 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Data Trail: A Survey of Data Provenance, Transparency and Traceability in LLMs
Jan 19, 2026Large language models (LLMs) are deployed at scale, yet their training data life cycle remains opaque. This survey synthesizes research from the past ten years on three tightly coupled axes: (1) data provenance, (2) transparency, and (3) traceability, and three supporting pillars: (4) bias \& uncertainty, (5) data privacy, and (6) tools and techniques that operationalize them. A central contribution is a proposed taxonomy defining the field's domains and listing corresponding artifacts. Through analysis of 95 publications, this work identifies key methodologies concerning data generation, watermarking, bias measurement, data curation, data privacy, and the inherent trade-off between transparency and opacity.
Private and Fair Machine Learning: Revisiting the Disparate Impact of Differentially Private SGD
Oct 02, 2025Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.
Exploring Gender Bias in Large Language Models: An In-depth Dive into the German Language
Jul 22, 2025


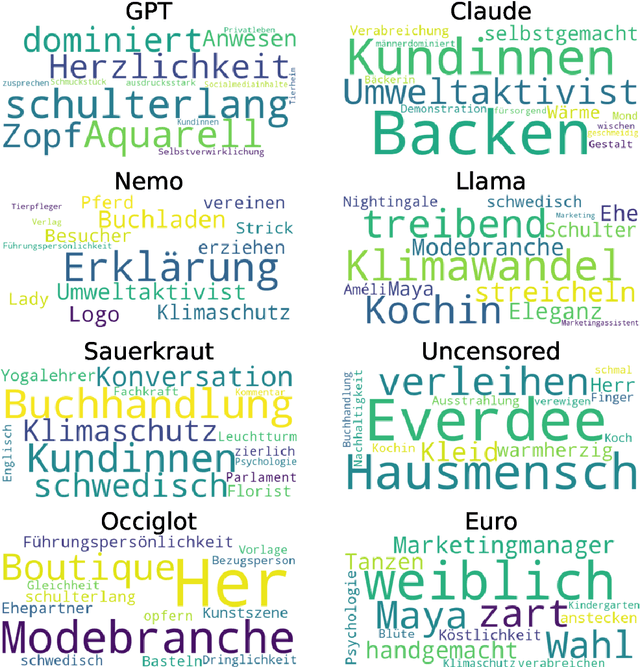
In recent years, various methods have been proposed to evaluate gender bias in large language models (LLMs). A key challenge lies in the transferability of bias measurement methods initially developed for the English language when applied to other languages. This work aims to contribute to this research strand by presenting five German datasets for gender bias evaluation in LLMs. The datasets are grounded in well-established concepts of gender bias and are accessible through multiple methodologies. Our findings, reported for eight multilingual LLM models, reveal unique challenges associated with gender bias in German, including the ambiguous interpretation of male occupational terms and the influence of seemingly neutral nouns on gender perception. This work contributes to the understanding of gender bias in LLMs across languages and underscores the necessity for tailored evaluation frameworks.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024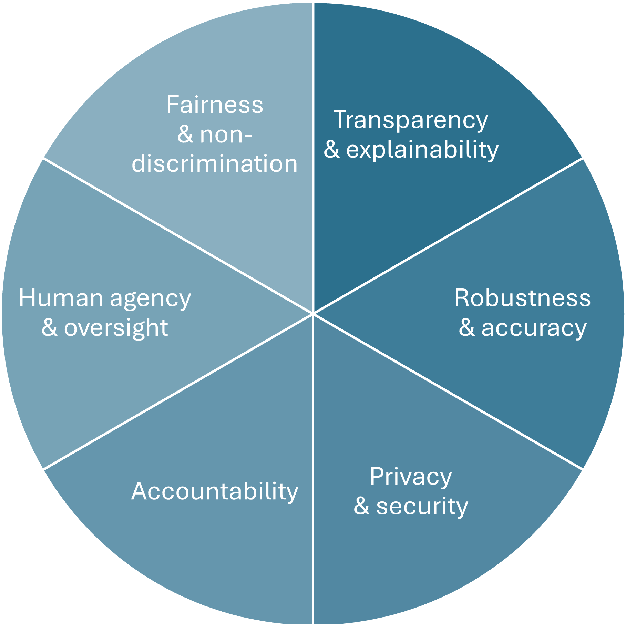


Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers
Jun 20, 2024Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises primarily due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identify the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) map the drivers to the barriers. With this work, we hope to provide insights and contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
Making Alice Appear Like Bob: A Probabilistic Preference Obfuscation Method For Implicit Feedback Recommendation Models
Jun 17, 2024Users' interaction or preference data used in recommender systems carry the risk of unintentionally revealing users' private attributes (e.g., gender or race). This risk becomes particularly concerning when the training data contains user preferences that can be used to infer these attributes, especially if they align with common stereotypes. This major privacy issue allows malicious attackers or other third parties to infer users' protected attributes. Previous efforts to address this issue have added or removed parts of users' preferences prior to or during model training to improve privacy, which often leads to decreases in recommendation accuracy. In this work, we introduce SBO, a novel probabilistic obfuscation method for user preference data designed to improve the accuracy--privacy trade-off for such recommendation scenarios. We apply SBO to three state-of-the-art recommendation models (i.e., BPR, MultVAE, and LightGCN) and two popular datasets (i.e., MovieLens-1M and LFM-2B). Our experiments reveal that SBO outperforms comparable approaches with respect to the accuracy--privacy trade-off. Specifically, we can reduce the leakage of users' protected attributes while maintaining on-par recommendation accuracy.
