 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Agents: Balancing Multistakeholder Alignment in Multi-Agent Personalization Systems
May 04, 2026LLM agents are increasingly used for personalization due to their ability to communicate directly with users in natural language, integrate external knowledge bases, and negotiate with other (possibly human) agents. Especially in multistakeholder AI systems with multiple distinct objectives, LLM agents are used to independently optimize for each stakeholder's goals. Here, stakeholder alignment is essential to identify and map these goals to provide LLM agents with quantifiable objectives. Plus, the way in which the outputs of the LLM agents are aggregated is fundamental to ensuring fair outcomes for all agents and, therefore, stakeholders. In this work, we identify open research challenges and propose a conceptual framework for designing fair multi-agent multistakeholder personalization systems that balance competing stakeholder objectives. Our framework integrates (i) methods to align stakeholder objectives and LLM agents, (ii) aggregation strategies, e.g., based on social choice theory, to form fair collective decisions, and (iii) stakeholder-centric evaluation procedures for both individual and collective agent behavior. We showcase our framework through a tourism use case and discuss possible applications in other domains, such as education and healthcare. Finally, we discuss domain-specific fairness tensions and review datasets for evaluating multistakeholder fairness and multi-agent personalization systems.
What Do Humanities Scholars Need? A User Model for Recommendation in Digital Archives
Apr 02, 2026User models for recommender systems (RecSys) typically assume stable preferences, similarity-based relevance, and session-bounded interactions -- assumptions derived from high-volume consumer contexts. This paper investigates these assumptions for humanities scholars working with digital archives. Following a human-centered design approach, we conducted focus groups and analyzed interview data from 18 researchers. Our analysis identifies four dimensions where scholarly information-seeking diverges from common RecSys user modeling: (1) context volatility -- preferences shift with research tasks and domain expertise; (2) epistemic trust -- relevance depends on verifiable provenance; (3) contrastive seeking -- researchers seek items that challenge their current direction; and (4) strand continuity -- research spans long-term threads rather than discrete sessions. We discuss implications for user modeling and outline how these dimensions relate to collaborative filtering, content-based, and session-based recommendation. We propose these dimensions as a diagnostic framework applicable beyond archives to similar application domains where typical user modeling assumptions may not hold.
Private and Fair Machine Learning: Revisiting the Disparate Impact of Differentially Private SGD
Oct 02, 2025Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.
Impacts of Mainstream-Driven Algorithms on Recommendations for Children Across Domains: A Reproducibility Study
Jul 09, 2025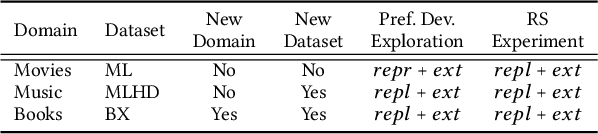
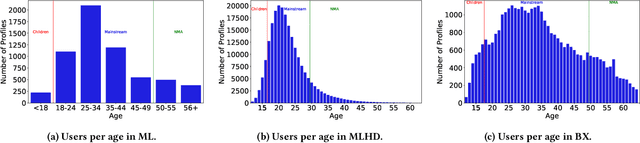

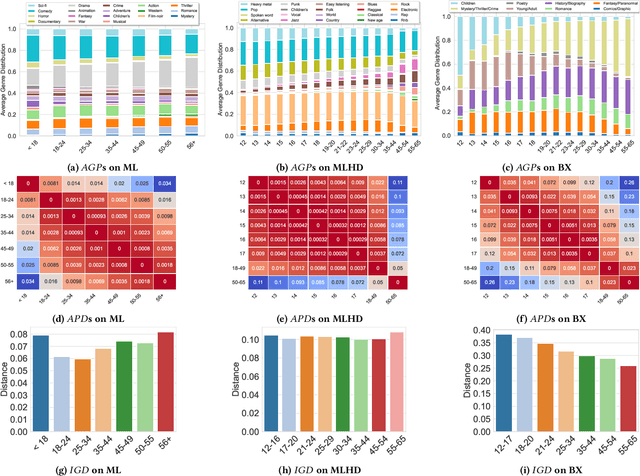
Children are often exposed to items curated by recommendation algorithms. Yet, research seldom considers children as a user group, and when it does, it is anchored on datasets where children are underrepresented, risking overlooking their interests, favoring those of the majority, i.e., mainstream users. Recently, Ungruh et al. demonstrated that children's consumption patterns and preferences differ from those of mainstream users, resulting in inconsistent recommendation algorithm performance and behavior for this user group. These findings, however, are based on two datasets with a limited child user sample. We reproduce and replicate this study on a wider range of datasets in the movie, music, and book domains, uncovering interaction patterns and aspects of child-recommender interactions consistent across domains, as well as those specific to some user samples in the data. We also extend insights from the original study with popularity bias metrics, given the interpretation of results from the original study. With this reproduction and extension, we uncover consumption patterns and differences between age groups stemming from intrinsic differences between children and others, and those unique to specific datasets or domains.
