 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024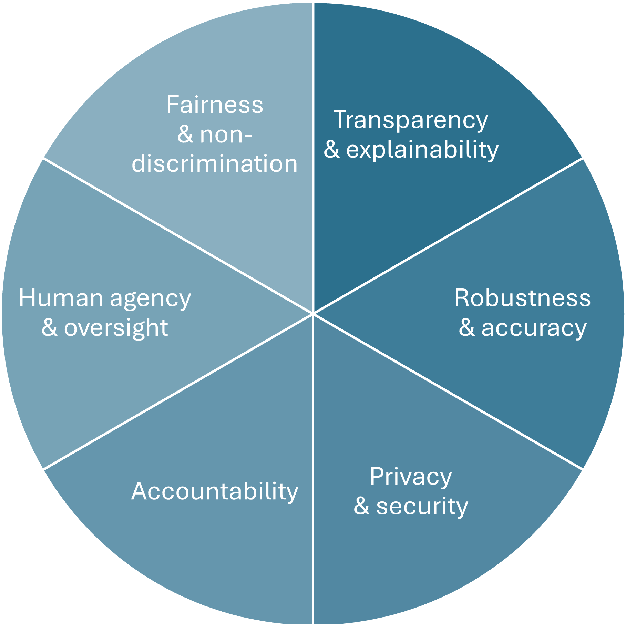


Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
A conceptual model for leaving the data-centric approach in machine learning
Feb 07, 2023

For a long time, machine learning (ML) has been seen as the abstract problem of learning relationships from data independent of the surrounding settings. This has recently been challenged, and methods have been proposed to include external constraints in the machine learning models. These methods usually come from application-specific fields, such as de-biasing algorithms in the field of fairness in ML or physical constraints in the fields of physics and engineering. In this paper, we present and discuss a conceptual high-level model that unifies these approaches in a common language. We hope that this will enable and foster exchange between the different fields and their different methods for including external constraints into ML models, and thus leaving purely data-centric approaches.
Real-world-robustness of tree-based classifiers
Aug 22, 2022