Reproducibility in Machine Learning-Driven Research
Jul 19, 2023
Research is facing a reproducibility crisis, in which the results and findings of many studies are difficult or even impossible to reproduce. This is also the case in machine learning (ML) and artificial intelligence (AI) research. Often, this is the case due to unpublished data and/or source-code, and due to sensitivity to ML training conditions. Although different solutions to address this issue are discussed in the research community such as using ML platforms, the level of reproducibility in ML-driven research is not increasing substantially. Therefore, in this mini survey, we review the literature on reproducibility in ML-driven research with three main aims: (i) reflect on the current situation of ML reproducibility in various research fields, (ii) identify reproducibility issues and barriers that exist in these research fields applying ML, and (iii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility. With this, we hope to contribute to decisions on the viability of different solutions for supporting ML reproducibility.
A conceptual model for leaving the data-centric approach in machine learning
Feb 07, 2023

For a long time, machine learning (ML) has been seen as the abstract problem of learning relationships from data independent of the surrounding settings. This has recently been challenged, and methods have been proposed to include external constraints in the machine learning models. These methods usually come from application-specific fields, such as de-biasing algorithms in the field of fairness in ML or physical constraints in the fields of physics and engineering. In this paper, we present and discuss a conceptual high-level model that unifies these approaches in a common language. We hope that this will enable and foster exchange between the different fields and their different methods for including external constraints into ML models, and thus leaving purely data-centric approaches.
Long-term dynamics of fairness: understanding the impact of data-driven targeted help on job seekers
Aug 17, 2022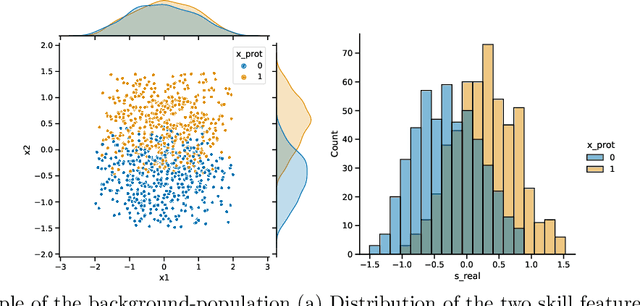
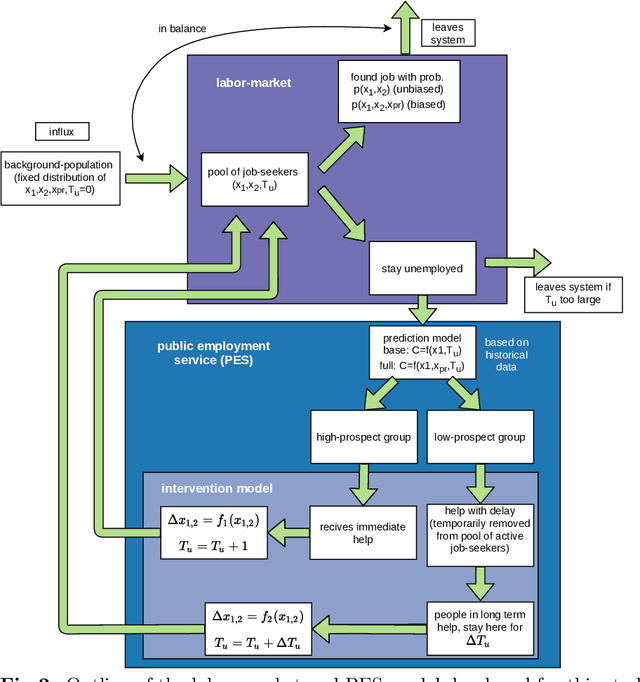
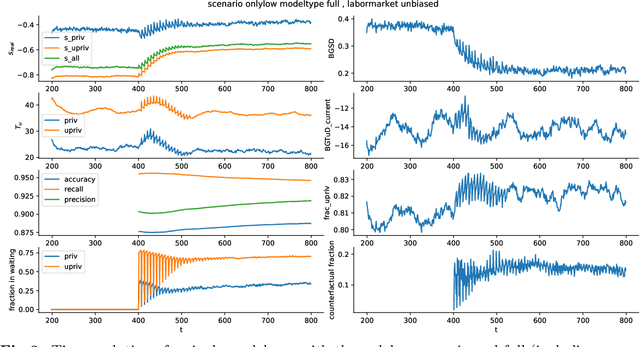
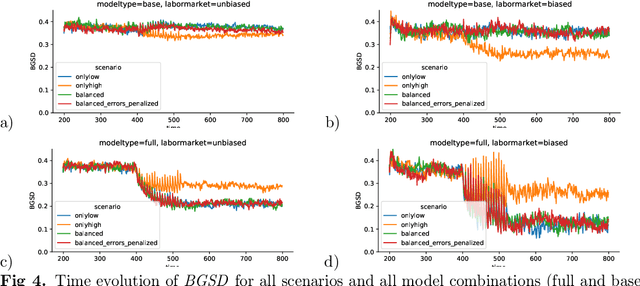
The use of data-driven decision support by public agencies is becoming more widespread and already influences the allocation of public resources. This raises ethical concerns, as it has adversely affected minorities and historically discriminated groups. In this paper, we use an approach that combines statistics and machine learning with dynamical modeling to assess long-term fairness effects of labor market interventions. Specifically, we develop and use a model to investigate the impact of decisions caused by