 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Reliability of User-Centric Evaluation of Conversational Recommender Systems
Feb 19, 2026User-centric evaluation has become a key paradigm for assessing Conversational Recommender Systems (CRS), aiming to capture subjective qualities such as satisfaction, trust, and rapport. To enable scalable evaluation, recent work increasingly relies on third-party annotations of static dialogue logs by crowd workers or large language models. However, the reliability of this practice remains largely unexamined. In this paper, we present a large-scale empirical study investigating the reliability and structure of user-centric CRS evaluation on static dialogue transcripts. We collected 1,053 annotations from 124 crowd workers on 200 ReDial dialogues using the 18-dimensional CRS-Que framework. Using random-effects reliability models and correlation analysis, we quantify the stability of individual dimensions and their interdependencies. Our results show that utilitarian and outcome-oriented dimensions such as accuracy, usefulness, and satisfaction achieve moderate reliability under aggregation, whereas socially grounded constructs such as humanness and rapport are substantially less reliable. Furthermore, many dimensions collapse into a single global quality signal, revealing a strong halo effect in third-party judgments. These findings challenge the validity of single-annotator and LLM-based evaluation protocols and motivate the need for multi-rater aggregation and dimension reduction in offline CRS evaluation.
Overview of PAN 2026: Voight-Kampff Generative AI Detection, Text Watermarking, Multi-Author Writing Style Analysis, Generative Plagiarism Detection, and Reasoning Trajectory Detection
Feb 09, 2026The goal of the PAN workshop is to advance computational stylometry and text forensics via objective and reproducible evaluation. In 2026, we run the following five tasks: (1) Voight-Kampff Generative AI Detection, particularly in mixed and obfuscated authorship scenarios, (2) Text Watermarking, a new task that aims to find new and benchmark the robustness of existing text watermarking schemes, (3) Multi-author Writing Style Analysis, a continued task that aims to find positions of authorship change, (4) Generative Plagiarism Detection, a continued task that targets source retrieval and text alignment between generated text and source documents, and (5) Reasoning Trajectory Detection, a new task that deals with source detection and safety detection of LLM-generated or human-written reasoning trajectories. As in previous years, PAN invites software submissions as easy-to-reproduce Docker containers for most of the tasks. Since PAN 2012, more than 1,100 submissions have been made this way via the TIRA experimentation platform.
Unsupervised Graph Embeddings for Session-based Recommendation with Item Features
Feb 19, 2025In session-based recommender systems, predictions are based on the user's preceding behavior in the session. State-of-the-art sequential recommendation algorithms either use graph neural networks to model sessions in a graph or leverage the similarity of sessions by exploiting item features. In this paper, we combine these two approaches and propose a novel method, Graph Convolutional Network Extension (GCNext), which incorporates item features directly into the graph representation via graph convolutional networks. GCNext creates a feature-rich item co-occurrence graph and learns the corresponding item embeddings in an unsupervised manner. We show on three datasets that integrating GCNext into sequential recommendation algorithms significantly boosts the performance of nearest-neighbor methods as well as neural network models. Our flexible extension is easy to incorporate in state-of-the-art methods and increases the MRR@20 by up to 12.79%.
Support the Underground: Characteristics of Beyond-Mainstream Music Listeners
Feb 24, 2021
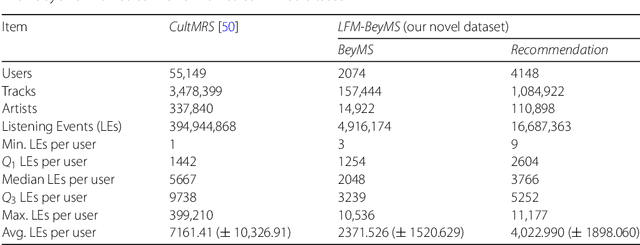
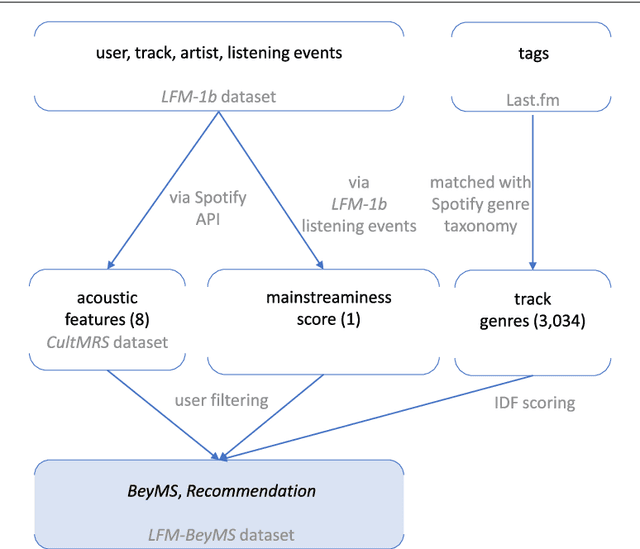

Music recommender systems have become an integral part of music streaming services such as Spotify and Last.fm to assist users navigating the extensive music collections offered by them. However, while music listeners interested in mainstream music are traditionally served well by music recommender systems, users interested in music beyond the mainstream (i.e., non-popular music) rarely receive relevant recommendations. In this paper, we study the characteristics of beyond-mainstream music and music listeners and analyze to what extent these characteristics impact the quality of music recommendations provided. Therefore, we create a novel dataset consisting of Last.fm listening histories of several thousand beyond-mainstream music listeners, which we enrich with additional metadata describing music tracks and music listeners. Our analysis of this dataset shows four subgroups within the group of beyond-mainstream music listeners that differ not only with respect to their preferred music but also with their demographic characteristics. Furthermore, we evaluate the quality of music recommendations that these subgroups are provided with four different recommendation algorithms where we find significant differences between the groups. Specifically, our results show a positive correlation between a subgroup's openness towards music listened to by members of other subgroups and recommendation accuracy. We believe that our findings provide valuable insights for developing improved user models and recommendation approaches to better serve beyond-mainstream music listeners.
Creative GANs for generating poems, lyrics, and metaphors
Sep 20, 2019Generative models for text have substantially contributed to tasks like machine translation and language modeling, using maximum likelihood optimization (MLE). However, for creative text generation, where multiple outputs are possible and originality and uniqueness are encouraged, MLE falls short. Methods optimized for MLE lead to outputs that can be generic, repetitive and incoherent. In this work, we use a Generative Adversarial Network framework to alleviate this problem. We evaluate our framework on poetry, lyrics and metaphor datasets, each with widely different characteristics, and report better performance of our objective function over other generative models.