Hybrid Personalization Using Declarative and Procedural Memory Modules of the Cognitive Architecture ACT-R
May 08, 2025Recommender systems often rely on sub-symbolic machine learning approaches that operate as opaque black boxes. These approaches typically fail to account for the cognitive processes that shape user preferences and decision-making. In this vision paper, we propose a hybrid user modeling framework based on the cognitive architecture ACT-R that integrates symbolic and sub-symbolic representations of human memory. Our goal is to combine ACT-R's declarative memory, which is responsible for storing symbolic chunks along sub-symbolic activations, with its procedural memory, which contains symbolic production rules. This integration will help simulate how users retrieve past experiences and apply decision-making strategies. With this approach, we aim to provide more transparent recommendations, enable rule-based explanations, and facilitate the modeling of cognitive biases. We argue that our approach has the potential to inform the design of a new generation of human-centered, psychology-informed recommender systems.
Investigating Popularity Bias Amplification in Recommender Systems Employed in the Entertainment Domain
Apr 07, 2025
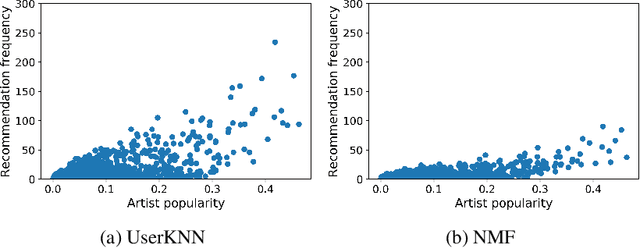
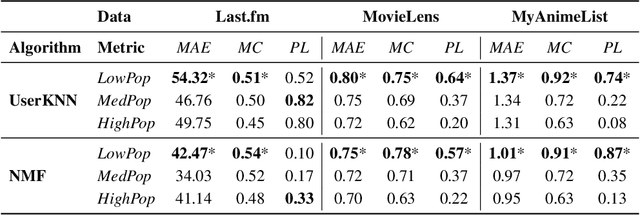
Recommender systems have become an integral part of our daily online experience by analyzing past user behavior to suggest relevant content in entertainment domains such as music, movies, and books. Today, they are among the most widely used applications of AI and machine learning. Consequently, regulations and guidelines for trustworthy AI, such as the European AI Act, which addresses issues like bias and fairness, are highly relevant to the design, development, and evaluation of recommender systems. One particularly important type of bias in this context is popularity bias, which results in the unfair underrepresentation of less popular content in recommendation lists. This work summarizes our research on investigating the amplification of popularity bias in recommender systems within the entertainment sector. Analyzing datasets from three entertainment domains, music, movies, and anime, we demonstrate that an item's recommendation frequency is positively correlated with its popularity. As a result, user groups with little interest in popular content receive less accurate recommendations compared to those who prefer widely popular items. Furthermore, we aim to better understand the connection between recommendation accuracy, calibration quality of algorithms, and popularity bias amplification.