The concept of trustworthy AI has gained widespread attention lately. One of the aspects relevant to trustworthy AI is robustness of ML models. In this study, we show how to compute the recently introduced measure of real-world-robustness - a measure for robustness against naturally occurring distortions of input data - for tree-based classifiers. The original method for computing real-world-robustness works for all black box classifiers, but is only an approximation. Here we show how real-world-robustness, under the assumption that the natural distortions are given by multivariate normal distributions, can be exactly computed for tree-based classifiers.
Long-term dynamics of fairness: understanding the impact of data-driven targeted help on job seekers
Aug 17, 2022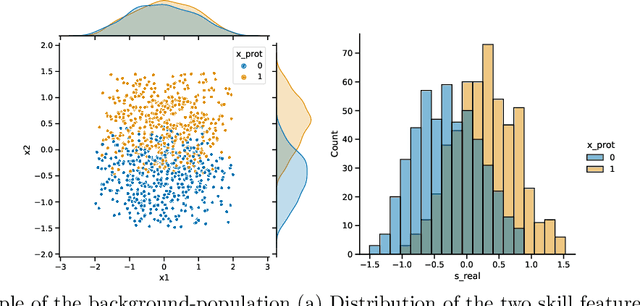
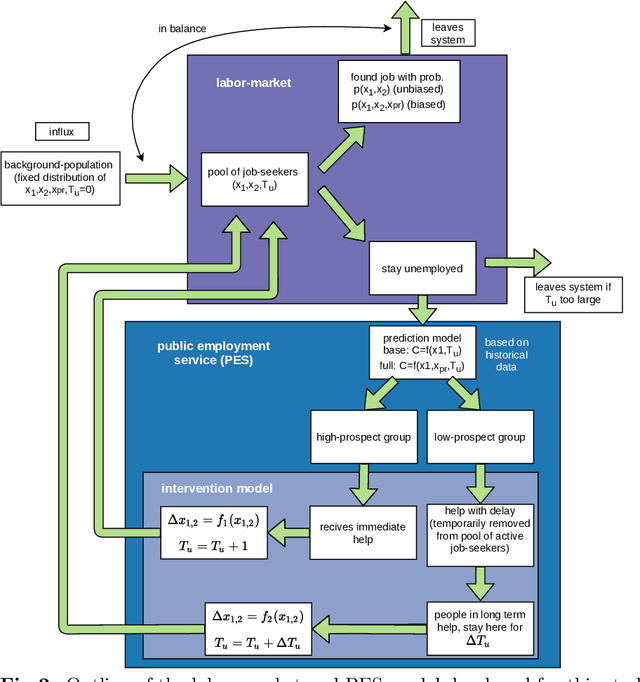
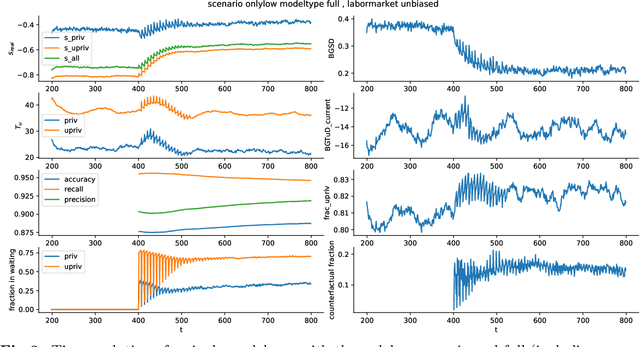
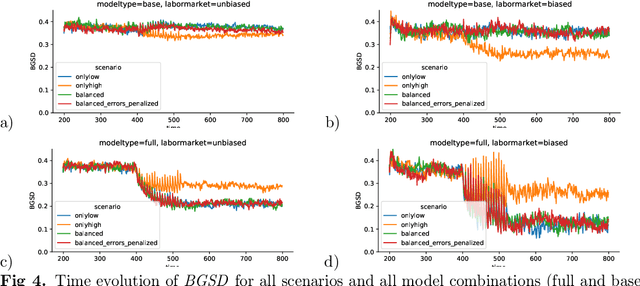
The use of data-driven decision support by public agencies is becoming more widespread and already influences the allocation of public resources. This raises ethical concerns, as it has adversely affected minorities and historically discriminated groups. In this paper, we use an approach that combines statistics and machine learning with dynamical modeling to assess long-term fairness effects of labor market interventions. Specifically, we develop and use a model to investigate the impact of decisions caused by a public employment authority that selectively supports job-seekers through targeted help. The selection of who receives what help is based on a data-driven intervention model that estimates an individual's chances of finding a job in a timely manner and is based on data that describes a population in which skills relevant to the labor market are unevenly distributed between two groups (e.g., males and females). The intervention model has incomplete access to the individual's actual skills and can augment this with knowledge of the individual's group affiliation, thus using a protected attribute to increase predictive accuracy. We assess this intervention model's dynamics -- especially fairness-related issues and trade-offs between different fairness goals -- over time and compare it to an intervention model that does not use group affiliation as a predictive feature. We conclude that in order to quantify the trade-off correctly and to assess the long-term fairness effects of such a system in the real-world, careful modeling of the surrounding labor market is indispensable.
Robustness of Machine Learning Models Beyond Adversarial Attacks
Apr 21, 2022
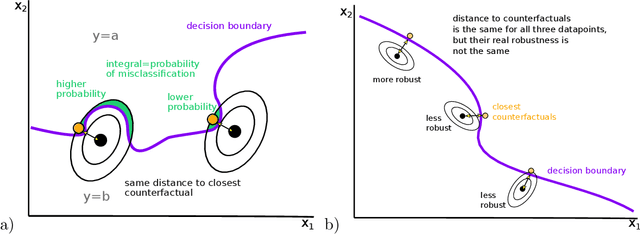

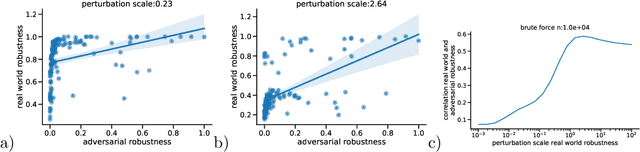
Correctly quantifying the robustness of machine learning models is a central aspect in judging their suitability for specific tasks, and thus, ultimately, for generating trust in the models. We show that the widely used concept of adversarial robustness and closely related metrics based on counterfactuals are not necessarily valid metrics for determining the robustness of ML models against perturbations that occur "naturally", outside specific adversarial attack scenarios. Additionally, we argue that generic robustness metrics in principle are insufficient for determining real-world-robustness. Instead we propose a flexible approach that models possible perturbations in input data individually for each application. This is then combined with a probabilistic approach that computes the likelihood that a real-world perturbation will change a prediction, thus giving quantitative information of the robustness of the trained machine learning model. The method does not require access to the internals of the classifier and thus in principle works for any black-box model. It is, however, based on Monte-Carlo sampling and thus only suited for input spaces with small dimensions. We illustrate our approach on two dataset, as well as on analytically solvable cases. Finally, we discuss ideas on how real-world robustness could be computed or estimated in high-dimensional input spaces.
Ensemble neural network forecasts with singular value decomposition
Feb 13, 2020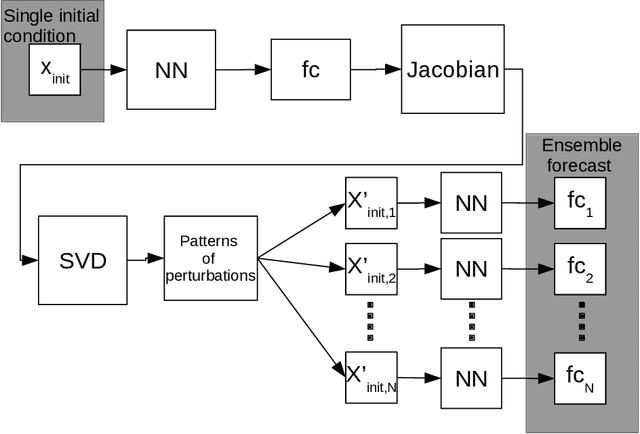



