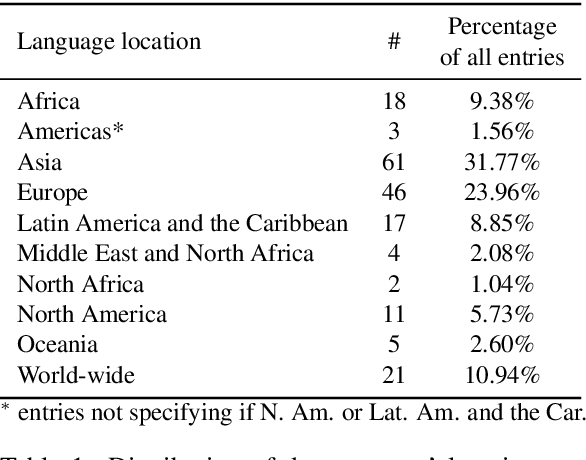
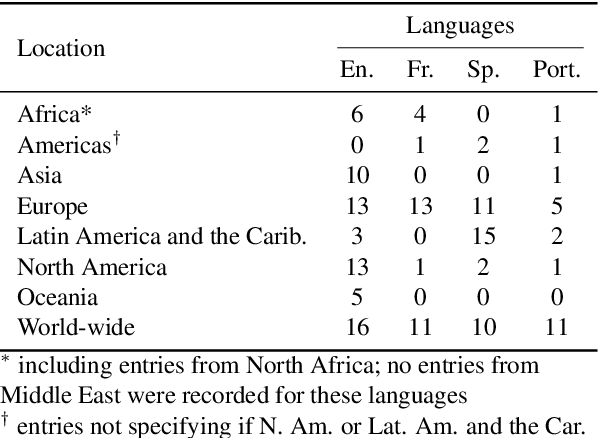
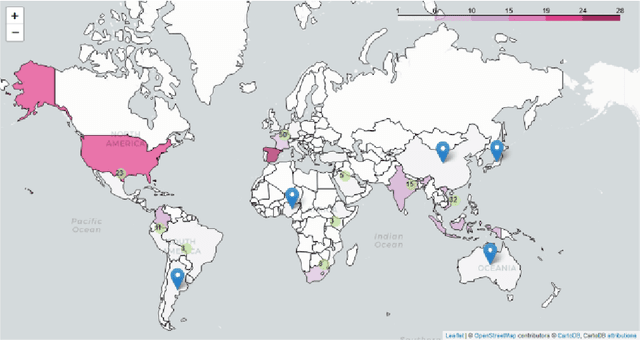
In recent years, large-scale data collection efforts have prioritized the amount of data collected in order to improve the modeling capabilities of large language models. This prioritization, however, has resulted in concerns with respect to the rights of data subjects represented in data collections, particularly when considering the difficulty in interrogating these collections due to insufficient documentation and tools for analysis. Mindful of these pitfalls, we present our methodology for a documentation-first, human-centered data collection project as part of the BigScience initiative. We identified a geographically diverse set of target language groups (Arabic, Basque, Chinese, Catalan, English, French, Indic languages, Indonesian, Niger-Congo languages, Portuguese, Spanish, and Vietnamese, as well as programming languages) for which to collect metadata on potential data sources. To structure this effort, we developed our online catalogue as a supporting tool for gathering metadata through organized public hackathons. We present our development process; analyses of the resulting resource metadata, including distributions over languages, regions, and resource types; and our lessons learned in this endeavor.
