 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Fair Machine Learning: Revisiting the Disparate Impact of Differentially Private SGD
Oct 02, 2025Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024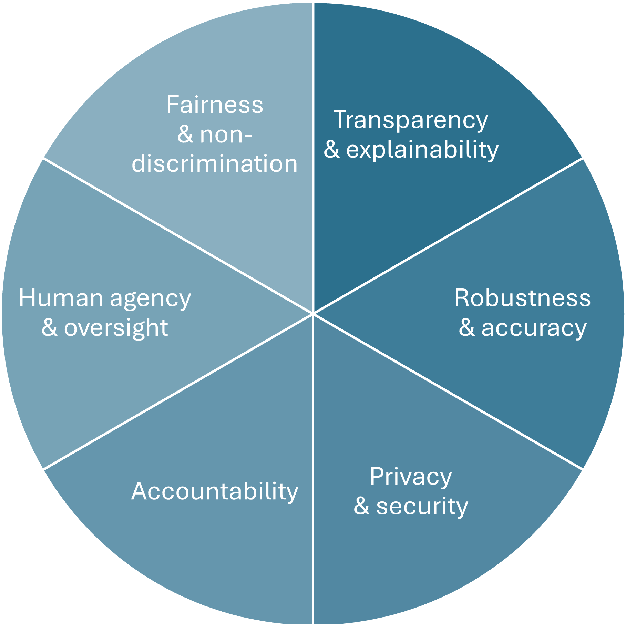


Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
Recent Advances of Differential Privacy in Centralized Deep Learning: A Systematic Survey
Sep 28, 2023



Differential Privacy has become a widely popular method for data protection in machine learning, especially since it allows formulating strict mathematical privacy guarantees. This survey provides an overview of the state-of-the-art of differentially private centralized deep learning, thorough analyses of recent advances and open problems, as well as a discussion of potential future developments in the field. Based on a systematic literature review, the following topics are addressed: auditing and evaluation methods for private models, improvements of privacy-utility trade-offs, protection against a broad range of threats and attacks, differentially private generative models, and emerging application domains.