 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Fair Machine Learning: Revisiting the Disparate Impact of Differentially Private SGD
Oct 02, 2025Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.
Recent Advances of Differential Privacy in Centralized Deep Learning: A Systematic Survey
Sep 28, 2023



Differential Privacy has become a widely popular method for data protection in machine learning, especially since it allows formulating strict mathematical privacy guarantees. This survey provides an overview of the state-of-the-art of differentially private centralized deep learning, thorough analyses of recent advances and open problems, as well as a discussion of potential future developments in the field. Based on a systematic literature review, the following topics are addressed: auditing and evaluation methods for private models, improvements of privacy-utility trade-offs, protection against a broad range of threats and attacks, differentially private generative models, and emerging application domains.
A conceptual model for leaving the data-centric approach in machine learning
Feb 07, 2023

For a long time, machine learning (ML) has been seen as the abstract problem of learning relationships from data independent of the surrounding settings. This has recently been challenged, and methods have been proposed to include external constraints in the machine learning models. These methods usually come from application-specific fields, such as de-biasing algorithms in the field of fairness in ML or physical constraints in the fields of physics and engineering. In this paper, we present and discuss a conceptual high-level model that unifies these approaches in a common language. We hope that this will enable and foster exchange between the different fields and their different methods for including external constraints into ML models, and thus leaving purely data-centric approaches.
Long-term dynamics of fairness: understanding the impact of data-driven targeted help on job seekers
Aug 17, 2022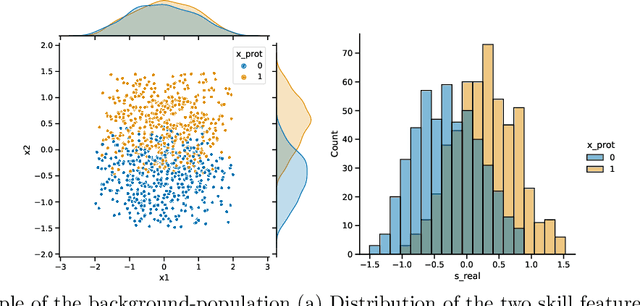
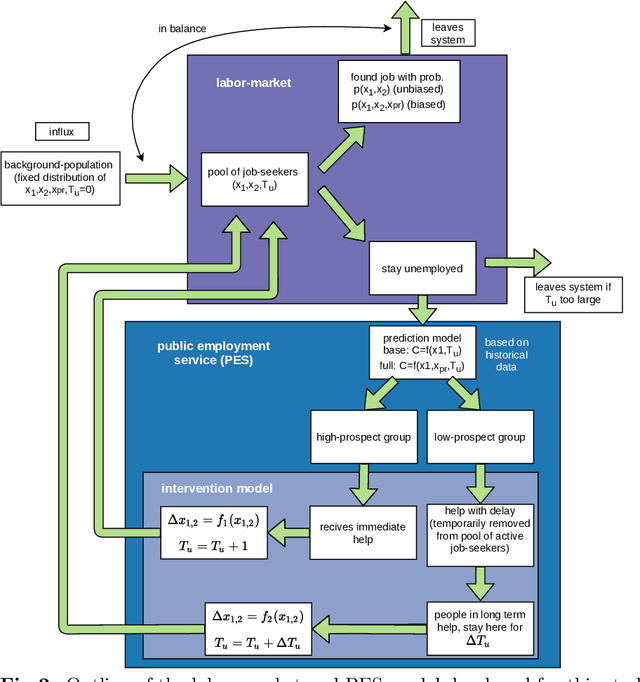
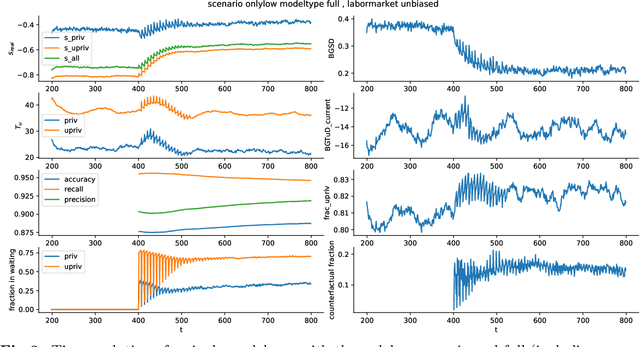
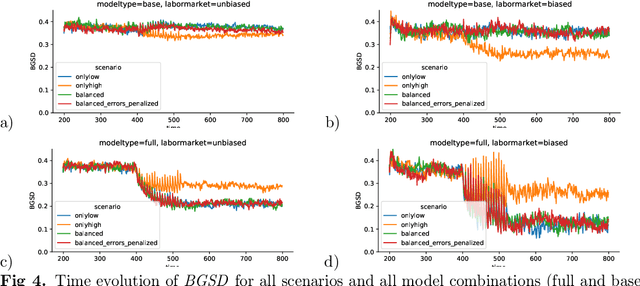
The use of data-driven decision support by public agencies is becoming more widespread and already influences the allocation of public resources. This raises ethical concerns, as it has adversely affected minorities and historically discriminated groups. In this paper, we use an approach that combines statistics and machine learning with dynamical modeling to assess long-term fairness effects of labor market interventions. Specifically, we develop and use a model to investigate the impact of decisions caused by a public employment authority that selectively supports job-seekers through targeted help. The selection of who receives what help is based on a data-driven intervention model that estimates an individual's chances of finding a job in a timely manner and is based on data that describes a population in which skills relevant to the labor market are unevenly distributed between two groups (e.g., males and females). The intervention model has incomplete access to the individual's actual skills and can augment this with knowledge of the individual's group affiliation, thus using a protected attribute to increase predictive accuracy. We assess this intervention model's dynamics -- especially fairness-related issues and trade-offs between different fairness goals -- over time and compare it to an intervention model that does not use group affiliation as a predictive feature. We conclude that in order to quantify the trade-off correctly and to assess the long-term fairness effects of such a system in the real-world, careful modeling of the surrounding labor market is indispensable.
Robustness of Machine Learning Models Beyond Adversarial Attacks
Apr 21, 2022
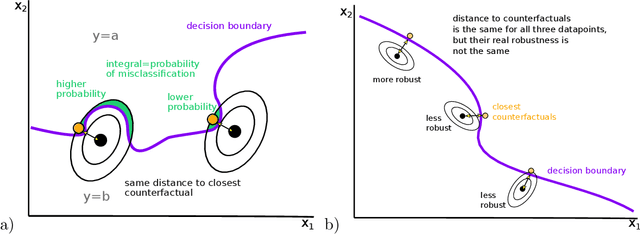