Ensemble weather forecasts enable a measure of uncertainty to be attached to each forecast by computing the ensemble's spread. However, generating an ensemble with a good error-spread relationship is far from trivial, and a wide range of approaches to achieve this have been explored. Random perturbations of the initial model state typically provide unsatisfactory results when applied to numerical weather prediction models. Singular value decomposition has proved more successful in this context, and as a result has been widely used for creating perturbed initial states of weather prediction models. We demonstrate how to apply the technique of singular value decomposition to purely neural-network based forecasts. Additionally, we explore the use of random initial perturbations for neural network ensembles, and the creation of neural network ensembles via retraining the network. We find that the singular value decomposition results in ensemble forecasts that have some probabilistic skill, but are inferior to the ensemble created by retraining the neural network several times. Compared to random initial perturbations, the singular value technique performs better when forecasting a simple general circulation model, comparably when forecasting atmospheric reanalysis data, and worse when forecasting the lorenz95 system - a highly idealized model designed to mimic certain aspects of the mid-latitude atmosphere.
WeatherBench: A benchmark dataset for data-driven weather forecasting
Feb 12, 2020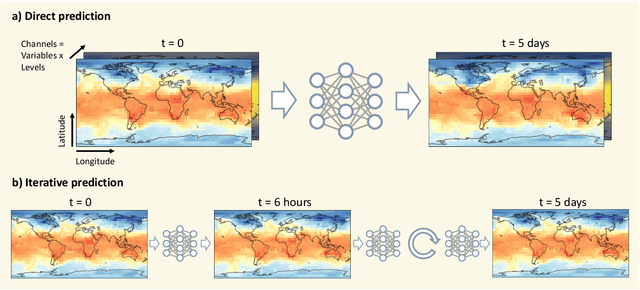
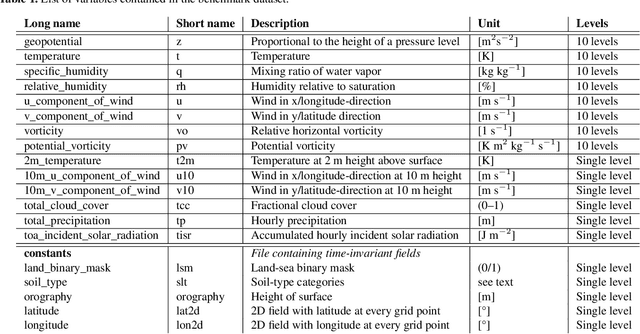
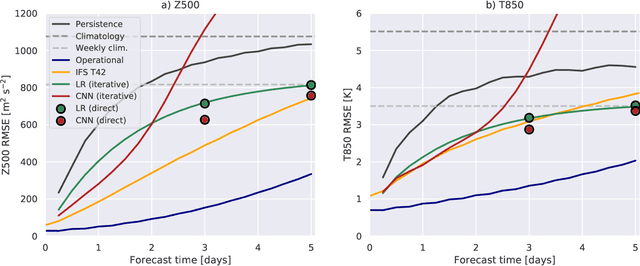

Data-driven approaches, most prominently deep learning, have become powerful tools for prediction in many domains. A natural question to ask is whether data-driven methods could also be used for numerical weather prediction. First studies show promise but the lack of a common dataset and evaluation metrics make inter-comparison between studies difficult. Here we present a benchmark dataset for data-driven medium-range weather forecasting, a topic of high scientific interest for atmospheric and computer scientists alike. We provide data derived from the ERA5 archive that has been processed to facilitate the use in machine learning models. We propose a simple and clear evaluation metric which will enable a direct comparison between different methods. Further, we provide baseline scores from simple linear regression techniques, deep learning models as well as purely physical forecasting models. All data is publicly available at https://mediatum.ub.tum.de/1524895 and the companion code is reproducible with tutorials for getting started. We hope that this dataset will accelerate research in data-driven weather forecasting.