Quantized deep learning models on low-power edge devices for robotic systems
Nov 30, 2019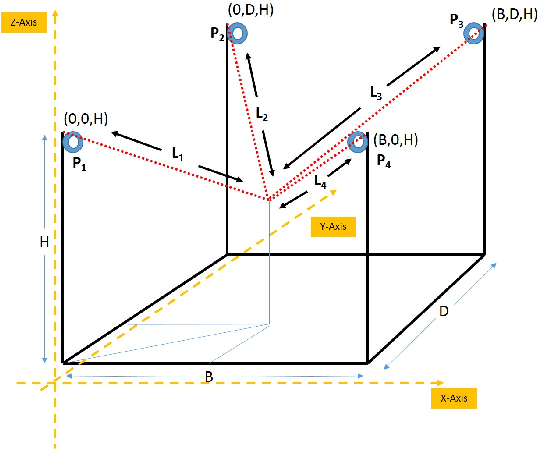
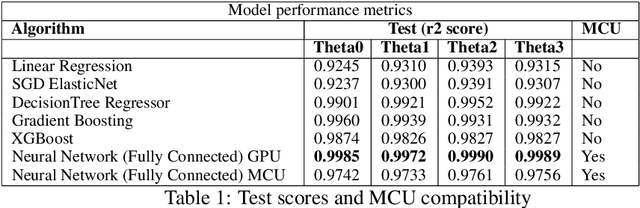
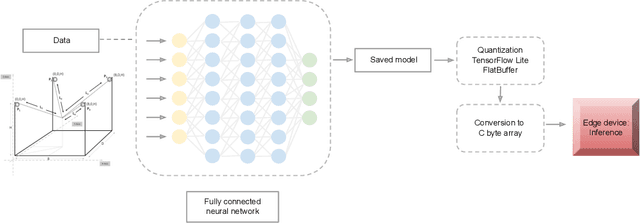
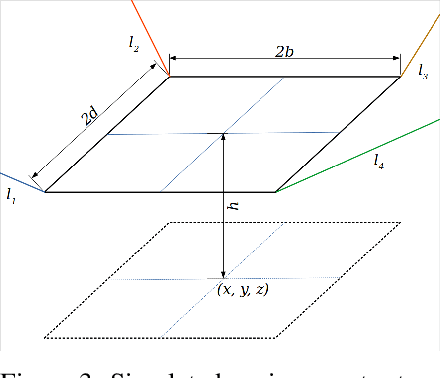
In this work, we present a quantized deep neural network deployed on a low-power edge device, inferring learned motor-movements of a suspended robot in a defined space. This serves as the fundamental building block for the original setup, a robotic system for farms or greenhouses aimed at a wide range of agricultural tasks. Deep learning on edge devices and its implications could have a substantial impact on farming systems in the developing world, leading not only to sustainable food production and income, but also increased data privacy and autonomy.
Creative GANs for generating poems, lyrics, and metaphors
Sep 20, 2019Generative models for text have substantially contributed to tasks like machine translation and language modeling, using maximum likelihood optimization (MLE). However, for creative text generation, where multiple outputs are possible and originality and uniqueness are encouraged, MLE falls short. Methods optimized for MLE lead to outputs that can be generic, repetitive and incoherent. In this work, we use a Generative Adversarial Network framework to alleviate this problem. We evaluate our framework on poetry, lyrics and metaphor datasets, each with widely different characteristics, and report better performance of our objective function over other generative models.
Designing dialogue systems: A mean, grumpy, sarcastic chatbot in the browser
Sep 20, 2019

In this work we explore a deep learning-based dialogue system that generates sarcastic and humorous responses from a conversation design perspective. We trained a seq2seq model on a carefully curated dataset of 3000 question-answering pairs, the core of our mean, grumpy, sarcastic chatbot. We show that end-to-end systems learn patterns very quickly from small datasets and thus, are able to transfer simple linguistic structures representing abstract concepts to unseen settings. We also deploy our LSTM-based encoder-decoder model in the browser, where users can directly interact with the chatbot. Human raters evaluated linguistic quality, creativity and human-like traits, revealing the system's strengths, limitations and potential for future research.
Deep contextualized word representations for detecting sarcasm and irony
Sep 26, 2018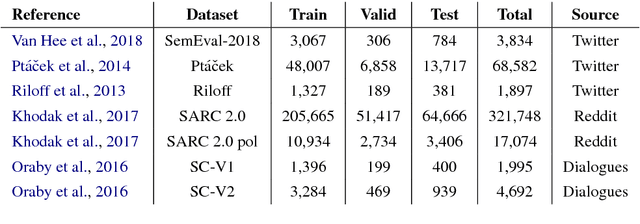
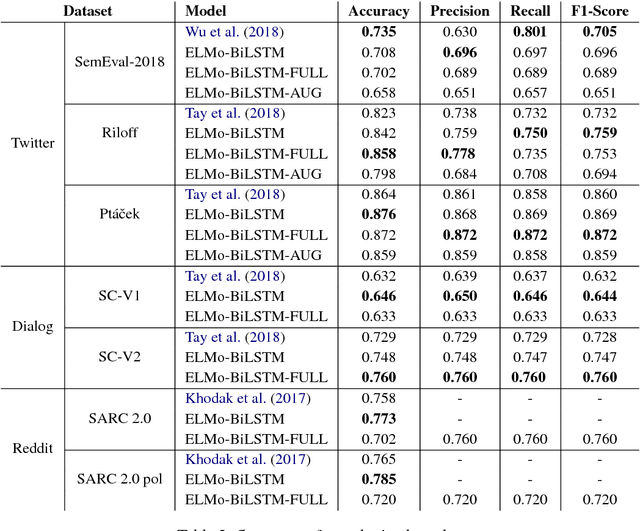
Predicting context-dependent and non-literal utterances like sarcastic and ironic expressions still remains a challenging task in NLP, as it goes beyond linguistic patterns, encompassing common sense and shared knowledge as crucial components. To capture complex morpho-syntactic features that can usually serve as indicators for irony or sarcasm across dynamic contexts, we propose a model that uses character-level vector representations of words, based on ELMo. We test our model on 7 different datasets derived from 3 different data sources, providing state-of-the-art performance in 6 of them, and otherwise offering competitive results.