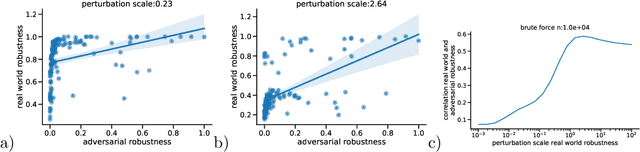
Correctly quantifying the robustness of machine learning models is a central aspect in judging their suitability for specific tasks, and thus, ultimately, for generating trust in the models. We show that the widely used concept of adversarial robustness and closely related metrics based on counterfactuals are not necessarily valid metrics for determining the robustness of ML models against perturbations that occur "naturally", outside specific adversarial attack scenarios. Additionally, we argue that generic robustness metrics in principle are insufficient for determining real-world-robustness. Instead we propose a flexible approach that models possible perturbations in input data individually for each application. This is then combined with a probabilistic approach that computes the likelihood that a real-world perturbation will change a prediction, thus giving quantitative information of the robustness of the trained machine learning model. The method does not require access to the internals of the classifier and thus in principle works for any black-box model. It is, however, based on Monte-Carlo sampling and thus only suited for input spaces with small dimensions. We illustrate our approach on two dataset, as well as on analytically solvable cases. Finally, we discuss ideas on how real-world robustness could be computed or estimated in high-dimensional input spaces.