a public employment authority that selectively supports job-seekers through targeted help. The selection of who receives what help is based on a data-driven intervention model that estimates an individual's chances of finding a job in a timely manner and is based on data that describes a population in which skills relevant to the labor market are unevenly distributed between two groups (e.g., males and females). The intervention model has incomplete access to the individual's actual skills and can augment this with knowledge of the individual's group affiliation, thus using a protected attribute to increase predictive accuracy. We assess this intervention model's dynamics -- especially fairness-related issues and trade-offs between different fairness goals -- over time and compare it to an intervention model that does not use group affiliation as a predictive feature. We conclude that in order to quantify the trade-off correctly and to assess the long-term fairness effects of such a system in the real-world, careful modeling of the surrounding labor market is indispensable.
Societal Biases in Retrieved Contents: Measurement Framework and Adversarial Mitigation for BERT Rankers
May 11, 2021

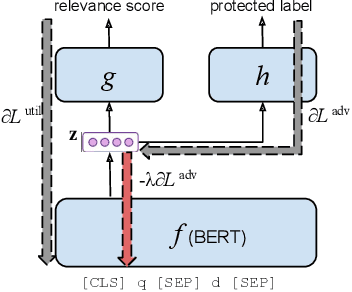
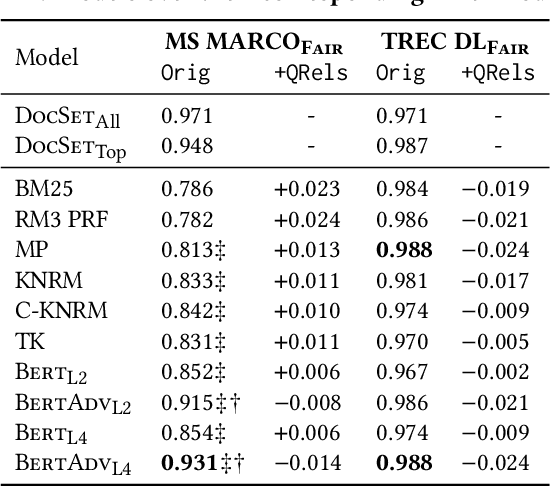
Societal biases resonate in the retrieved contents of information retrieval (IR) systems, resulting in reinforcing existing stereotypes. Approaching this issue requires established measures of fairness in respect to the representation of various social groups in retrieval results, as well as methods to mitigate such biases, particularly in the light of the advances in deep ranking models. In this work, we first provide a novel framework to measure the fairness in the retrieved text contents of ranking models. Introducing a ranker-agnostic measurement, the framework also enables the disentanglement of the effect on fairness of collection from that of rankers. To mitigate these biases, we propose AdvBert, a ranking model achieved by adapting adversarial bias mitigation for IR, which jointly learns to predict relevance and remove protected attributes. We conduct experiments on two passage retrieval collections (MSMARCO Passage Re-ranking and TREC Deep Learning 2019 Passage Re-ranking), which we extend by fairness annotations of a selected subset of queries regarding gender attributes. Our results on the MSMARCO benchmark show that, (1) all ranking models are less fair in comparison with ranker-agnostic baselines, and (2) the fairness of Bert rankers significantly improves when using the proposed AdvBert models. Lastly, we investigate the trade-off between fairness and utility, showing that we can maintain the significant improvements in fairness without any significant loss in utility.