De-centering the (Traditional) User: Multistakeholder Evaluation of Recommender Systems
Jan 09, 2025



Multistakeholder recommender systems are those that account for the impacts and preferences of multiple groups of individuals, not just the end users receiving recommendations. Due to their complexity, evaluating these systems cannot be restricted to the overall utility of a single stakeholder, as is often the case of more mainstream recommender system applications. In this article, we focus our discussion on the intricacies of the evaluation of multistakeholder recommender systems. We bring attention to the different aspects involved in the evaluation of multistakeholder recommender systems - from the range of stakeholders involved (including but not limited to producers and consumers) to the values and specific goals of each relevant stakeholder. Additionally, we discuss how to move from theoretical principles to practical implementation, providing specific use case examples. Finally, we outline open research directions for the RecSys community to explore. We aim to provide guidance to researchers and practitioners about how to think about these complex and domain-dependent issues of evaluation in the course of designing, developing, and researching applications with multistakeholder aspects.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024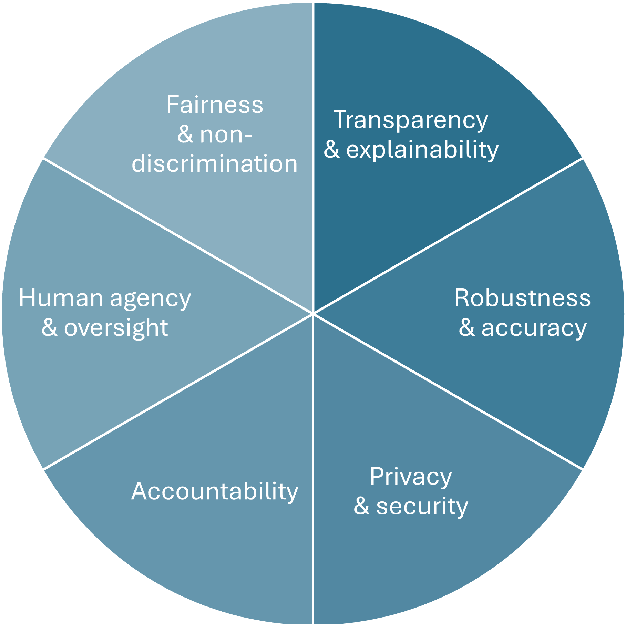


Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
Challenges in Implementing a Recommender System for Historical Research in the Humanities
Oct 28, 2024
This extended abstract describes the challenges in implementing recommender systems for digital archives in the humanities, focusing on Monasterium.net, a platform for historical legal documents. We discuss three key aspects: (i) the unique characteristics of so-called charters as items for recommendation, (ii) the complex multi-stakeholder environment, and (iii) the distinct information-seeking behavior of scholars in the humanities. By examining these factors, we aim to contribute to the development of more effective and tailored recommender systems for (digital) humanities research.
Value Identification in Multistakeholder Recommender Systems for Humanities and Historical Research: The Case of the Digital Archive Monasterium.net
Sep 26, 2024Recommender systems remain underutilized in humanities and historical research, despite their potential to enhance the discovery of cultural records. This paper offers an initial value identification of the multiple stakeholders that might be impacted by recommendations in Monasterium.net, a digital archive for historical legal documents. Specifically, we discuss the diverse values and objectives of its stakeholders, such as editors, aggregators, platform owners, researchers, publishers, and funding agencies. These in-depth insights into the potentially conflicting values of stakeholder groups allow designing and adapting recommender systems to enhance their usefulness for humanities and historical research. Additionally, our findings will support deeper engagement with additional stakeholders to refine value models and evaluation metrics for recommender systems in the given domains. Our conclusions are embedded in and applicable to other digital archives and a broader cultural heritage context.